XMLデータの埋め込みと相互参照:XSLTスタイルシート書き方講座(応用編2)
前回の「スタイルシートをモジュール化する」では、モジュール化された複数のスタイルシートを取り込む方法を考えました。さて、スタイルシートだけでなく、XMLデータも複数のファイルを扱えると便利です。データベースから複数のXMLデータを読み込んで結合したり、必要なデータのみを選んで抽出することができれば、XMLデータの操作性はさらに向上することでしょう。今回は、複数のXMLデータを操作する方法と、相互参照機能を使って必要なデータのみを抽出する方法を説明します。
複数のXMLデータを組み合わせて処理する
XSLTプロセッサの基本的な処理の流れは、与えられた単一のXMLデータにスタイルシートを適用して構造変換を行うというものです。しかしマージ処理のように、複数のXMLデータを処理したいときがあるものです。例えば下図のように、メインのXMLデータにディテール・ファイル(詳細情報を持つファイル)の内容をさらに組み込めたら便利です。
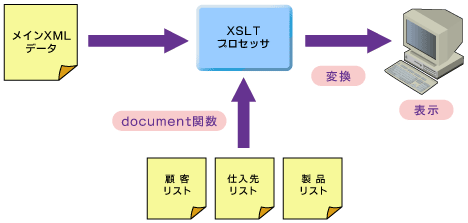 図1 複数のXMLデータを組み込む
図1 複数のXMLデータを組み込む大容量のXMLデータを作成するのではなく、図1のように細かくいくつかのファイルに切り分け、これらを組み合わせて使え、データの管理も処理も容易になります。実は、これを可能にしてくれるのがXSLTのdocument関数です。document関数は、最初に与えられるメインのXMLデータ以外のXMLデータを読み込んでくれます。
■document関数を使ってXMLデータを読み込む
document関数は次のように呼び出します。
document関数の使い方
node-set document(object, node-set?)
(返却値) (URI指定)(基底URI)
- 基本的に1番目の引数で読み込み対象のXMLデータのURIを指定します。2番目の引数がある場合、それは相対URIである1番目を絶対URIに変換するための基底URIです。
- 返却値は、読み込み対象のXMLデータのルートノードです。
document関数の2番目の引数について説明を補足します。もし1番目の引数が“customers.xml”のように相対URIの場合、document関数は読み込み対象のXMLデータを見つけ出すために基底URIを使って絶対URIへと変換する必要があります。そのために2番目の引数が使われます。次の例を見てください。
document("customers.xml","/")
メインのXMLデータのルートノード(/)が“ http://seminars.utj.co.jp/main.xml”という基底URIを持っているならば、customers.xmlは“http://seminars.utj.co.jp/customers.xml”という絶対URIに変換されます(図2)。
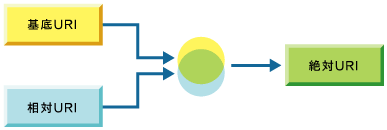 図2 基底URIで相対URIを絶対URIへ変換する
図2 基底URIで相対URIを絶対URIへ変換する例を使ってdocument関数の使用方法を示しましょう。リスト1に示すメインのXMLデータ“main.xml”と、リスト2に示す読み込み対象のXMLデータ“customers200110.xml”を使って新規顧客表を作成して、Webブラウザに表示するとします。
<?xml version="1.0" encoding="shift_jis"?> <?xml:stylesheet type="text/xsl" href="tboutput.xsl"?> <customers_list> <title>新規登録顧客リスト(10月分)</title> <tbl href="customers200110.xml"/> </customers_list>
<?xml version="1.0" encoding="shift_jis"?>
<customers>
<customer id="c001">
<name>秋本太郎</name>
<addr>港区麻布狸穴町A-A-A</addr>
<area>関東</area>
</customer>
<customer id="c002">
<name>加藤花子</name>
<addr>横浜市金沢区乙舳B-B-B</addr>
<area>関東</area>
</customer>
<customer id="c003">
<name>佐々木次郎</name>
<addr>大阪市鶴見区放出東C-C-C</addr>
<area>近畿</area>
</customer>
<customer id="c004">
<name>田中良子</name>
<addr>浦添市勢理客D-D-D</addr>
<area>沖縄</area>
</customer>
</customers>
適用するスタイルシート“tboutput.xsl”をリスト3に示します。
<?xml version="1.0" encoding="Shift_jis"?>
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:template match="/">
<html>
<body>
<xsl:apply-templates/>
</body>
</html>
</xsl:template>
<xsl:template match="customers_list">
<xsl:apply-templates select="title"/>
<xsl:apply-templates select="tbl"/>
</xsl:template>
<xsl:template match="title">
<h3><xsl:value-of select="."/></h3>
</xsl:template>
<xsl:template match="tbl">
<table border="3">
