HTTP(Hyper Text Transfer Protocol)〜後編:インターネット・プロトコル詳説(2)
前回までで、HTTPにおけるメッセージ構造の動作について説明してきた。HTTPの後半では、HTTPにおけるそのほかのさまざまな仕様について説明しよう。
認証〜Basic認証の動作
Webブラウザで会員制のサイトを訪れた際、アクセスするときにユーザー名とパスワードを要求され、ログインを尋ねられることがあるだろう。正しいユーザー名とパスワードを入力した場合のみ、ログインが可能になる。
これはHTTPで定義されているBasic認証(基本認証)の機能である。RFC2617に定義されている。
まずWebサーバでは、Basic認証の範囲(対象となるディレクトリやファイルの指定)の設定が必要になる。HTTPサーバの種類によって、この方法は異なる。例えばApacheでは、.htaccessファイルを用意する必要がある。IIS(Internet Information Server)では、IISコンソールから、「ディレクトリセキュリティ」タブ→「認証方法」から基本認証をチェックする。
これらの1つの認証設定に対して「Realm(領域)」と呼ばれる、特定するための名前を設定することができる。
AuthType Basic AuthName "Access Deny Directory 1" require valid-user AuthName "Access Deny Directory 1" <--------- Realmの指定 AuthUserFile /usr/local/www/deny/ .passwd AuthGroupFile /dev/null <Limit GET> require valid-user </Limit>
さて、設定を確認したところで、HTTPの動作を見てみよう。
このようにアクセス制限されたディレクトリへのアクセスが行われると、HTTPサーバはステータスコード401(Authorization Required)を返す。これは、要求されたURIはアクセス制限されているということをWebブラウザに知らせるためだ。
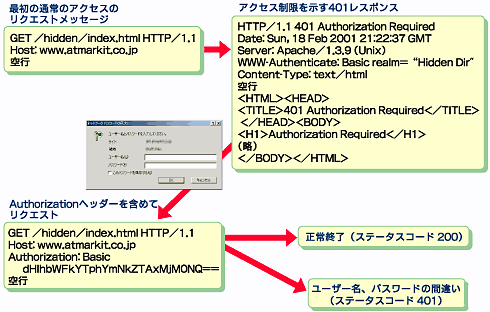 図1 アクセス制限されたディレクトリへのアクセスが行われた場合に発生するメッセージ群
図1 アクセス制限されたディレクトリへのアクセスが行われた場合に発生するメッセージ群このレスポンス・メッセージに含まれているWWW-Authenticateフィールドが、アクセスするための事前情報を含んでいる。
WWW-Authenticate: Basic realm=Realm名
ここに示されている「realm=」が上記で設定したRealmになる。このステータスコード401をWebブラウザが受けると、よく知られているユーザー名/パスワードの入力画面を表示するのである。Realmは例えばIEでは「領域」としてダイアログには表示される。
ユーザー名/パスワードが入力されると、今度はWebブラウザはAuthorizationフィールドを含んだリクエストを行う。
Authorization: Basic credential文字列
このリクエストのcredential文字列は暗号化されているようにも見えるが、単なるBase64エンコードだ。つまり平文だと思っていい。「ユーザー名:パスワード」という形式でフォーマットされている。
このリクエストを受け取ったサーバは、Realmからパスワードファイルを読み出し、ユーザー名とパスワードの組み合わせが正しいかチェックする。正しい場合のみ、アクセスを許すことになる。正しくない場合にはやはりステータスコード401を返答し、アクセスを許さない。
なお、こうしたアクセス制限は、制限されたディレクトリへのアクセスごとに行われる。つまり、HTMLや画像など、それぞれのアクセスごとに行われる可能性があるのだ。ここで、「画像ごとにユーザー名/パスワードを入力したことはないぞ」という疑問を持ったとしたら、それは正しい。実は、Webブラウザが一度入力されたユーザー名とパスワード(と関連するURL)を通常はきちんと覚えてくれていて、2回目以降は自動的にAuthorizationフィールドをリクエストへ含んでくれるのだ。
これはWebブラウザの仕様しだいなのだが、Webブラウザ創生期からの基本的な共通仕様になっている。
キャッシュ管理
