
XMLサーバカタログ/2001 Summer
〜XMLデータベース編〜
2001/7/27
XMLに対応したサーバを紹介するこの特集。前回の「BtoBサーバ編」に続き、今度は「XMLデータベース編」をお届けする。ここでいう「XMLデータベース」とは、XML文書をストアする機能を備えたデータベースを指す。XML文書のストア機能は、いまや多くのデータベースが実装する機能となりつつある。ビジネスで取り交わされる文書の多くがXML化されようとしているからだ。
| リレーショナルか、それともXMLネイティブか |
| 紹介する製品 |
XML文書をデータベースに保存することで得られるメリットとは、第一に大量のXML文書の検索や追加、更新などが高速かつ容易になることだ。また、バックアップ機能やログの管理、レプリケーション機能などを備えたデータベースであれば、ハードウェアの故障などによる事故からも大事なデータを守ることができる。
特に、今後ビジネスでやりとりされる文書がXML化されるようになれば、大量のXML文書の保存と発行にともなう管理が必要となる。そうなれば、XML対応のデータベースは、現在のリレーショナルデータベースと同じように、重要なアプリケーションとなることは間違いないだろう。
現在のところ、XML文書をデータベースに保存する製品は、2つに大別できる。「XML文書をそのまま保存できるデータベース」と、「リレーショナル形式にマッピングして保存するデータベース」だ。それぞれがどういう特徴を持つのか、解説しよう。
XMLネイティブなデータベース
XML文書をそのまま、もしくは最小限の変換を行ったうえで保存し、完全にオリジナルなものと同じ状態で取り出せるデータベースを、ここでは広い意味で「XMLネイティブ」なデータベースと呼んでおこう。
XML文書をそのまま保存できるといっても、単にまるごと保存するだけではファイルシステム上に保存するのと変わらない。そこでXMLネイティブなデータベースでは、保存したXML文書に対してインデックス付けをしたり、DOMツリーに変換するなど、XML文書内の目的のデータを素早く検索、更新できるような工夫がされている。
インデックス方式は、XML文書と同時に、その文書構造に沿ったインデックスを付加して保存する方法だ。大規模なXML文書のデータベースになっても、インデックスのおかげで目的の部分をすばやく検索できる。また、データの変換動作がないため、XML文書の入出力が高速に行える。
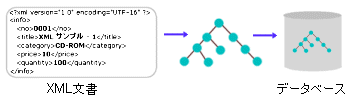 |
| XMLネイティブなデータベースでは、XML文書をツリー構造などに変換してそのまま格納する |
XML文書を変換する典型的な方法は、DOMツリーへの変換だ。あらゆるXML文書は、「ノード」に分解してツリー構造に組み変えることができる。これがDOMツリーである。そしてDOMツリーは、元のXML文書の情報を、構造も含めてそのまま保持しているため、DOMツリーから簡単に元のXML文書に戻すことができるし、ツリーをたどって目的のデータを探したり、ツリーの一部を取り出したり、ノードを書き換えたり追加することも容易に行える。
一般的に、XMLネイティブなデータベースの特徴は、XML文書の特徴を生かした管理ができることにある。つまり、XML文書が持つタグの情報を元にした検索や追加、削除、更新などが可能だったり、検索結果としてXML文書の任意の一部だけを取得できたり、XML文書の一部の更新や追加が可能といった機能を提供している。また、自由に任意の構造を持つXML文書を保存し、データベースに追加することができる。
その一方で、XMLネイティブなデータベースに決定的に欠けているのが、標準的な問い合わせ言語だ。リレーショナルデータベースには、「SQL」という、機能的にもほぼ完成された業界標準の問い合わせ言語がある。しかし現在のところ、XML文書とそのデータベースを対象にした問い合わせ言語の業界標準は存在しない(W3Cなどで検討はされている)。そのため、XMLデータベース製品ごとに問い合わせの方法が異なり、互換性もほとんどないのが現状である。
XMLネイティブなデータベースとしては、Tamino、eXcelon、Yggdrasilなどが挙げられる。
リレーショナルなデータベース
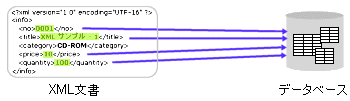 |
| リレーショナルデータベースでは、XML文書の一部をテーブルにマッピングさせて格納する |