<tr>
<th>お名前</th>
<th>ご住所</th>
</tr>
<xsl:variable name="t" select="document(@href)"/>
<xsl:for-each select="$t//customer">
<tr>
<td><xsl:value-of select="name"/></td>
<td><xsl:value-of select="addr"/></td>
</tr>
</xsl:for-each>
</table>
</xsl:template>
</xsl:stylesheet>
このスタイルシートについて解説します。リスト1とリスト3を比較して分かるとおり、XSLTプロセッサは、まずメインのXMLデータを処理します。メインのXMLデータにtbl要素が出現すると、XSLTプロセッサは、新規顧客表を作成します。そこで“customers200110.xml”が読み込まれます。
リスト1のtbl要素をご覧ください。tbl要素の属性hrefには、読み込み対象のXMLデータのURIが割り当てられています。
<tbl href="customers200110.xml"/>
リスト3のdocument関数を呼び出しているところを見てください。ここでdocument関数は、@hrefという表記で分かるとおり、カレントノードtbl要素の属性hrefの値を参照してXMLデータ“customers200110.xml”にアクセスします。返却値は、“customers200110.xml”のルートノードです。
document(@href)
このルートノードは、すべてのcustomer要素を参照するために繰り返し使用されます。それで、xsl:variable要素を使ってルートノードを変数tに割り当てておきます。
<xsl:variable name="t" select="document(@href)"/>
“customers200110.xml”のルートノード以下のすべてのcustomer要素について、テンプレートがインスタンス化されます。変数の値を参照するときは、変数名の頭に“$”の文字を付けて“$t”と記述します。従って“$t//customer”という表記は、変数$tに割り当てられているルートノードの子孫ノードcustomerを指しています。
<xsl:for-each select="$t//customer">
<tr>
<td><xsl:value-of select="name"/></td>
<td><xsl:value-of select="addr"/></td>
</tr>
</xsl:for-each>
IE5による表示結果を図3に示します。
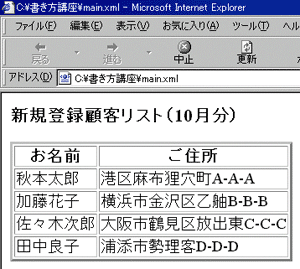 図3 document関数を使うサンプルの表示結果
図3 document関数を使うサンプルの表示結果相互参照するノードを識別する
複数のXMLデータの扱いなど、処理が複雑になってくるとXSLTのあるノードから別のノードへ効率的に相互参照する仕組みが欲しくなります。XSLTでは、ビルトイン関数idやビルトイン関数keyを使ってノードの相互参照を実現することができます。
■id関数を使って相互参照する
まず、id関数について説明します。
id関数の使い方
node-set id(object)
(返却値)(ID型の属性値)
- 引数で指定された値と同じ一意のID値を持つノード、またはノード集合を返却します。
id関数の使い方をリスト4のXMLデータを使って示します。
<?xml version="1.0" encoding="shift_jis"?>
<?xml:stylesheet type="text/xsl" href="id.xsl"?>
<!DOCTYPE customers [
<!ELEMENT customers (customer)*>
<!ELEMENT customer (name,addr,area)>
<!ELEMENT name (#PCDATA)>
<!ELEMENT addr (#PCDATA)>
<!ELEMENT area (#PCDATA)>
<!ATTLIST customer id ID #REQUIRED>
]>
<customers>
<customer id="c001">
<name>秋本太郎</name>
<addr>港区麻布狸穴町A-A-A</addr>
<area>関東</area>
</customer>
<customer id="c002">
<name>加藤花子</name>
<addr>横浜市金沢区乙舳B-B-B</addr>
<area>関東</area>
</customer>
<customer id="c003">
<name>佐々木次郎</name>
<addr>大阪市鶴見区放出東C-C-C</addr>
<area>近畿</area>
</customer>
<customer id="c004">
<name>田中良子</name>
<addr>浦添市勢理客D-D-D</addr>
<area>沖縄</area>
</customer>
</customers>
適用するスタイルシートはリスト5にあるとおりです。
<?xml version="1.0" encoding="shift_jis"?>
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:template match="/">
<html>
<body>
<h3>お客様IDがc004の方は次の方です。</h3>
<ul>
<li><xsl:value-of select="id('c004')/name"/>様</li>
</ul>
</body>
</html>
</xsl:template>
</xsl:stylesheet>
この中でid関数が使われている部分を見てください。
<li><xsl:value-of select="id('c004')/name"/>様</li>