キャッシュとは、主にクライアント(Webブラウザ)側に実装される仕組みだ。一度アクセスしたリソースはWebブラウザが管理するディレクトリなどに一時的に格納しておき、再度表示する必要が起こった場合には、毎回サーバから取得するのではなく、ローカルのリソースを使用することで、全体のレスポンスタイムを向上させる仕組みである。こうしたキャッシュを行うには、リソースが最新の情報かどうかを管理/確認できなくてはならない。
そのためのリクエスト・ヘッダがIf-Modified-Sinceだ。値にはDate(日付と時刻)を取る。このDate以降変更されているならリソースを通常どおり返答し、でなければ文字列ステータスコード304(Not Modified)を返すように分岐指示するヘッダである。
つまり、すでにローカルにキャッシュされているリソースについて適用すると、常に最新かどうかをサーバが判別してくれるわけだ。一度訪れたことのあるサイトでは、ほとんどのリクエストはIf-Modified-Sinceヘッダによるアクセスが行われることになるだろう。
また、以下のようなヘッダも定義されている。
Last-Modified(レスポンス・ヘッダ)
最終更新Dateを示す。キャッシュには直接関与しないが、キャッシュ管理などに利用されることを想定している
Expires(レスポンス・ヘッダ)
リソースの有効期限Date。このDate以降は無効であることを示す。キャッシュは破棄されることになる
Pragma(一般ヘッダ)
「Pragma: no-cache」と指定すると、このリソースのキャッシュを許さないという意味になる。つまり常に最新状態を取得することを強制したい場合に指定する
クッキーの定義と利用
これまで述べてきたように、HTTPは単純なリクエストとレスポンスの組み合わせだけで構成されるプロトコルだ。つまり、1回1回の通信のみで閉じており、次回の通信は前回の結果と関係を持たない。これを「文字列ステートレス(Stateless)」と呼ぶ。ステートレスなプロトコルは単純で実装も簡単だが、トランザクション・アプリケーションのように複数の通信を束ねて、1つの処理を完結しなくてはならない処理などの場合には、対応に困ることがある。
そこで考え出されたのがクッキー(Cookie)だ。クッキーはHTTPのヘッダとして現れ、クライアントでは常に、サーバから返答されたクッキーをローカルに保存し、次に同じサーバや同じURLにアクセスする際に、必ず同じものを送り返さなければならない。
クッキーはもともとNetscape社が定義した独自の仕様だ。現在ではそれをもとにして標準化された仕様であるRFC2109とともに、さらに発展させた仕様がRFC2965として定義されている文字列*1。
*1Netscapeのオリジナル仕様は、RFCのものとも異なっている点がある。最新のWebブラウザでもまだ対応していないようだが、ここではRFCをもとに説明している
クライアントがサーバからレスポンスを受け取る際、以下のようなヘッダを受け取る。
Set-Cookie: Version=バージョン番号;Name=Value;[Path=URL相対パス];[Domain=ドメイン名];[Comment=コメント];[Max-Age=有効期間(秒)];[secure]
これがクライアントが保持すべきクッキー・データの中身である。また、RFC2965では以下のような拡張仕様を採用している。
Set-Cookie2: Version=バージョン番号;Name=Value; [Path=URL相対パス];[Discard];[Domain=ドメイン名];[Comment=コメント];[CommentURL=コメントを関係付けるURL];[Max-Age=有効期間(秒)];[Port=ポート番号];[secure]
クライアントは次のヘッダを用いて、クッキーをリクエスト・メッセージに付加する。
Cookie: Version=バージョン番号;{ Name=Value;[Path=URL相対パス];[Domain=ドメイン名];[Port=ポート番号*2] }
*2ポート番号はRFC2965のみの定義
バージョン番号は、現在では“1”だけが定義されている。「Name=Value」が実際に設定したいクッキーの値だ。アプリケーションが制御できる。例えば「SessionID=12345」などとしてセッション番号を指定すれば、次回のアクセス時にサーバ(のCGIプログラム)が前回のアクセスの続きであることを判断できるだろう。これらの値は複数指定できる。
PathとDomain、Portで示されるのが、クッキーと関連付けられているURLということになる。この定義によって、不必要にほかのサイトにクッキーを送信しないようになる。デフォルトは、クッキーを最初に受け取ったURLである。Discardが指定されると、Webブラウザの終了時に強制的にクッキーは破棄される。
