エンタープライズ向けに刷新されたカーネル・コア:全貌を現したLinuxカーネル2.6(第1章)(3/3 ページ)
ファイルI/Oの効率化
■Multi page block I/O
カーネル2.4は、ページキャッシュ層からブロックI/O層へリクエストを渡す際、複数ページから成るバッファをそのまま渡すことができず、いったんブロックサイズに分割したバッファをブロックI/O層で再びつなぎ合わせるという無駄な処理を行っていた。
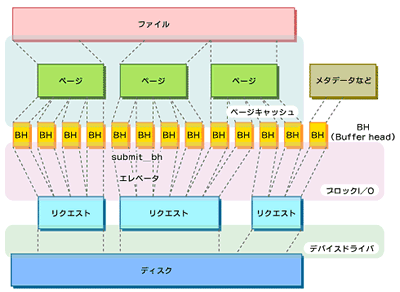 図6 カーネル2.4のファイルI/O
図6 カーネル2.4のファイルI/Oカーネル2.6では、複数ページから成るバッファに対するI/Oを効率的に行うため、bioと呼ばれる構造体が新設された。これは従来のBuffer headに相当するものだが、ページの配列を持つようになっており、複数のページをまとめてブロックI/O層へ渡すことができる。また、これに合わせた各デバイスドライバの修正も行われた。これに伴い、Direct I/Oのコードもbioを使用するように大幅に書き直された。
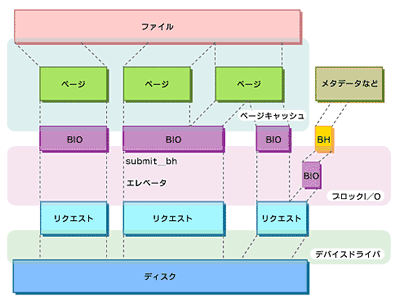 図7 カーネル2.6のファイルI/O
図7 カーネル2.6のファイルI/Oカーネル2.6にも従来のBuffer headは残されているが、その処理はbioを使って実装されている。また、ll_rw_blockなどのおなじみの関数もfs/buffer.cに移され、「DEPRECATED」とコメントされている。buffer headは徐々になくしていこうという方向のようである。
■AIO(Asynchronous I/O)
カーネル2.6には、非同期I/Oのための一連のシステムコールが追加された。Direct I/Oと組み合わせて、データベースなどの用途で性能向上が期待できる。
LinuxのAIO関連システムコールと、それらとほぼ対応するPOSIX aio関数は以下のようになっている。
| システムコール | POSIX aio関数 | |
|---|---|---|
| io_setup | なし | |
| io_destroy | なし | |
| io_submit | lio_listio | |
| io_cancel | aio_cancel | |
| io_getevents | aio_suspend | |
実装的には、do_mmapとkmap_atomicを使用してイベントリストをユーザー空間に持つことにより、システムコールなしでイベントを読み込むことを可能にしているなど、面白い構造になっている。これは、完了イベント処理をできるだけ軽くしたいという、開発者のBenjamin LaHaise氏の意向によるものである。
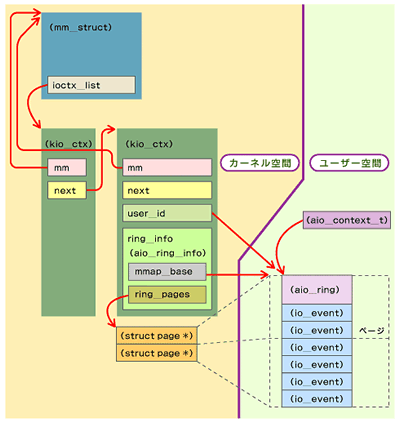 図8 AIOに関するデータ構造
図8 AIOに関するデータ構造■readv/writev
カーネル2.4のreadv/writevシステムコールは、単純にread/writeシステムコール用の処理を必要な回数繰り返すという形で実装されており、特に同期書き込み時の効率が悪かった。
カーネル2.6では、ext2などの主要なファイルシステムでreadv/writevが実装され、この問題が解決された。
地味な改良ではあるが、ログの出力など同期書き込みを多用する場面で性能向上が期待できる。また、readv/writevは、カーネル内部でもNFSサーバなどで使われている。Direct I/Oとの組み合わせでも動作するようになっており、データベース用途などでの高速化も期待できる。
アドレス空間・メモリ管理の改良
■rmap(reverse map)
カーネル2.4では、ある物理ページがどのメモリ空間から参照されているか、そしてそのページがダーティであるか否かを簡単に知る方法がなかった。そこで、メモリ不足時のページアウト処理の際、全アドレス空間をスキャンするという効率の悪い方法を取らざるを得なかった。
カーネル2.6は、page構造体にそのページを参照しているマッピングのリストを保持する変更が加えられ、ページアウト処理の効率が改善された。これはほかのOSでは当たり前の処理であるが、従来のLinuxカーネルでは行われていなかったのである。
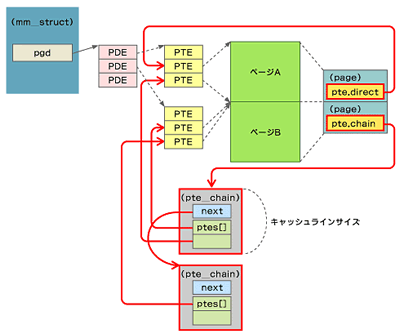 図9 カーネル2.6のVM(rmap)。赤線が2.6で追加された部分
