第4回 VLIWは世界(プロセッサ)を救うか?:頭脳放談
CrusoeがVLIWを採用しているといわれているし、Itanium(プロセッサコアはVLIWの一種)もそろそろ登場するはず。ということで、今回はVLIWの話をしよう。
TransmetaのCrusoeがプロセッサのコアにVLIWを採用していると言われているし、正式発表が予定よりも少々遅れそうだが、インテルのItanium(これもプロセッサ コアはVLIWの一種)もそろそろ登場するはずということで、今回はVLIWの話をしよう。ただ、筆者はいわゆる古典的なプロセッサの設計者で、VLIWはずっと前から横目で見てはいても、「別な河岸にあった存在」であったので、VLIWの設計者からすると偏見ばかりかもしれないことをお断りしておく。
VLIWを短く言えば
「ずっと前から」と書いたとおり、VLIWは1980年代末にはすでに気になる存在であった。現在主流のスーパースカラー マシンが花開く前から、すでに研究されていた比較的古い概念なのである。何せ、原理からいえば超簡単なのだ。最近のハイエンドのスーパースカラー マシンなどとは比べ物にもならない。例えば、並列に4個の演算器を並べる。それぞれの演算器に対して、例えば、32ビット幅の命令を供給する。すると、32ビット幅の命令を4個一度に供給するのだから、全体としては128ビット幅の命令長になる。命令長がやけに長いので、「Very Long Instruction Word」の頭文字をとって「VLIW」というわけだ。実に単純明快。そのうえ、一度に1つの命令しか実行できないスカラー プロセッサに比べれば、この例の場合であれば、同時に4つの命令を実行できるのだから、性能がよいことも明らかだろう。
では、なぜ今までこんないいものが日の目を見なかったか? それは、一にも二にも、並列に命令を実行できるという並列性を活かせるソフトウェアがなかったからだ。一般的なソフトウェアの場合、あれやって、これを判断して、それからこれをやってと、1個1個順序よく処理していくものが多い。行列の計算といった処理であれば、一度に複数の演算ができて高速になりそうだ、と思い付くが、むしろこういうケースはマレである。それにもかかわらずVLIWは、同時に実行する複数の演算を、ソフトウェアが事前に並べてくれることを当てにしていた。

もちろん、そんなに調子よく、複数の演算が並ぶハズがない。それは、優秀な人ばかりであるVLIWの設計者たちもよく認識していて、同時に処理してよい仕事を、きちんと並べてくれるコンパイラの開発こそが、VLIWの生命線であるとして、そこに注力していたわけだ。その裏にはハードウェアは必要なものだけシンプルに、複雑なものはソフトウェアにしていこうという思想があった。だからVLIWというとソフトウェア屋さんばかりが活躍していて、筆者のようなハードウェア屋は出る幕なし、という感じが漂っていた。そのようなわけで、ずーと横目で見続けることになったわけだ。
VLIWはソフトウェアが障害に
しかし、傍目にもVLIW向けのコンパイラの開発は、相当苦労の連続であったと思われる。並列にいくつも演算できるときは強力なVLIWだが、プログラムにはどうしても並列に処理できず、直列にしなければならないようなこともある。こんなとき演算器の1つだけが稼働し、ほかの演算器はNOP(ノー オペレーション、1回休みという感じ)となる。このような処理が続くと、VLIW用のプログラムはNOPだらけの水脹れになってしまう。また、大した演算処理もせず、あっちこっち飛び回るようなプログラムや、ちょこまかした条件判断、条件分岐なども、VLIWは苦手としたはずだ。分岐やループは、どのプロセッサでも命令実行過程の乱れを最小限にするように検討する項目なのだ。特に、1度に多くの演算ができるVLIWにとっては、ちょっとの隙間も、たくさんある演算器の観点から見れば、大量の機会損失となる。すると本来プロセッサが持っている性能と、実際の性能があっという間に乖離してしまう。これを避けようとループなどをアンローリング(*1)して展開していけば、今度はプログラムのサイズが魔法のように膨らんでしまう。あまりに巨大なプログラムができあがって、途方に暮れていた人もいるのではないかと推測している。
*1 ループ処理を展開し、直線的なプログラムにすること。これにより分岐処理が不要になり、並列処理が行いやすくなる。

