減り続ける利用可能メモリ……そしてついにリブート!:Linuxトラブルシューティング探偵団 番外編(2)(1/3 ページ)
NTTグループの各社で鳴らした俺たちLinuxトラブルシューティング探偵団は、各社で培ったOSS関連技術を手に、NTT OSSセンタに集められた。普段は基本的にNTTグループのみを相手に活動しているが、それだけで終わる俺たちじゃあない。
ソースコードさえあればどんなトラブルでも解決する命知らず、不可能を可能にし、多くのバグを粉砕する、俺たちLinuxトラブルシューティング探偵団! 助けを借りたいときは、いつでもいってくれ!
OS:高田哲生
俺はリーダー、高田哲生。Linuxの達人。俺のようにソースコードレベルでOSを理解している人間でなければ、百戦錬磨のLinuxトラブルシューティング探偵団のリーダーは務まらん。
Web:福山義仁
俺は、福山義仁。Web技術の達人さ。ApacheのようなWebサーバからTomcat、JBossみたいなJava、アプリケーション技術まで、何でも問題を解決してみせるぜ。
DBMS:下垣徹
下垣徹。PostgreSQLの達人だ。開発からサポートまで何でもやってみせらぁ。でも某商用DBMSだけは勘弁な。
HA:田中 崇幸
よぉ! お待ちどう。俺さまこそHAエキスパート。Heartbeatを使ってクラスタを構成する腕は天下一品! HAが好きなんて奇人? 変人? だから何? HaHaHaHa!!
番外編第1回では、メモリ使用量についての基本的な考え方を説明した。今回は何かと誤解の多い、仮想メモリと物理メモリの違いを中心に説明するぜ!
それでも減り続ける使用可能メモリ
第1回「減り続けるメモリ残量! 果たしてその原因は!?」で紹介したとおり、メモリに関するトラブルについて顧客に回答を返してから数日……。同じプロジェクトから、さらに追加の質問が来ました。
「いわれたとおり/proc/meminfoを確認してみたが、MemFree+Inactiveも減り続けており、swapも出続けている。これはどういうことか?」
MemFreeとInactiveが減るということは、システムで利用可能な物理メモリ使用量が減ってきていることを意味します。これが進行すると、大変なことになるのでは!? 不穏な空気を感じ取ったわれわれは、新たに取得した/proc/meminfoのログを基に調査を始めたのですが、そこに追い打ちを掛けるように1本の電話がかかってきたのです!
「システムの利用可能なメモリがなくなってリブートした。原因を究明してほしい」
問題は新たな、より深刻なフェーズに移ったようです。これはもうログを見ているだけではらちが明かないので、われわれは現地に赴き、事情を聞くことにしました。
まずは事情聴取。犯人は誰だ!?
現地に到着したわれわれは、まずシステム構成についてヒアリングを行いました。ここで聞き出すことができた情報は図1、表1、表2のようなものでした。
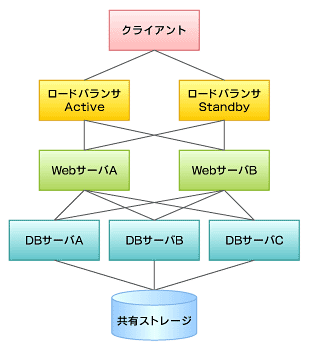 図1 システム構成図
図1 システム構成図
| 内容 | |
|---|---|
| Webサーバ | Apache |
| DBサーバ | Oracle 10g R2 |
| OS | Red Hat Enterprise Linux 4 AS Update2 |
| 表1 主なソフトウェア構成 | |
| サーバ | CPU | メモリ |
|---|---|---|
| Webサーバ | Dual Core Xeon×2 | 16GB |
| DBサーバ | Dual Core Xeon×2 | 48GB |
| 表2 ハードウェア構成 | ||
このうちリブートしたのは「DBサーバC」。よくよく聞いてみると、ここ数カ月のうちに何度か、1カ月や2カ月という間隔でリブートが発生しているとのこと。これは一大事です。
だいたいの情報は聞き出せたので、物証であるログファイルを用いた切り分けに入ります。ログにはほとんど何も残っていなかったのですが、HP製のサーバ製品「PSP」(注1)を導入することで利用できる「hplog」により、以下のようなログを取得できました。
ASR Detected by System ROM
このログの意味は、HP製のサーバ製品に搭載されている障害検知機能「ASR」(注2)が強制リブートを実施したことを示しています。
ASRはOSに対して定期的なシステムチェックを行っており、OSが数分間応答を返さないとハングアップしたと判断し、ハードウェアレベルで強制的にリブートを掛けます。どうやらリブート時には、OSがハングアップしており、ハードウェアからの状態検知を受け付けない状況になっていたようです。
しかし、たったこれだけの情報からリブート原因を探るのは非常に困難です。一口にOSのハングアップといってもいろいろあります。ハードウェアに対して、何が原因でハングアップしたのかを解析し、ログ出力しろというのは酷な話でしょう。
残りの原因解析はソフトウェアで何とかするしかないのですが、シリアルコンソールやクラッシュダンプの設定などをしない限り、「なぜハングアップしたか」は往々にしてログに残りません。それは、当たり前ですが「ログを記録するOSそのものがハングアップしているから」です。また、ハードウェアが故障して誤検知している可能性まで考慮に入れると、ハードウェア障害ログのみから原因を断定するのは非常に困難です。
残念ながら物証のみでは原因を特定できなかったので、状況証拠を集め、リブートの原因を類推してみましょう。状況証拠とはすなわち「お客さまの証言やリブートには直結しないログ」です。今回は、重要な証言が得られています。すなわち、
「いわれたとおり/proc/meminfoを確認してみたが、MemFree+Inactiveも減り続けており、swapも出続けている。これはどういうことか」
というやつです。ここでリブートしたサーバ(DBサーバ)の物理メモリ搭載量を思い出してみましょう(表2)。そう、48Gbytesもあるのです。これだけあるのにswap(スワップ、後述)が出続けるというのは、いかにもおかしい話です。しかも、リブート間隔は1〜2カ月ということなので、メモリ搭載量の設計に失敗したとも思えません。やはり、メモリを最重要容疑者にして問題を絞り込むのがよいでしょう。
注1:ProLiant Support Packの略。HPのサーバ用のドライバ、エージェント、ツールなどをまとめて導入・更新するためのユーティリティです。
注2:Automatic Server Recoveryの略。サーバ内部の高温状態やプロセッサボード障害、カーネル無応答状態などの異常を検知した場合に、自動的に再起動を行い、サーバを復旧する機能です。
Copyright © ITmedia, Inc. All Rights Reserved.




![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。