もう一方の、XML文書をリレーショナル形式にマッピングして保存するデータベースは、XML文書の決められた部分を特定のテーブルの特定のフィールドのデータにマッピングすることで、XML文書の中のデータをデータベースに格納する機能を備えている。
マッピングの方法は製品によってさまざまだが、一般にXML文書の特定の要素(開始タグから終了タグまで)と、テーブルの特定の列を対応させて、XML文書の中からデータを取り出し、データベースへ格納させる、という方法をとる。また、同様の方法で、データベースに格納されているデータをXML文書に組み立てて出力する機能も持つ。リレーショナルデータベースでは、こうしたすでに格納されたデータをXML文書形式に加工して出力する方法に重点が置かれている製品がほとんどのようだ。
この場合、XML文書から特定の要素だけが抜き取られて保存されることになるため、元のXML文書の構造はいったん破棄される。XML文書には、漢字コードや名前空間の情報などが付加されているし、要素の前後関係や親子関係なども意味を持っているが、列にマッピングされて保存された段階で、こうした情報は失われてしまう。そのため、リレーショナルデータベースに格納された情報から元のXML文書を組み立てるには、こうした失われた情報を外部で保持しておき、組み立て時に補ってやるか、そもそもオリジナルと同一のXML文書を再現する必要のない利用形態を想定する必要がある。
現状では、BtoBのような用途でXML文書を利用してやりとりされるデータのほとんどが定型データであり、またXML文書も定型的な文書であるため、こうした利用法でも十分だと思われる。
リレーショナルデータベースにマッピングしてXML文書を保存する方法の特徴は、この「必要な要素だけを抜き出して保存する」点にある。保存後は通常のデータベースのデータとして扱えるため、高速なトランザクション処理、排他制御、バックアップ機能など、すでに実績を積んだリレーショナルデータベースの機能を利用できる。Oracle8i、IBM DB2 UDBなど著名なデータベース製品の多くは、こうしたXML文書とのマッピング機能を備えており、インフォテリアのiConnectorといった、マッピング専用のツールも存在する。
では、次ページからこうしたXML対応のデータベースを個別に紹介していこう。
|
| 4/6 | XMLネイティブ型 |
| Index | |
| XMLサーバカタログ/2001 Summer 〜BtoBサーバ編〜 |
|
| BtoBサーバに求められる3つの機能 | |
| XML/インターネット型、データベース型 Asteria/インフォテリア BizTalk Server 2000/マイクロソフト eXcelon B2B Integration Server/日本エクセロン コラム:XMLアクセラレータでBtoB通信を高速化 |
|
| EAI型、Webアプリケーションサーバ型 Ariba Buyer/アリバ Silver Stream xCommerce/テクマトリックス そのほか紹介できなかったBtoBサーバ |
|
| 〜XMLデータベース編〜 | |
| リレーショナルか、それともXMLネイティブか | |
| XMLネイティブ型 Tamino/ビーコンIT Yggdrasill/メディアフュージョン コラム:eXcelonとAsteriaのストアは何型? |
|
| リレーショナル型 Oracle8i DB2 UDB iConnector そのほかのデータベース製品 |
|
- QAフレームワーク:仕様ガイドラインが勧告に昇格 (2005/10/21)
データベースの急速なXML対応に後押しされてか、9月に入って「XQuery」や「XPath」に関係したドラフトが一気に11本も更新された - XML勧告を記述するXMLspecとは何か (2005/10/12)
「XML 1.0勧告」はXMLspec DTDで記述され、XSLTによって生成されている。これはXMLが本当に役立っている具体的な証である - 文字符号化方式にまつわるジレンマ (2005/9/13)
文字符号化方式(UTF-8、シフトJISなど)を自動検出するには、ニワトリと卵の関係にあるジレンマを解消する仕組みが必要となる - XMLキー管理仕様(XKMS 2.0)が勧告に昇格 (2005/8/16)
セキュリティ関連のXML仕様に進展あり。また、日本発の新しいXMLソフトウェアアーキテクチャ「xfy technology」の詳細も紹介する
|
|





