エンタープライズ向けに刷新されたカーネル・コア:全貌を現したLinuxカーネル2.6(第1章)(1/3 ページ)
feature freezeを迎え、全貌が明らかになったカーネル2.6。2003年6月に正式リリースされる予定の次期安定版カーネルの改良点や新機能を詳しく解説する。(編集局)
Linuxカーネルの次期リリースである2.6は、2002年10月末に予定どおりfeature freeze(注)が行われた。
注:リリースに向けて安定性を向上させるため、新機能の追加を停止すること。
カーネル2.6はスケーラビリティの向上を大きな目標として、カーネルの内部仕様に大幅かつ意欲的な変更が加えられている。また、JFSやXFSといったファイルシステムの追加、USAGIやUML(User Mode Linux)の統合、新デバイスのサポートなども行われた。
第1章となる今回は、カーネル2.6の最大の目標であるスケーラビリティの強化に注目して、主に内部仕様を解説する。次回以降では、主にユーザーから見たカーネルの新機能について紹介する予定だ。
マルチプロセッサシステム対応の強化
■RCU(Read-Copy Update)
カーネル2.6では、RCU(Read-Copy Update)と呼ばれる新しい同期機構が追加された。
カーネルには、複数のプロセッサからの同時アクセスからデータ構造を保護するため、スピンロックをはじめとする同期機構が用意されている。しかし、従来の同期機構ではロック/アンロックの操作にデータの書き換えを伴うため、プロセッサ間のキャッシュ同期処理が必要となり、大規模なマルチプロセッサ環境では大きな負荷になる場合がある。近年のプロセッサは大容量のキャッシュメモリを搭載しており、またプロセッサとメモリの速度差が拡大しているため、キャッシュミスは即性能低下につながる場合が多い。
カーネル2.6で導入されたRCUは、「ポインタの更新はアトミックに行える」と仮定することによって(注)、リードアクセスの際にロック処理を必要としない構造となっている。
注:もちろん、この仮定は現在Linuxでマルチプロセッサをサポートしているアーキテクチャでは成立している。
RCUを使用した場合のデータの更新手順は次のようになる。
- 更新したいデータ構造をコピー
- 1でコピーしたデータを変更
- 元のデータを差していたすべてのポインタを1、2で用意した新しいデータを差すように変更
- 元のデータが後で解放されるように登録
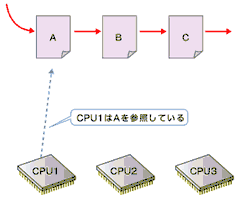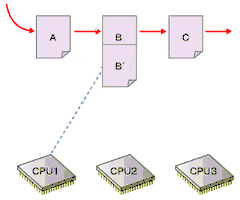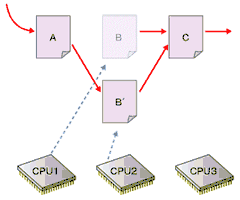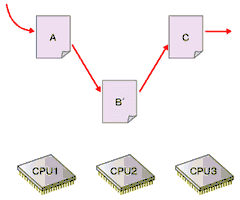 図の詳しい解説は下記参照
図の詳しい解説は下記参照最後の「後で解放」がRCUの特徴である。4の時点では、まだ古いデータがほかのプロセッサによって参照されている可能性があるため、すぐに解放処理を行うことはできない。そこでRCUでは、古いデータを参照しているプロセッサがなくなるのを待って解放処理を行う。カーネル2.6における実装では、プロセッサがアイドルループやユーザーモードの実行を行った場合に、そのプロセッサの古いデータへの参照がなくなったと判断している。
RCUは、更新頻度が低くリードアクセスの割合が高い場合に特に有利なため、ルーティングテーブルなどで利用される。また、dcache(ディレクトリエントリのキャッシュ)にも使おうという話もあるようだ。
RCU自体のアイデアや実装は非常に単純であるが、ロックやリファレンスカウンタによる同期に比べ若干分かりにくいため、バグの温床にならないか多少心配である。
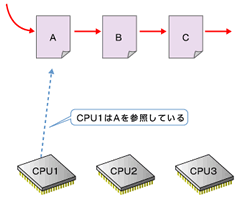
