高負荷なのに片方のサーバにだけ余裕が……なぜ?:Linuxトラブルシューティング探偵団(1)(4/4 ページ)
トラブル対処法はmod_jk振り分け方法の変更
このように、常にサーバへの負荷が掛かり続けるような状況では、アクセス数がほぼ均等に割り振られていると、初めのうちはわずかな誤差が、最終的にはかなり大きなCPU使用率の差として表れてしまうようです。この問題への対処法としては、mod_jkの振り分け方法を変更するのがよさそうです。
■mod_jkの振り分けメソッド
mod_jkでは、振り分けを行う方法(method)をいくつかの方式の中から選択することができます。このmethodを変更することで、今回のトラブルに対処できると考えました。
デフォルトでは、リクエスト数に基づいて振り分けを行います。具体的には、workers.propertiesで以下の設定を行います。
worker.list=workerlb |
| 設定項目 | 値 | 意味 |
method |
R[equest] |
リクエスト数によって振り分ける。デフォルト |
S[ession] |
Sessionを持ったリクエスト数によって振り分ける。 Sessionがないリクエストは、振り分け数の低い ワーカに送る |
|
T[raffic] |
mod_jk←→Tomcat間のトラフィック (read、write量)によって振り分ける |
|
B[usyness] |
現在処理している数(mod_jk←→Tomcat間の 接続数)によって振り分ける |
今回の場合は、ネットワークトラフィックが原因となって処理時間が遅延しているわけでもなく、すべてのクライアントが同じ画面遷移を繰り返すのでSessionにも差が出ません。よって「Busyness」を選ぶのが有効だと考えました。
method=Bにすることで、そのときのTomcatのリクエストの滞留数に基づいて振り分けが行われます。もしリクエストの処理時間が遅くなった場合、滞留数の少ない(CPU負荷が低い)方へ振り分けられることになります。実際に設定を変更し、再試験を行ったところ、結果は以下のとおりになりました。
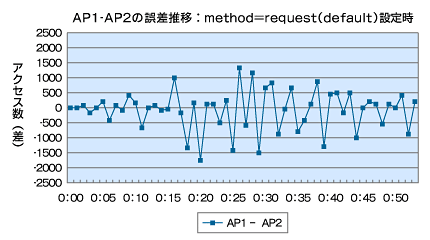 図6 method=Request(default)での誤差推移グラフ
図6 method=Request(default)での誤差推移グラフ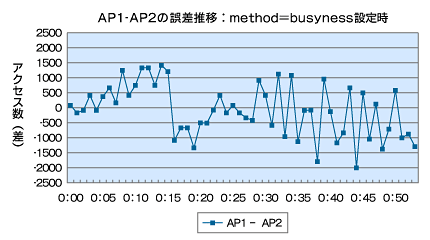 図7 method=Busynessでの誤差推移グラフ
図7 method=Busynessでの誤差推移グラフこうして見ると、一時的にアクセス数は偏りますが、その後、逆のアプリケーションサーバへ優先して振り分けられるように動いています。CPU使用率も両方のアプリケーションサーバで同じような値に落ち着きました。
これにて一件落着
以上のことから、常に負荷の高い状態が続くようなアプリケーションで、APサーバの負荷が偏ってしまう場合は、mod_jkの振り分け方法(method)の変更が有効であることが分かりました。
やはりトラブルの解決には、「情報の収集と整理」が必要です。原因を特定する前段階として、「どこから手を付けるのがいいのか?」を考える手掛かりにもなるので、とても重要なことです。これらを踏まえて優先順位を付けることで、対処の方針がおのずと明らかになります。場合によっては、トラブルの難易度や緊急性、重要度などを考慮し、原因の特定を後回しにして対処を優先することもあります。
いずれにせよ、普段から「トラブルは起こるもの」と考え、必要そうなログを事前に収集するなどの準備をしておくと、トラブル解決の助けになるはずです。
Copyright © ITmedia, Inc. All Rights Reserved.




![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。