SSL/TLS(Part.3):不正アクセスを防止するSSL/TLS(4)(3/4 ページ)
主要パラメータと生成手順
今回は少しずつSSL/TLSの深い部分にスポットを当てるわけだが、ここからその最も深い部分にさしかかってくる。もし、SSL/TLSの概要を知ることが目的なら、軽く読み流す程度でも構わない。反対にSSL/TLSの詳細を知るのが目的であれば、ここからが佳境といった感じである。
暗号化通信を行うに当たって、最終的に必要となる情報には、MACシークレット、暗号化キー、そして初期ベクタ(IV)の3つがある。これらはコネクション内部の状態変数に含まれており、特定のアルゴリズムによって生成されている。
図25は、これら主要情報を生成するまでの流れを示したものだ。右側の最終情報に至るには、何を材料にしてどんな計算をし、途中でどういった形を経るかが読み取れると思う。
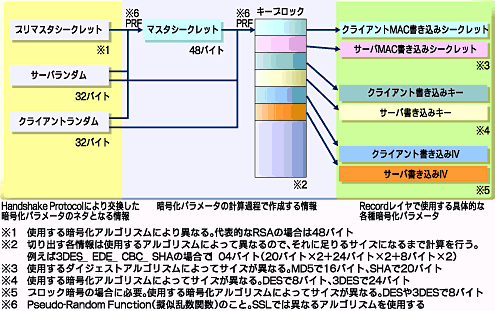 図25 Handshake Protocolで交換した3つの情報から、暗号化で最も重要なパラメータ群を生成するまでのフロー
図25 Handshake Protocolで交換した3つの情報から、暗号化で最も重要なパラメータ群を生成するまでのフロー図から分かるように、これらの材料となる情報には、「プリマスタシークレット」「サーバランダム」「クライアントランダム」の3つがある。それを元ネタとしてPRF(pseudo-random function:疑似乱数関数)と呼ばれる演算を施して「マスタシークレット」を生成。さらにPRFを行って生成したキーブロックから順次切り出したものが、右端にある6つの情報となる。情報が6つあるのは、それぞれクライアントが送信時に使用するものと、サーバが送信時に使用するものが、それぞれ3つずつ存在するためだ。
サーバ、クライアントを問わず、これらの情報は必ず6つすべてを所有していなければならない。理由は簡単だ。例えばサーバが自分で送信するデータは「サーバ書き込みキー」を使って暗号化するが、クライアントから受信したデータは「クライアント書き込みキー」により復号しなければならないためだ。双方向に通信する以上は、これら6つの情報を両者が共有していなければならない。
これらの材料となる3つの要素は次のようなものだ。
プリマスタシークレット
その名のとおりマスタシークレットの前駆情報に相当するもの。キー交換アルゴリズムによってそのサイズは異なる。図26に示すように、RSAを使用する場合は、2バイトのversion番号と46バイトのクライアントが生成した乱数により構成される。この情報は、Handshake Protocolの1つClient Key Exchangeに含まれており、サーバに向けて送信されるときには全体がサーバの公開鍵で暗号化されている。
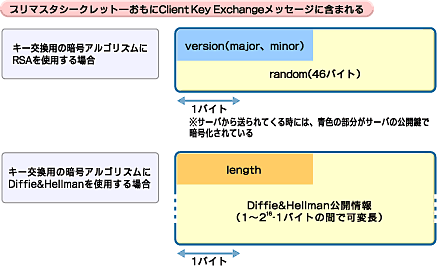 図26 プリマスタシークレットとなる情報は利用アルゴリズムによって異なる
図26 プリマスタシークレットとなる情報は利用アルゴリズムによって異なるなお、このあたりの具体的なメッセージ内容などについては、後ほど、メッセージシーケンスの説明時に触れる。それを見ればさらに具体的なイメージが湧くと思うが、ここでは「クライアントから暗号化されて送られてくる乱数情報」と考えておいていただけばよいだろう。
またDiffie&Hellman(離散対数方式)を利用する場合は、2バイトの長さ情報と、1バイトから2の16乗−1までの範囲の、Diffie&Hellman公開情報が含まれる。Diffie&Hellmanは離散対数を求めることが困難な性格を利用した公開鍵配布システムの1つだ。
なお、Diffie&Hellman公開情報は、Client Key Exchangeメッセージに含まれる場合のほか、Client Certificateメッセージに含まれることもある。
クライアントランダム/サーバランダム
クライアントまたはサーバが生成した乱数で図27のような構造をしている。最初の4バイトが生成した日時、またその後の28バイトがクライアントまたはサーバが生成した乱数となる。設定される日時はいわゆるunix timeで、1970年1月1日0:00 GMTからの経過秒数で表したものだ。
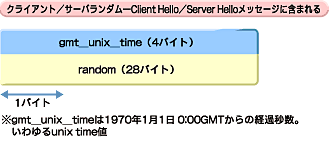 図27 クライアントランダム/サーバランダムの構造
