業務処理で実行されるビジネスロジックの実装・設定ファイル定義をします。
まず、ビジネスロジック内でSQLを実行する際に必要となるクラスを作成します。今回、ビジネスロジック内では残高テーブルからデータを取得し、そのデータを基にテーブルに対して更新・新規追加をするわけですが、ここで作成するクラスは、データ取得時はSQLの結果格納クラス、更新・新規追加時にはSQLのパラメータクラスとなります。
「source」フォルダ配下に「jp.terasoluna.batch.sample.uc0002.JB0001zandakaData.java」を以下のとおり作成します。
package jp.terasoluna.batch.sample.uc0002;
public class JB0001zandakaData {
/**
* 顧客ID
*/
private String kokyakuid = null;
/**
* 残高
*/
private int zandaka = 0;
……(省略、各フィールドのsetter/getterメソッドの記述)……
} |
次に、先ほどと同様に、「UC0002_sqlMap.xml」にSQL文を定義します。使用するSQLは「残高を取得するSQL」「残高テーブルを更新するSQL」「残高テーブルにレコードを新規追加するSQL」の3つです。以下の定義を<sqlMap></sqlMap>内に追加します。
<!-- ビジネスロジック -->
<select id="getZandakaData" parameterClass="java.lang.String"
resultClass
="jp.terasoluna.batch.sample.uc0002.JB0001zandakaData">
SELECT ZANDAKA FROM ZANDAKATABLE WHERE KOKYAKUID = #value#
</select>
<update id="updateZandakaData" parameterClass
="jp.terasoluna.batch.sample.uc0002.JB0001zandakaData">
UPDATE ZANDAKATABLE SET ZANDAKA = #zandaka# WHERE KOKYAKUID =
#kokyakuid#
</update>
<insert id="insertZandakaData" parameterClass
="jp.terasoluna.batch.sample.uc0002.JB0001zandakaData">
INSERT INTO ZANDAKATABLE(KOKYAKUID, ZANDAKA) VALUES (#kokyaku
id#,#zandaka#)
</insert> |
select文を定義するときと同じ要領で、update文やinsert文を定義します。SQL実行時に、parameterClass要素に記述したクラスのフィールドの値をSQL文のパラメータに埋め込むことができ、どの値を埋め込むかは「#フィールド名#」と指定します。プリミティブ型のラッパークラスについては「#value#」と指定します。
続いて、ビジネスロジッククラスを作成します。今回は、型パラメータに「JB0001nyukinData」と 「JB0001JobContext」を指定します。「source」フォルダ配下に「jp.terasoluna.batch.sample.uc0002.JB0001BLogic.java」を以下のとおり作成します。
package jp.terasoluna.batch.sample.uc0002;
import jp.terasoluna.fw.batch.openapi.BLogic;
import jp.terasoluna.fw.batch.openapi.BLogicResult;
import jp.terasoluna.fw.batch.openapi.ReturnCode;
import jp.terasoluna.fw.dao.QueryDAO;
import jp.terasoluna.fw.dao.UpdateDAO;
public class JB0001BLogic implements
BLogic<JB0001nyukinData, JB0001JobContext> {
// DAOクラス。Springによりインスタンスが生成され設定される
private QueryDAO queryDAO = null;
private UpdateDAO updateDAO = null;
// ビジネスロジックを実行する
public BLogicResult execute(JB0001nyukinData nyukinData,
JB0001JobContext jobContext) {
// 残高テーブルに入金データの顧客IDにひも付くデータが
// 存在するか確認
JB0001zandakaData zandakaData
=
queryDAO.executeForObject("UC0002.getZandakaData",
nyukinData.getKokyakuid() , JB0001zandakaData.class);
// 該当レコードがある場合は残高計算と更新
if (zandakaData != null) {
int zandaka = zandakaData.getZandaka()
+ nyukinData.getNyukin();
zandakaData.setZandaka(zandaka);
zandakaData.setKokyakuid(nyukinData.getKokyakuid());
updateDAO.execute(
"UC0002.updateZandakaData", zandakaData);
// 更新件数のカウントアップ
