文字化け“???”の法則とその防止策:事例に学ぶWebシステム開発のワンポイント(8)
本連載では、現場でのエンジニアの経験から得られた、アプリケーション・サーバをベースとしたWebシステム開発における注意点やヒントについて解説する。巷のドキュメントではなかなか得られない貴重なノウハウが散りばめられている。読者の問題解決や今後システムを開発する際の参考として大いに活用していただきたい。(編集局)
今回のワンポイント
文字化けは、複数の文字規格とベンダごとの実装の違いにより、昔から悩まされ続けている問題である。特にJavaでは、文字が“?”に化けるという問題に遭遇するケースが多い。その大半は、Java内部の文字列がUnicodeとして扱われているために、それに伴うコード変換が原因となって発生している。今回は、BEA WebLogic Server(以下WebLogic)を例に取り、文字化けが発生した場合の確認ポイントと対策について紹介する。
JSPのプリコンパイルで文字化け発生
実際に発生した文字化け問題を例に取り、確認ポイントや対策を紹介する。問題となったのは、JSPのプリコンパイル時に、JSP内に記述した“(株)”*1という文字が“?”のように文字化けするという事例である。システム構成は、Solaris+Sun JDK 1.3+WebLogic 6.1J(sp2)であり、クライアントはWindowsのInternet Explorer(シフトJISで表示することを想定)である。
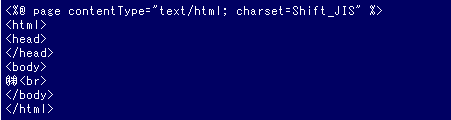 リスト1 文字化けの原因となったJSP
リスト1 文字化けの原因となったJSP文字化けはなぜ起こる?
Javaは内部的に文字列(String型)をUnicode(UCS-2)で保持している。そのため、Javaへの文字列の入出力では必ずUnicodeとの間でコード変換が発生する。特に、Javaのコード変換では、対応するコードポイントが存在しない場合“?”に変換されるという特徴がある。このため、機種依存文字などコードセットごとに存在したりしなかったりする文字が、コード変換により“?”になる。これがJavaにおける“?”の文字化けの原因である。
これ以外にも、ファイル転送時のコード変換や、ブラウザのエンコーディング設定などJava以外の部分でも発生するため、それらにも注意するとよい。
文字化け発生時の確認ポイント
WebLogicを例に取ると、文字化けの可能性がある主な入出力は、以下に示す5カ所となる。
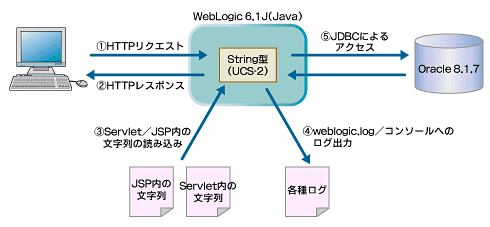 図1 文字化けの可能性がある主な入出力は5カ所
図1 文字化けの可能性がある主な入出力は5カ所どこで文字化けが発生したかという情報は重要である。最近のアプリケーションサーバでは、プログラムで文字コード処理を意識させないよう、文字コードに関する固有の設定が存在する。経験からいうと、文字化けが発生した場合、ソースコード側ではなく設定に誤りがある場合も多い。発生した個所により、影響のある設定が異なるが、それらを把握して対処すれば解決に直結する可能性が高い。
表1にWebLogicにおける代表的な文字列の入出力と、そのときの変換に影響する設定についてまとめる。この表にあるとおり、文字化けが発生した個所が特定できれば、見直すべき個所が明確になる。
| 文字列の入出力 | 分類 | 関連する設定 | |
|---|---|---|---|
| (1) | HTTPリクエスト | Servlet | ・ソースコード中のServletRequest#setCharacterEncoding ・weblogic.xml の<input-charset> ・weblogic.xmlの<charset-mapping> |
| JSP | ・weblogic.xml の<input-charset> ・weblogic.xmlの<charset-mapping> |
||
| (2) | HTTPレスポンス | Servlet | ・ソースコード中のServletResponse#setContentType ・weblogic.xmlの<charset-mapping> |
| JSP | ・pageディレクティブのcontentTypeの指定 ・weblogic.xmlの<charset-mapping> |
||
| (3) | Servlet/JSP内の文字列 (コンパイル時) |
Servlet | ・ソースコードをコンパイルするときのエンコーディングの指定 |
| JSP | ・JSP中のpageディレクティブのcontentTypeの指定 | ||
| (4) | weblogic.log/ コンソールへのログ出力 |
- | ・Javaのデフォルトエンコーディング(起動するユーザーのロケール) |
| (5) | JDBCによるDBへのアクセス (Oracleの場合) |