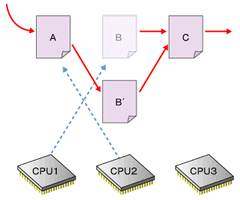
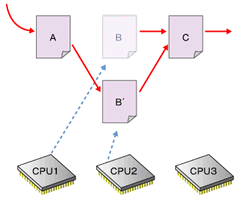
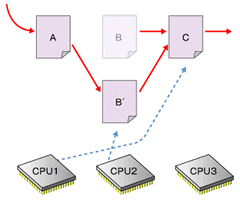
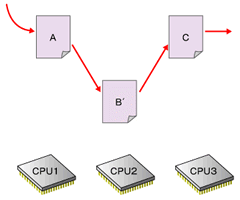 図5 図4の段階でBは安全に解放できるが、それを知るのは難しい。カーネル2.6の実装では、すべてのCPUがユーザー空間の実行やコンテキストスイッチを行うのを待ってBを解放する
図5 図4の段階でBは安全に解放できるが、それを知るのは難しい。カーネル2.6の実装では、すべてのCPUがユーザー空間の実行やコンテキストスイッチを行うのを待ってBを解放する■O(1)スケジューラ
Linuxカーネルでは、scheduleというカーネル内部の関数で実行プロセスの切り替えを行っているが、カーネル2.4はschedule関数中でランキュー(実行可能なプロセスのリスト)を線型走査して次に実行するプロセスを決定していたため、大規模なシステムにおいては効率が悪かった。
カーネル2.6で導入されたO(1)スケジューラは、ランキューに優先度別の複数のリストを用意することで、schedule関数での処理が軽減された。この仕組み自体は特に目新しいものではないが、カーネル2.4と比べれば改善点といえるだろう。
また、プロセッサごとにランキューを持つように変更されたため、マルチプロセッサ時の性能向上も期待される。
編注:O(1)スケジューラについては、Linuxカーネル2.5 最新開発動向も参照
■pagevec
マルチプロセッサ環境では、システムグローバルな構造の更新は同期のためのオーバーヘッドが大きいため、できるだけ避けることが求められる。
カーネル2.6では、複数のページをバッチ的に処理するためのpagevecという構造体が導入され、LRUリストへのページの挿入などを少ないロック回数で行えるようになった。
■そのほかマルチプロセッサ向けの改良
上述した以外にも、ロック粒度の向上など、マルチプロセッサ向けの改良が各所で行われた。
カーネル2.4では、ファイルシステムの操作はBig Kernel Lockと呼ばれるシステムグローバルなロックで保護されていた。カーネル2.6ではこれが各ファイルシステム内部の細かいロックによって置き換えられ、実行の並列度が向上した。
また、カーネル2.4では、ブロックデバイスドライバのリクエストキューが単一のロックによって保護されていたため不要な競合を発生させていたが、カーネル2.6ではデバイスごとのロックに改められた。
デバイスドライバの割り込み処理を遅延実行するBHハンドラ(bottom half handler)は廃止され、ソフトウェア割り込みハンドラもしくはタスクレットと呼ばれる仕組みに書き直された。これらはBHハンドラと異なり、それぞれのCPU上で並行して動作することが可能である。同様に、BHハンドラとして実装されていたタイマーもソフトウェア割り込みハンドラを利用するように改められた。多くのデバイスを利用するマルチプロセッサマシンでの性能向上が期待できる。
さらに、統計情報など頻繁に更新されるデータをプロセッサごとに分離することによって、プロセッサ間のキャッシュのやりとりを軽減する改良が各所で行われた。あるプロセッサでデータを更新した場合、ほかのプロセッサはそのデータに対応するキャッシュを無効にする必要がある。そのため、共有データの頻繁な更新処理はキャッシュミスを増やすことになり、大規模なマルチプロセッサ環境では性能の大幅な低下につながるのだ。
Copyright © ITmedia, Inc. All Rights Reserved.




![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。