表の結合を極めるチューニング・テクニック:Oracle SQLチューニング講座(10)(2/4 ページ)
ソート/マージ結合
次に図3の「USE_MERGE」ヒントを使用したソート/マージ結合の結果を見てみましょう。列に索引が存在し、NOT NULL制約が存在する場合、索引スキャンを行うことでソート処理をスキップできます。「SUPPLIER」表は件数も少ないため、「PK_SUPPLIER」索引を使用した全索引スキャンが行われ、ソート処理がスキップされています。一方、「LINEITEM」表は件数が多いため、索引を使用せずに、全表スキャンが行われています。強制的に索引を使用させた場合、図2の場合と同様、非常に長い時間がかかることになります。
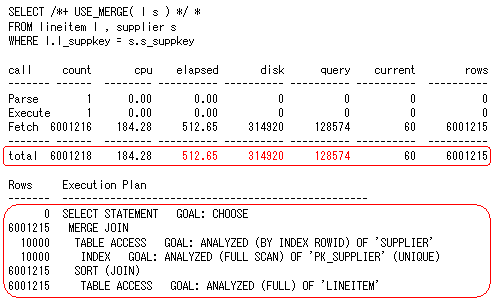 図3 ソート/マージ結合の場合
図3 ソート/マージ結合の場合実行統計の「query」の値を見ると、ネステッド・ループ結合(図1)の約1200万ブロックに対し、ソート/マージ結合では約12万ブロックと大幅に減少しています。これは、ソート/マージ結合の場合、各表のブロックは、全表スキャン、または索引フルスキャンによって一度だけ読み込まれるためです(索引スキャンの場合、同一のブロックが何回も読み込まれることになります)。ただし、ソート/マージ結合では、「disk」の値が増加しており、「query」の値を上回っています。これはディスクソート注1 が行われたことを示しています。「disk」の値のうち、どの程度のブロックがディスクソート処理で読み込まれたかは、v$sesstatビューの「physical reads direct」の値により確認できます。この例では、「physical reads direct」により約20万ブロックが読み込まれており、実際に読み込まれたブロックの総数は、約32万(12万+20万)ブロックとなっています。

ハッシュ結合
最後に、図4の「USE_HASH」ヒントを使用したハッシュ結合の結果を見てみましょう。
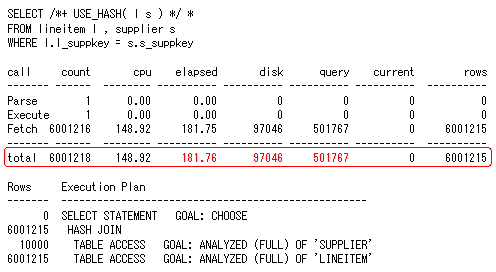 図4 ハッシュ結合の場合
図4 ハッシュ結合の場合「query」の値は、図3のソート/マージ結合での読み込みブロック数約32万ブロックに対し、ハッシュ結合は約50万ブロックと多くなっていますが、「elapsed」「disk」の値はハッシュ結合の方がかなり小さくなっています。ハッシュ結合では、ソート/マージ結合のようなソート処理は行われず、結合条件列である「SUPPLIER」表の「s_suppkey」列をメモリ上のハッシュ表に展開します。その後、もう一方の「LINEITEM」表の「l_suppkey」列をスキャンし、作成されたハッシュ表と結合して結果を返します。
結合方法別のパフォーマンス評価
図5は各結合方法による実行時間、アクセスブロック数の結果をグラフにしたものです。
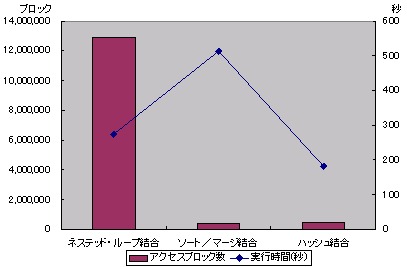 図5 結合方法別の実行時間とアクセスブロック数
図5 結合方法別の実行時間とアクセスブロック数3つの結合方法の処理時間を比べてみると、ハッシュ結合の場合が、最も処理時間が短くなっています。ネステッド・ループ結合では内部表を索引スキャンしますが、索引スキャンは表の大部分のレコードを取得する処理では、全表スキャン以上に時間がかかってしまいます。そのため、表の大部分を結合するような処理には向かないといえます。また、ソート/マージ結合は、双方の表を全表スキャンによるマルチブロック読み込みを行う点ではハッシュ結合と同様ですが、その後ソート処理という負荷の高い処理を行わなければならないため、処理に時間がかかってしまっています。
これらの点から、件数が多い表の大部分のデータを取得するような等価結合を行う場合には、ハッシュ結合が優れていることが分かります。
Copyright © ITmedia, Inc. All Rights Reserved.




![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。