図27 クライアントランダム/サーバランダムの構造これら3つの情報がもととなって、次にマスタシークレットを生成する。この生成にはPRFと呼ばれるアルゴリズムが使用されている。PRFとはどんな計算なのだろうか。続いて説明しよう。なお、PRFを利用するのはTLSだけである。SSLは異なるアルゴリズムを利用しているので注意が必要だ。
PRFの計算アルゴリズム
PRFはpseudo-random function(疑似乱数関数)の略だ。そもそも乱数とは、まったくでたらめに並んだ数値の列を指す。また、各数値は出現回数がほぼ同割合で、かつ出現には規則性がない。そういった性格の乱数を、計算によって疑似的に生成するのが疑似乱数関数だ。
こういった疑似乱数を生成する関数は、一般的なプログラミング言語にもだいたい含まれている。ただし、その品質が数学的には十分でないことも多く、乱数の品質が直接セキュリティレベルに結びつくようなアプリケーションでは、ソフトウェア自身で生成するケースもある。SSL/TLSなどは、その代表例といってもよいだろう。
もっともTLSのPRFは、その外部から見た姿は、プログラミング言語が持っているような疑似乱数列の単純な生成と多少イメージが異なる。具体的には、PRFは「mビットの情報をnビットの情報に拡張する」ために用いることが多く、主に、その拡張部分のベースとなる情報を作り出すために疑似乱数を用いている点だ。これは言葉で説明しにくいのだが、後ほど計算アルゴリズムを表した図をご覧いただけば、この意味を納得していただけると思う。
では、最初にPRFの関数型を見ておこう。TLSで使用するPRFでは、その入力に3つのパラメータを持っている。シード、ラベル、そしてシークレットだ。
まず「シード」は、疑似乱数関数ならどれでも備えているもので、乱数のタネになる数値である。疑似乱数はシードに対して特定の計算を施してランダムな数値を生成する。次の「ラベル」は、シードとは別の次元で乱数の系列をコントロールするものだ。同じシードであっても、ラベルが異なれば発生する数列は異なる。なお、後で説明するが、関数内部ではシードとラベルは結合して1つのタネ情報として用いられている。
最後の「シークレット」に関しては、TLSのPRF特有のパラメータといえる。これは、乱数の生成時に、その構成情報の一部として、MAC書き込みシークレットをパラメータとして与えるものだ。もともとMAC書き込みシークレットは秘密情報なので、これをパラメータに加えることで、乱数の生成系列を外部から推測することが困難となる。これはセキュリティレベル向上に寄与している。
これらのパラメータを用いて、どのような計算を行えばよいのか。PRFの生成アルゴリズムを図9に示す。シークレットは前半分と後半分に2分される。ラベルとシードはビット列を結合しておく。そして、シークレット前半とラベル+シード情報をP_MD5関数に、またシークレット後半とラベル+シード情報をP_SHA-1関数に、それぞれ入力する。そして両関数の出力結果のXOR(排他的論理和)をとったものがPRF関数の計算結果とする。
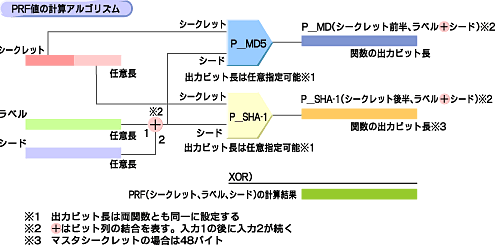 図28 PRF値の計算アルゴリズム。P_MD5とP_SHA-1が重要な役割を果たす
図28 PRF値の計算アルゴリズム。P_MD5とP_SHA-1が重要な役割を果たすこの計算アルゴリズムのポイントは、任意長の情報であるシークレット、ラベル、シードをもとにして、出力結果の分布を偏らせることなく、必要なビット長に拡張した情報が得られる点だ。その主な役割を果たしているのは、P_MD5やP_SHA-1といった関数である。MD5やSHA-1がハッシュ関数であることはすでに述べた。P_MD5やP_SHA-1は、これらハッシュ関数を使ってビット列の拡張を行っているもので、PRF関数の最も重要な部分を担っている。
また、P_MD5とP_SHA-1の両方を使っているのは、PRFの安全性をより高めるためである。どちらか一方だけでは、そのハッシュ関数が破られたときに、TLS自身の安全性まで連鎖破綻するかもしれない。両関数を同時に使用することで、たとえ一方の関数が破られた場合でも、破られていない方の関数でTLSの安全性が確保できるという考え方である。
Copyright © ITmedia, Inc. All Rights Reserved.




![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。