- | ・DBの文字コードセット ・WebLogic起動ユーザーのNLS_LANG環境変数 ・コネクションプールのweblogic.codesetプロパティ |
JavaのエンコーディングMS932とSJISの違いに注意
MS932とSJISの混同は、初めてJavaやJ2EEでの開発を行う人が陥りやすいポイントである。MS932とSJISでは機種依存文字(NEC特殊文字、NEC選定IBM拡張文字、IBM拡張文字)や〜‖−¢£¬などの扱いが異なり、誤って使用すると“?”に文字化けする。Windows端末からシフトJIS(Cp932)でのアクセスを想定する場合、文字化けを防ぐためにできる限りMS932を明示的に指定すべきである。
今回も、機種依存文字である“(株)”が文字化けしているため、MS932と指定するべきところをSJISと誤った指定をしているのではないかと推測された。
Shift_JISの意味を理解しよう
そこで、表2にあるように、JSPのコード変換に影響を与えるpageディレクティブとcharset-mappingの設定を確認した。
| 設定項目 | 設定 |
|---|---|
| JSP内のpageディレクティブの指定 | <%@ page contentType="text/html; charset=Shift_JIS" %> |
| weblogic.xmlの charset-mappingの指定 |
<charset-mapping> <iana-charset-name>Shift_JIS</iana-charset-name> <java-charset-name>MS932</java-charset-name> </charset-mapping> |
pageディレクティブのcontentTypeで指定するcharsetは、HTTPレスポンスのヘッダに利用される。HTTPはJavaのエンコーディングではなく、ianaで規定されているエンコーディングを指定しなければならないため、表2中のpageディレクティブの指定は、JavaのShift_JISではなく、ianaのShift_JIS*2である。このエンコーディングの指定は、JSPをコンパイルするときにも使用されるが、Shift_JISをそのままJavaのShift_JISとして扱うと問題が生じる場合がある。JavaのShift_JISはMS932またはSJISの別名として定義されており、どちらの別名となるかはバージョンに依存している(JDK 1.3ではMS932だが、JDK 1.4ではSJISとなる)。この問題に対して、WebLogicでは、weblogic.xmlのcharset-mappingに、ianaのcharsetをJavaのcharsetにマッピングする指定を設けることで、明示的にJavaのエンコーディングを指定できるような仕組みが提供されている。よって、このケースでは、Shift_JISは、SJISではなくMS932と設定されており特に問題はないと判断できた。
このように、Shift_JISはいくつかの異なる意味を持っている。安易に使用すると文字化けの原因となるため、アプリケーションを記述する場合にも注意するとよい。
ianaのShift_JISでは機種依存文字は対象外となっているため、WindowsのシフトJIS(Cp932)を扱う場合、Windows-31Jを使用するのが規格上は正しい。しかし、Windows上のInternet ExplorerやNetscapeなどではShift_JISと指定した場合でも機種依存文字は表示できる。このため、Shift_JISの方が一般的に使われているのが実情である。
暗黙の文字コード変換には要注意
JSPのコンパイルでは、JSPファイル→Javaソース(Servlet相当)→classファイルという2段階のコンパイルが発生する(以後、前者のコンパイルをJSPC、後者のコンパイルをjavacと記述する)。
そのため、開発者から見るとJSPをコンパイルして表示するという単純な処理であるが、実際には以下のように4回のコード変換が発生していることになる。
(1) JSPCでJSPファイルを読み込むとき(入力)
(2) JSPCの結果Javaのソースコードに出力するとき(出力)
(3) javacでJavaのソースコードを読み込むとき(入力)
(4) コンパイル後、実行結果をHTTPレスポンスとして出力するとき(出力)
※JSPCはJavaのアプリケーションの1つであるため入出力時にコード変換が起こる
このケースのように、単純に見える処理でも内部的に複数のコード変換が実行されていることがある。特に別の市販製品と組み合わせて利用する場合には、内部で独自のコード変換が行われている場合もあるため、注意が必要である。
そこで、どの段階で文字化けが発生するのかを確認するために、まずはJSPCにより生成されたJavaのソースコードを確認した。しかし、以下のように“(株)”の文字は文字化けしておらず、MS932で出力されている。これにより、JSPCの段階では文字化けが発生していないことが分かった。