jobContext.incrementUpdateCount();
// 該当レコードがない場合は新規作成
} else {
zandakaData = new JB0001zandakaData();
zandakaData.setKokyakuid(nyukinData.getKokyakuid());
zandakaData.setZandaka(nyukinData.getNyukin());
updateDAO.execute(
"UC0002.insertZandakaData", zandakaData);
// 新規追加件数のカウントアップ
jobContext.incrementInsertCount();
}
// ビジネスロジック処理結果オブジェクトを返却する
return new BLogicResult(ReturnCode.NORMAL_CONTINUE);
}
……(省略、各フィールドのsetterメソッドの記述)……
} |
「QueryDAO」クラスと「UpdateDAO」クラスはTERASOLUNAが提供しているDAO(Data Access Object)で、内包しているSpringの機能によってDI(Dependency Injection、依存性の注入)されます。
「QueryDAO」は参照系(select文)を実行する際に利用するDAOで、executeForObjectメソッドは取得する結果が1件の場合に利用します。第1引数にsqlMapファイルで定義したSQL文のid、第2引数にパラメータのオブジェクト、第3引数に結果格納オブジェクトのClassクラスを渡します。
「UpdateDAO」は更新系(update文、insert文、delete文)を実行する際に利用するDAOです。第1引数にsqlMapファイルで定義したSQL文のid、第2引数にパラメータのオブジェクトを渡します。
また、ジョブBean定義ファイルに上記で作成したビジネスロジックを利用する定義を追加します。以下の定義を<beans></beans>内に追記してください。
<!--ビジネスロジック-->
<bean id="blogic"
class="jp.terasoluna.batch.sample.uc0002.JB0001BLogic">
<property name="queryDAO" ref="queryDAO" />
<property name="updateDAO" ref="updateDAO" />
</bean> |
Bean要素のネスト内にSpringでDIするインスタンスを設定します。ここでは、「queryDAO」「updateDAO」をDIしています。「queryDAO」「updateDAO」のインスタンスの定義はフレームワークにて別途設定されているので、業務開発者は意識する必要はありません。
また、「blogic」「queryDAO」「updateDAO」はTERAバッチが提供する固定のBeanなので、名称の変更はできません。
ジョブの前処理・後処理は、メインとなるビジネスロジックのループ(業務処理)の前後に実行される処理で、ちょっとした処理を実行したいときに利用するものです。
ここで注意すべき点は、ビジネスロジック1回ごとに呼び出されるのではなく、ビジネスロジックのループが開始される前、ループが終了した後に前処理・後処理がそれぞれ1回呼ばれるという点です。
今回は、ジョブ後処理のみ実装してみましょう。「source」フォルダ配下に「jp.terasoluna.batch.sample.uc0002.JB0001JobPostLogic.java」を以下のとおり作成します。
package jp.terasoluna.batch.sample.uc0002;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import jp.terasoluna.fw.batch.openapi.BLogicResult;
import jp.terasoluna.fw.batch.openapi.ReturnCode;
import jp.terasoluna.fw.batch.openapi.SupportLogic;
public class JB0001JobPostLogic
implements SupportLogic<JB0001JobContext> {
/**
* ログクラス
*/
private static final Log log
= LogFactory.getLog(JB0001JobPostLogic.class);
/**
* ジョブ後処理を実行する。
* @param jobContext ジョブコンテキスト
*/
public BLogicResult execute(JB0001JobContext jobContext) {
//更新件数と新規追加件数をログ出力する。
log.info("更新件数は"
+ jobContext.getUpdateCount() +"です。");
log.info("新規追加件数は"
+ jobContext.getInsertCount() +"です。");
//ビジネスロジック処理結果オブジェクトを返却する。
BLogicResult result = new BLogicResult(
ReturnCode.NORMAL_CONTINUE);
return result;
}
} |
ジョブ前処理・後処理の実装ルールはビジネスロジックの実装ルールと非常に似ています。
ジョブ前処理・後処理クラスは、「SupportLogic」インターフェイスを実装し、ジェネリック型の第1パラメータにはジョブコンテキストクラスを指定します。ビジネスロジックと異なり、業務入力クラスに対する処理は行わないので、当然ジェネリック型、メソッドの引数に業務入力クラスを指定しません。処理の最後に、ビジネスロジックと同様に、リターンコードとして「NORMAL_CONTINUE」を指定します。