こうしたVLIWの方向に対し、逆張り(ハードウェアを重視)して、先行したのがスーパースカラー マシンであった。彼らも並列度を高め、複数の処理装置を備えて複数命令を同時に実行しようとしたことは同じである。しかし、VLIWのように、実行すべきソフトウェアが並列に実行できるようになっていることは期待しなかった。「普通」のソフトウェアの流れの中に潜んでいる並列性をハードウェアにより引き出すことで、ハードウェアの並列度を活かそうとしたのだ。この考え方であれば、今までのソフトウェアをそのまま実行することができ、VLIWのような問題は起こらない。まさにハードウェア屋主導のソリューションといえる。ソフトウェア屋主導のはずが、そのソフトウェアがネックになってなかなか普及の手がかりがなかったVLIWを尻目に、スーパースカラー マシンはそれ以前のマシンの正統な継承者として認知され、爆発的に普及して今日に至っている。しかし、ハードウェアにより並列度を引き出すというやり方のため、ハードウェアはソフトウェアに内在するいろいろな依存関係を解き、投機的実行や分岐予測など、非常に奇怪で複雑な制御をしなければならないようになってしまった。本来処理すべきデータを扱っているハードウェアより、これらを制御するためのハードウェアのほうが、はるかに複雑で回路の面積が多くなるという、何とも奇妙な状況に陥ってしまっている。ここに来てハードウェア屋は、ハードウェアで壁に突き当たってしまったのである。
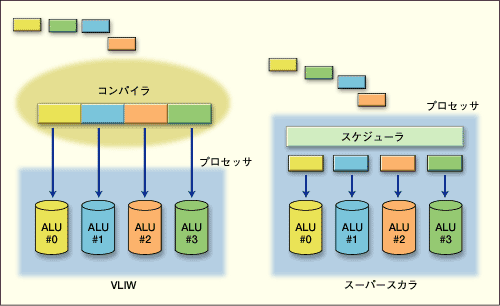 VLIWとスーパースカラーの違い
VLIWとスーパースカラーの違いVLIWでは、コンパイラによって事前に並列に実行できる処理をまとめ1つの命令としてプロセッサに与える。それに対しスーパースカラーでは、プロセッサ内部のスケジューラがプログラムの並列性を引き出し、同時処理を行う。
CrusoeとItaniumでVLIWは新時代へ
これでようやくVLIWにも目が出てきた。何せハードウェアは単純に作れるので、動作クロックを向上させるのに有利だ。もちろん、ハードウェアが小さければ消費電力も少なくて済む。端的にいえば、問題はソフトウェアだけだったのだ。

Crusoeが立派なのは、この解決にコードモーフィングという一種のJITコンパイラのようなソフトウェアを考え出したことだ。コードモーフィング ソフトウェアは、あれやってこれやってと順序よく書かれている今までのx86コードを読んで、バラバラにして並列に実行できる操作を抽出して、VLIWのコードに変換する。見かけは今までのプログラムがそのまま実行できているように見えるから、わざわざプログラムを書き直したり、再コンパイルしたりといった、それ以前のVLIWの普及を妨げていた問題から解放される。変換されたVLIWのコードは、メイン メモリの一部にキャッシングされるが、固定的に記録されるわけではないので、コード サイズが膨らんでもそのサイズは見えない。VLIW普及の障害を一気に解決して登場してきたのだから、注目を集めるのも当然といえるのだ。
また、発表はCrusoeより前、正式登場は後になるインテルのItaniumが採用するEPICアーキテクチャもVLIWの変種としてよいだろう。既存のx86との互換性という点では、ハードウェアによるアプローチを採用しており、Crusoeとは大分方向性が違う。しかし、EPICは一般のVLIWでの大きな問題の2つをテンプレートという概念1つで解決している点に注目すべきだろう。
1つは、先ほど指摘したような演算器でやることがないときに、NOPでコードが膨らむという問題である。テンプレートによりここは1つの処理しかないとか、2つだけとか規定しておけば、無用なNOPを記述することが避けられる。

もう1つは古典的なVLIWで問題になる。VLIWの世代間でのマシン コード互換性の維持が難しいという問題である。例えば、演算器4個のマシンをアップグレードして演算器を8個にしたとする。8個のマシンのためには、例えば2倍の命令ビット幅の別なプログラムが必要になり、再コンパイルか、下手をするとプログラムの書き替えが必要になる。もともとのVLIWの定義であればそうなる。ところが、EPICはプログラムの中に現れる並列度に基づくだけで、ハードウェアの許容する並列度から切り離してテンプレートをコーディングできるようになっている。これにより、将来並列度の上がったハードウェアが現れても、以前のバイナリが実行可能になる。この機能は商用のプログラム資産についての配慮をしなければならないインテルにとっては、ビジネス上必須の選択であったかもしれない。
このようにCrusoeはソフトウェアの進歩により、EPICはアーキテクチャの進歩により、VLIWがスーパースカラー マシンに取って代わる機会を作ったといえる。これが定着するかどうかは、VLIWの利点であるハードウェアのシンプルさを活かして、「より高速」といった特性を現実にアピールできるか否かにかかっている。まだまだ、やらなければならないことは多そうだ。
筆者紹介
Massa POP Izumida
日本では数少ないx86プロセッサのアーキテクト。某米国半導体メーカーで8bitと16bitの、日本のベンチャー企業でx86互換プロセッサの設計に従事する。その後、出版社の半導体事業部を経て、現在は某半導体メーカーでRISCプロセッサを中心とした開発を行っている。
「頭脳放談」
Copyright© Digital Advantage Corp. All Rights Reserved.




![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。