Max-Ageはクッキーの有効期間だ。この秒数を過ぎたクッキーは無効となり、サーバへ送信されない。クッキーが何らかのログイン情報を保持している場合などに、自動ログオフ機能を提供するなどの用途でよく用いられる。
secureは、セキュアな通信(RFCでは特定されていないがSSL通信中と考えてよい)が行われているときのみ、サーバへ送信可能にする。またリクエストのCookieヘッダでは { } 内を複数指定することができる。SetCookie、SetCookie2ヘッダではレスポンス・ヘッダに複数現れることで、複数のクッキー・データを表現できる。
クッキーはプライバシー面から否定的な意見を聞くことも多いが、厳密な運用がなされれば、メリットも非常に大きい。(これはBasic認証も同じなのだが)送信するデータは結局は盗聴などが可能なこと、個人が特定できるようなデータをクッキーに保持しない、などの目安が必要だろう。
ヘッダ・フィールドの種類
そのほかの代表的なヘッダを幾つか紹介しよう。
Host(リクエスト・ヘッダ)
リクエストの送信先サーバ名を指定する。これはDNS名でなければならない。HTTP 1.1においては、(リクエスト・ライン以外では)唯一の必須項目である
Referrer(リクエスト・ヘッダ)
このリクエストを要求した直前のURLを指定する。Webブラウザがこの情報を送出することにより、サーバのアクセスログで自身のサイトにどのページがリンクを張っているか、集計が可能となる
User-Agent(リクエスト・ヘッダ)
使用しているWebブラウザの種類を表すテキストである。個々のWebブラウザに特有なので、Webブラウザの種類の判別や集計に用いられる
Server(レスポンス・ヘッダ)
使用されているサーバ・アプリケーションの種類を表すテキスト
Location(レスポンス・ヘッダ)
URLが指定され、クライアントはこのURLへ接続(リダイレクト)することを要求される
HTTP 1.1での拡張機能
HTTP 1.1では、HTTP 1.0に比べてかなりの機能拡張が行われている。HTTP 1.0で定義されながら、それほど実装がなされなかった機能の整理とともに、HTTP
1.0からの効率性の向上を目指した。主なものを紹介しよう。
永続性接続
HTTP 1.0では、リクエストとレスポンスの1往復が終わると、クライアント/サーバともに接続を閉じてしまうのがデフォルトの動作だった。ここでいう接続とは、TCP/IPレベルでの接続も含んでいる。
しかしすでに説明したように、HTTP接続は、ほとんどの場合一度のアクセスで済むことは少ない。HTMLファイルの取得に引き続き、画像ファイルを必要とする場合や、画面がフレームで分割されている場合など、複数回の連続接続がほとんどだ。こうした仕様においては、TCP/IPレベルでの接続と切断がクライアント/サーバにおいて繰り返されることになる。ネットワークにおいて接続の開始と切断は最もコスト(時間)のかかる処理であるので、非効率このうえない。
そこでHTTP 1.1では、永続性接続を動作のデフォルトとした。これは最初に接続し一度のリクエストとレスポンスを終了しても、TCP/IPレベルでの接続を維持しておく動作のことだ。クライアントがもし続けてリクエストしたい場合には、そのまま次のリクエストを送ればよい。
なお、HTTP 1.0で永続性接続を実現するには、「Connection: Keep-Alive」というヘッダ指定をリクエストで行う。このヘッダも下位互換のために残されている。
また、これに伴い、「パイプライン」という動作も実装されている。これは、リクエストを送信した後に、それに対応するレスポンスを待つことなく、必要なリクエストを続けざまに送信する、という仕様だ。当然レスポンスも続けて返答されてくることになる、高度な通信仕様だ。これにより、ある1つのレスポンスが滞るために全体としてのレスポンスが低下する事態を回避可能になる。また、限りある帯域の効率的な利用にもつながる。TCP/IPにおけるスライディングウィンドウと同様の考え方である。
データレンジ
数Mbytesを超えるような大きなファイルをダイヤルアップ環境などでダウンロードしていて途中で接続が切れてしまい悔しい思いをしたことはないだろうか。HTTP 1.1ではこうした状況などでファイルの途中から取得を再開できたり、リソース・データの一部だけを取得するための「データレンジ」という仕組みを採用している。
リクエスト・ヘッダで次のようなヘッダを指定すると、必要な範囲のデータのみを取得できる。