最後に、ジョブBean定義ファイルに上記で作成したジョブ後処理を利用する定義を追加します。以下の定義を<beans></beans>内に追記してください。
<!--ジョブ後処理-->
<util:list id="jobPostLogicList">
<bean
class="jp.terasoluna.batch.sample.uc0002.JB0001JobPostLogic"
/>
</util:list> |
それでは、実際に動かしてみましょう。Eclipse上でJavaアプリケーションとして起動します。
前回と同じ要領で、Eclipseの[実行]ダイアログを開き、[メイン]タブの[プロジェクト]に「terasoluna-batch-sample-foratmarkit03」を指定、[メイン・クラス]にTERAバッチが提供する「jp.terasoluna.fw.batch.springsupport.init.JobStarter」を指定します。
そして、[引数]タブの[プログラムの引数]において、第1引数にジョブID「JB0001」、第2引数にジョブBean定義ファイルのパス「sample/UC0002/JB0001.xml」を入力して、実行します。以下のように、ジョブの起動・終了に加え、処理件数のログが出力されれば、成功です。
[2008/05/18 22:43:25] [JobStarter ] [DEBUG] START Batch
[2008/05/18 22:43:26] [JobRequestInfo ] [DEBUG] Parameter values: [jobId=JB0001] [jobDiscriptPath=sample/UC0002/JB0001.xml] [parameters=[]] [jobRequestNo=]
[2008/05/18 22:43:26] [JobExecutor ] [INFO ] Job processing START : [jobId=JB0001] [jobRequestNo=] [StartType=SYNC]
[2008/05/18 22:43:26] [EndFileChecker ] [DEBUG] JB0001 jobstatus was added to the map.
[2008/05/18 22:43:26] [JobManager ] [INFO ] Job processing START: [jobId=JB0001] [jobRequestNo=] [partitionNo=-1] [partitionKey=NO_Partition] [JobManagerName=chunkTransactionJobManager] [JobState=STARTED]
[2008/05/18 22:43:26] [StandardCollectorResultHandler] [INFO ] Collector processing result code is NORMAL_END : [jobId=JB0001] [jobRequestNo=] [partitionNo=-1] [CollectorResult Info:ReturnCode: NORMAL_END ]
[2008/05/18 22:43:26] [JB0001JobPostLogic ] [INFO ] 更新件数は30です。
[2008/05/18 22:43:26] [JB0001JobPostLogic ] [INFO ] 新規追加件数は20です。
[2008/05/18 22:43:26] [JobManager ] [INFO ] Job processing END: [jobId=JB0001] [jobRequestNo=] [partitionNo=-1] [partitionKey=NO_Partition] [JobManagerName=chunkTransactionJobManager] [JobState=ENDING_NORMALLY]
[2008/05/18 22:43:26] [EndFileChecker ] [DEBUG] JB0001 jobstatus removed from the map.
[2008/05/18 22:43:26] [JobExecutor ] [INFO ] Job processing END : [jobId=JB0001] [jobRequestNo=] [StartType=SYNC] [jobExitCode=0]
[2008/05/18 22:43:26] [JobStarter ] [DEBUG] END Batch |
また、残高テーブルが以下のように更新されていることを確認してください。
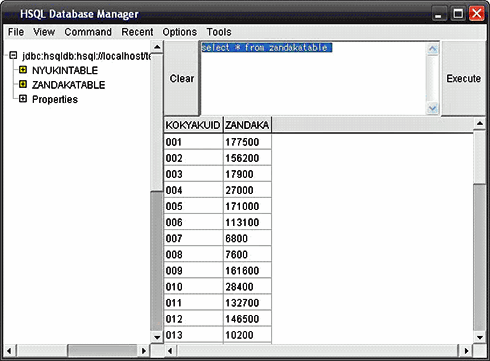 図5 処理後の残高テーブルの確認例
図5 処理後の残高テーブルの確認例 今回は、DBからデータを読み込み、ビジネスロジックを呼び出すアプリケーションを実装しました。HelloWorldアプリケーションでは触れなかったTERAバッチの利用方法について理解していただけましたか?
TERAバッチは、Spring Framework(DIコンテナ)、iBATIS(O/Rマッピングツール)をはじめとした多くの標準的なオープンソースのプロダクトを組み合わせて作られています。そのため、これらの機能の知識がある場合は、学習コストもさほど掛かりませんし、Spring FrameworkやほかのTERASOLUNAフレームワークを利用したアプリケーションなどとの連携・モジュールの共通化も可能です。
次回は、最終回です。TERAバッチの特徴的、重要な機能について紹介していきます。なお、今回作成したアプリケーションのファイルは、SourceForgeからダウンロードできます。