図9 カーネル2.6のVM(rmap)。赤線が2.6で追加された部分注:page構造体のpteメンバは、directとchainをメンバに持つ共有体である。ページが単一のマッピングしか持たない場合(ページA)はdirectメンバが使われ、そうでない場合(ページB)にはchainメンバが使われる。
pte_chain構造体のサイズは、キャッシュの使用効率を良くするため、キャッシュラインサイズに合わせられている。
Linuxらしい実装の工夫として、ページが1つのメモリ空間にのみ参照されている場合を特別扱いして、メモリ使用量を削減している点が挙げられる。一見すると効果があるのか疑問であるが、最近のアーキテクチャではメモリキャッシュのヒット率が性能に大きな影響を及ぼすので、意外と効果があるかもしれない。
■mempool
Linuxカーネルは、メモリが不足した際に不要なメモリの解放処理を行うが、これは常にうまく働くわけではない。例えば、NFSクライアントにおけるダーティーページの書き出し時など、解放処理自体にさらなるメモリ割り当てが必要となる場合がある。
このようなデッドロック問題を避けるため、Linuxカーネルには__GFP_FSというフラグがある。しかし、これはファイルシステムに特化していることもあり、不十分な場合があった。そこで、カーネル2.6にはmempoolというより汎用的な仕組みが追加された。
mempoolは、初期化時に指定したバックエンドアロケータ(従来のslabアロケータやalloc_pageなど)を使用し、指定した数のメモリオブジェクトを常に保持しておくことによってある分量のメモリが常に確保できることを保証する。これにより、高負荷時の安定性の向上が期待される。
なお、ほぼ同様の目的のものとして、FreeBSDのVM_V_PAGEOUT_FREE_MIN/VM_V_FREE_RESERVED(sysctl(3))や、NetBSDのpool_setlowat(9)などがあるので参考にされたい。
以上のように、カーネル2.6にはエンタープライズ向けの改良が多く含まれている。また、本稿では取り上げなかったがext3のhtree、SGIによるXFS、NFSv4、USAGI ProjectによるIPv6対応の改善なども取り込まれた。中にはAIOやNFSv4のように、本稿執筆時点ではまだまだ開発途上のものもあるが、今後の開発に期待したい。
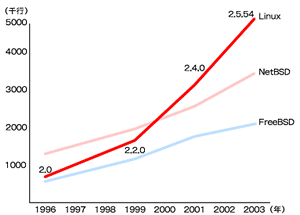 図10 カーネルソースコードの肥大化
図10 カーネルソースコードの肥大化カーネル2.6は2003年6月のリリースを目標に、現在も活発に開発が進められている。当初はハッカーのおもちゃであったLinuxだが、近年ではソースコードも肥大化し、また開発者の多くは企業でフルタイム雇用されて開発に従事しており、もはやIBMやSGIなどの企業パワー抜きでは語れなくなっている。そのため、今後もエンタープライズ向けに力を入れた開発が進められていくことだろう。
関連記事
- 連載:Linux Kernel Watch(連載中)
Linuxカーネル開発の現場ではさまざまな提案や議論が交わされています。その中からいくつかのトピックをピックアップしてお伝えします - 連載:Linuxファイルシステム技術解説
ファイルシステムにはそれぞれ特性がある。本連載では、基礎技術から各ファイルシステムの特徴、パフォーマンスを検証する - 特集:全貌を現したLinuxカーネル2.6[第1章] エンタープライズ向けに刷新されたカーネル・コア
ついに全貌が明らかになったカーネル2.6。6月に正式リリースされる予定の次期安定版カーネルの改良点や新機能を詳しく解説する - 特集:/procによるLinuxチューニング[前編] /procで理解するOSの状態
Linuxの状態確認や挙動の変更で重要なのが/procファイルシステムである。/procの概念や/procを利用したOSの状態確認方法を解説する - 特集:仮想OS「User Mode Linux」活用法
Linux上で仮想的なLinuxを動かすUMLの仕組みからインストール/管理方法やIPv6などに対応させるカーネル構築までを徹底解説 - Linuxのカーネルメンテナは柔軟なシステム カーネルメンテナが語るコミュニティとIA-64 Linux
IA-64 LinuxのカーネルメンテナであるBjorn Helgaas氏。同氏にLinuxカーネルの開発体制などについて伺った - カーネル関連記事一覧
関連リンク
Copyright © ITmedia, Inc. All Rights Reserved.




![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。