Range: bytes=[start] - [end]
単位はバイトで指定する。例えば「100-1000」は100バイト目から1000バイト目までを要求する意味になる。
また、エンティティ・ヘッダでも同様に次のようなヘッダが定義されている。これは含まれているデータの範囲を示す。
Content-Range: [start] - [end]/全体のバイト数
単位はやはりバイトで指定する。
このデータレンジの考え方は、キャッシュコントロールを複雑にする可能性がある。つまり、「キャッシュの1ファイル=実際の1ファイル」ではなくなるのだ。そこで、以下のようなヘッダが定義されている。
ETag—エンティティタグが格納される。エンティティタグは、サーバが生成するエンティティ(ほぼボディ・データと思ってよい)に対する固有の文字列である。サーバが管理しており、リソースの全体または一部と一致する
If-Range(リクエスト・ヘッダ)—以前にサーバから渡されたエンティティタグを指定する。このエンティティタグが示すデータの一部が最新であればデータの残りを返答するように要求する。最新でなければ、全体が返答される。なお、エンティティタグだけでは必要なデータの範囲が分からないので、Rangeフィールドと組み合わせて使用しなければならない
その他
キャッシュコントロール(Cache-Control)
一般ヘッダを定義し、さまざまなキャッシュ管理を可能にしている。これは、キャッシュ機能は有効なレスポンスタイム向上の方法であるとの理解からだ
プロキシの想定
HTTP 1.1では、現在では多く利用されているプロキシサーバの仕様についても想定している。例えば1.0クライアントもサービスするプロキシでは送るべき/べきでないヘッダ・フィールドもあるし、1.1においてもプロキシが介入して削除したり付加すべきヘッダも存在する。これらあるべき動作について、細かく定義されている
転送エンコーディング(Transfer Coding)
コンテンツ・エンコーディングがリソースを最初から静的にエンコーディングするのに対し、転送エンコーディングは転送時にのみ適用されるエンコーディングだ。永続性接続の導入に伴い、コンテンツ・エンコーディングだけではデータの終わりを検知しにくいため導入された。送信側が送信とともにエンコードし、受信側は受信とともにデコードすることを前提にしている。現在ではチャンク形式と呼ばれる方法のみが定義されている。Transfer-Encodingフィールドで形式を指定する。なお、転送エンコーディングが使用される場合、Content-Lengthは付加されないか、無視される
WWW(World Wide Web)とは、「世界中に張り巡らされた蜘蛛の巣」の意だそうだ。
蜘蛛の巣は複雑に絡み合い、一朝一夕では構造を理解するのも大変そうだが、その糸は意外に単純なものだ。その単純さゆえ、CORBAやIIOPといった「ポストHTTP」も、まだその地位を凌駕するには至っていない。おそらくは、今後も揺らぐどころか、SOAPなど商取引アプリケーションへの展開のように、ますます重要性は際立っていくことだろう。糸は細い方が何かと使いやすいとみえる。
次回はMIMEとインターネットメール・フォーマットについてお届けしたい。
- インターネット・プロトコルをインターネットから探ろう
- FTP(File Transfer Protocol)〜後編
- FTP(File Transfer Protocol)〜前編
- IMAP4(Internet Mail Access Protocol version 4)〜後編
- IMAP4(Internet Mail Access Protocol version 4)〜前編
- POP3(Post Office Protocol version 3)
- SMTP(Simple Mail Transfer Protocol)〜後編
- SMTP(Simple Mail Transfer Protocol)〜前編
- MIME(Multipurpose Internet Mail Extensions)〜後編
- MIME(Multipurpose Internet Mail Extensions)〜前編
- HTTP(Hyper Text Transfer Protocol)〜後編
- HTTP(Hyper Text Transfer Protocol)〜前編
Copyright © ITmedia, Inc. All Rights Reserved.




![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。