out.print("\r\n<html>\r\n<head>\r\n</head>\r\n<body>\r\n<BR>?NTTデータ\r\n</body>\r\n</html>\r\n"); |
デフォルトエンコーディングにも注意せよ
JSPからJavaソースコードへの変換時には文字化けが発生していなかったため、javacでのエンコーディングの指定を確認した。その結果、javacのときにエンコーディングオプションが設定されていないことが判明した。Javaでは起動するユーザーのLANGの設定により、デフォルトのエンコーディングが決められている。この事例ではLANGの設定をja_JP.PCKとしていたためSJISが利用された。つまりMS932のソースコード(JSPCの結果ファイル)をSJISでコンパイル(javac)したために文字化けが発生していたことになる。
SolarisのJDK 1.3の場合、LANGの設定をja_JP.SJISとするとデフォルトエンコーディングはSJISとなる。明示的にエンコーディングを指定しないと、文字化けが発生する原因となりやすいため注意が必要である。
解決策
原因は、javacでencodingオプションを明示的に指定していないことであった。そこで、javacのコンパイルオプションを指定できるパラメータの設定を行った(weblogic.xml内のjsp-descriptorのcompileFlagsに-encoding MS932を追加する)。しかし、実行時にはうまくパラメータが渡らず文字化けを回避できなかった。
試行錯誤の結果、JSPC時のencodingオプションにMS932としていた設定(weblogic.xml内のjsp-descriptorのencodingパラメータ)を外すことで解決できた。このオプションを指定しない場合、JSPCでソースコードを出力するときにJavaVMのデフォルトエンコーディング(SJIS)が使用されるが、このとき“(株)”などのコード変換できない文字は、Unicodeエスケープしてくれるのである。Unicodeエスケープされた文字列はjavacでコンパイルするときに特別に扱われ、コードから直接String型の文字列になるため、SJISでjavacのコンパイルをしても文字化けが発生しない。
out.print("\r\n<html>\r\n<head>\r\n</head>\r\n<body>\r\n<BR> |
後の調査結果では、WebLogic 6.1 sp2ではプリコンパイル時にパラメータがうまく渡らないという問題があり、sp3で修正されていることが判明した。よって、sp3では、上記で説明したエンコーディングパラメータをMS932に統一することで解決できる。しかし、weblogic.xml内のjsp-descriptorのencodingパラメータは、J2EE仕様にはないアプリケーションサーバ独自の機能であり、その使用は推奨されていない。よって、特に問題がなければ、上記対策で示したように明示的に指定しないのがよいと考える。
今回のケースは、アプリケーションサーバ特有のケースである。しかし、文字化けが発生した場合には、本稿で説明したような確認ポイントを丹念に調査することが解決への糸口となる。
著者プロフィール
岡部 隆之(おかべ たかゆき)
現在、株式会社NTTデータビジネス開発事業本部に所属。 技術支援グループとして、J2EEをベースにしたWebシステム開発プロジェクトを対象に、技術サポートを行っている。特に、性能・信頼性といった方式技術を中心に活動中。
- ファイルアップロード/ダウンロードに潜むわな− 大容量、高負荷時の注意点 −
- ブラウザキャッシュでパフォーマンス向上―負荷分散装置の落とし穴に注意−
- JDBC接続を高速化する− PreparedStatementキャッシュの威力−
- レスポンスキャッシュでパフォーマンス向上―アプリケーションを変更せず性能UPする魔法のつえ―
- メモリは足りているのに“OutOfMemory”
- 文字化け“???”の法則とその防止策
- 低負荷なのにCPU使用率が100%?
- APサーバからの応答がなくなった、なぜ?―GCをチューニングしよう―
- サービス中にアプリケーションを入れ替える―クラスタ機能を活用しよう―
- マルチスレッドのいたずらに注意―あなたのJSPやServletは大丈夫?―
- クラスタは何台までOK?―性能から見たWebLogicクラスタの適正台数―
- キャッシュが性能劣化をもたらす“なぞ”を解く― データのキャッシュとコネクションプール ―
- クラスタ化すると遅くなる?― HttpSessionへの積み過ぎに注意 ―
Copyright © ITmedia, Inc. All Rights Reserved.




![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。