id('c004')という記述は、属性id(DTDで属性のデータ型がID型に宣言されている)の値が“c004”となるcustomer要素のことを表しています。ここでは、その要素の子要素nameの文字列値をHTMLタグ<li></li>の間に要素の内容として埋め込んでいます。
IE 5による表示結果を図4に示します。
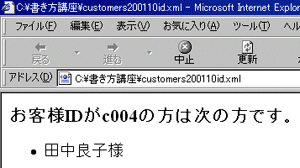 図4 id関数を使うサンプルの表示結果
図4 id関数を使うサンプルの表示結果■id関数の限界
しかしながら、id関数には以下の限界があります。
- ID属性がDTDなどで定義されていなければならない。
- IDは属性として指定する。従って要素の内容を使った参照ができない。
- 1つの要素が持てるIDは1つだけ。
そこで、ID型として定義されていなくても、スタイルシートの中で定義すれば相互参照ができるようにしたのがkey関数です。
■key関数を使って相互参照する
id関数は、DTD(あるいはXML Schemaなどのスキーマ記述言語)でID型として明示的に宣言された属性をノードの識別情報として使う関数です。一方、これから説明するkey関数は、ある要素の文字データや属性の値(ID型でなくてよい)をキーとしてスタイルシートの中で定義し、それをノードの識別情報に使うための関数です。
key関数で使用するキーは、スタイルシートの中でxsl:key要素を使ってあらかじめ宣言する必要があります。xsl:key要素の書き方は以下のとおりです。
xsl:keyの書き方
<xsl:key name="キーの名前" match="パターン" use="式"/>
- name属性は、キーの名前を指定します。match属性は、キーを割り当てるノードを指定します。use属性は、指定された式の評価結果をキーの値とします。use属性の式を評価するに当たってのコンテキストノードはmatch属性のノードになります。
xsl:key要素で宣言されたキーを実際に参照するkey関数の書き方は以下のとおりです。
key関数の使い方
node-set key(string, object)
(返却値)(キーの名前)(キーの値)
- 返却値は、第1引数のキーの名前と第2引数のキーの値を持つノード集合です。
リスト2のXMLデータを使って、key関数の使い方を示します。リスト6のスタイルシート“key.xsl”を適用します。
<?xml version="1.0" encoding="shift_jis"?>
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:key name="area-key" match="customer" use="area"/>
<xsl:template match="/">
<html>
<body>
<h3>関東地方にお住まいのお客様は次の方々です。</h3>
<ul>
<xsl:for-each select="key('area-key','関東')">
<li><xsl:value-of select="name"/>様</li>
</xsl:for-each>
</ul>
</body>
</html>
</xsl:template>
</xsl:stylesheet>
key要素が使われているところを以下に抜き出します。
<xsl:key name="area-key" match="customer" use="area"/>
name属性により、キーの名前として“area-key”を指定しています。match属性により、キーを割り当てるノードとしてcustomer要素を指定しています。さらにuse属性により、customer要素をコンテキストノードとしたときのarea要素の文字列値がキーとして使用されることを指定しています。
key関数が使われている部分を以下に抜き出します。
<xsl:for-each select="key('area-key','関東')">
key関数の最初の引数は、key要素において“area-key”という名前で宣言されたキーを使用することを指定しています。2番目の引数はキーの値を指定しています。この場合、key関数はcustomer要素の子要素areaの文字列値が“関東”となる要素を返却します。
ID型の属性値は、1つのXMLデータの中で一意でなければなりません。従って同じID値を持つ要素が存在してはなりません。一方、同じキー値を持つ要素は複数あっても構いませんし、1つの要素が複数の種類のキーを持ってもかまいません。したがって、key関数によって複数のノードを参照することもあり得ます。
リスト2のXMLデータの場合、キーの値であるareaの文字列値が“関東”となる要素が複数存在しています(id属性が“c001”のcustomer要素と“c002”のcustomer要素)。リスト6では繰り返し処理を行うfor-each要素を使ってkey関数が参照するすべての要素を処理しています。処理結果を図5に示します。
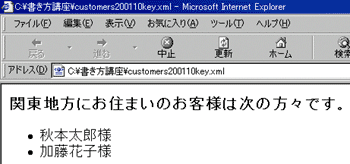 図5 key関数を使うサンプルの表示結果
図5 key関数を使うサンプルの表示結果■まとめ
今回は、document、id、keyという3つの関数を取り上げ、複数のXMLデータを操作する方法と、相互参照機能を使って必要なデータを抽出する方法について説明しました。次回は、結果ツリーのファイル出力、およびXSLT要素や関数の拡張について解説します。
本記事は、日本ユニテック発行のXMLテクノロジー総合情報誌「Digital Xpress」に掲載された、XSLT特集「XSLTの実力を探る!」の内容をもとに、加筆修正したものです。
Copyright © ITmedia, Inc. All Rights Reserved.




![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。