文字化けに関するトラブルに強くなる【実践編】:Oracleトラブル対策の基礎知識(6)(4/4 ページ)
補助文字(追加文字)とサロゲートペア
最後に、UnicodeにおけるJIS X 0213サポートにおいて注意すべき補助文字(追加文字)、サロゲートペアと呼ばれる概念について説明しておきます。
先に説明したとおり、Unicodeに含まれる文字は、「U+xxxx」という形式のコードポイントで管理されています。
コードポイントの範囲はさらに2つに分類されています。1つは、U+0000〜U+FFFFの範囲を指す基本多言語面(BMP:Basic Multilingual Plane)、もう1つは、U+10000〜の範囲を指す補助(追加)多言語(SMP:Supplementary Multilingual Plane)です。
JIS X 0208のすべての文字は基本多言語面に割り当てられていますが、JIS X 0213で追加された文字は、基本多言語面と補助(追加)多言語面のいずれかに割り当てられています。
ここで、補助(追加)多言語面に割り当てられた文字を、補助文字(追加文字)と呼びます。
補助文字(追加文字)は、JIS X 0208内の文字や、JIS X 0213の基本言語面に割り当てられた文字に比べて、データの保管に必要なbyte数が大きくなります(表2)。
| 文字の種類 | UTF-8 | UTF-16 | |
|---|---|---|---|
| JIS X 0208の漢字 | 3バイト | 2バイト | |
| JIS X 0213の漢字 | 基本言語面に割り当てられた文字 | ||
| 補助文字(追加文字) | 4バイト | 4バイト (サロゲートペアを使用) |
|
| 表2 文字の種類と必要なbyte数 | |||
特にUTF-16においては、補助文字(追加文字)はサロゲートペアと呼ばれる2つの文字を組み合わせて1つの文字として扱う仕組みを用いて表されるため、注意が必要です。
UTF-16では1つの文字を基本的に2bytes(=16bit)で表しますが、例外的に補助文字(追加文字)は、サロゲート領域と呼ばれる領域に割り当てられた特殊な文字2つの組み合わせであらわします。
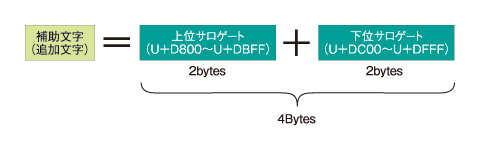 図7 補助文字(追加文字)とサロゲートペア
図7 補助文字(追加文字)とサロゲートペア例えば、JIS X 0213の補助文字(追加文字)の1つである「※」という文字は、UTF-8では0xF0A0808Bの4bytesとなります。また、UTF-16では0xD840DC0Bの4bytesとなります。
※
このとき、上位サロゲートはU+D840、下位サロゲートはU+DC0Bであり、図7に示したサロゲート領域に含まれていることが分かります。
文字コードによって格納時のバイト長が異なる
比較のため、表3に基本多言語面に含まれる文字「あ」と、補助(追加)多言語面に含まれる文字「※」をUTF-8、UTF-16で示した場合のbyte列とbyte長をまとめています。ここでは同じ文字でもbyte長が異なる点を理解してください。
| 文字 | コードポイント | UTF-8 | UTF-16 |
|---|---|---|---|
| あ | U+3042 | E3 81 82 (3バイト) |
30 42 (2バイト) |
| ※ | U+2000B | F0 A0 80 8B (4バイト) |
D8 40 DC 0B (4バイト) |
| 表3 基本多言語面の文字「あ」と補助(追加)多言語面の文字「※」 | |||
では、表3に示した2つの文字を、Windows Vista上で動作するSQL DeveloperからデータベースキャラクタセットAL32UTF のOracle Databaseに格納し(リスト1)、それぞれの文字が実際に表3に示したbyte列として格納されることを確認してみましょう(図8)。表4ではそれぞれの結果をまとめています。
create table test(col1 varchar2(4), col2 nvarchar2(4));
insert into test (col1, col2) values('あ','あ');
insert into test (col1, col2) values('※','※');
commit;
select col1, dump(col1,16), col2, dump(col2,16) from test;</pre></div>
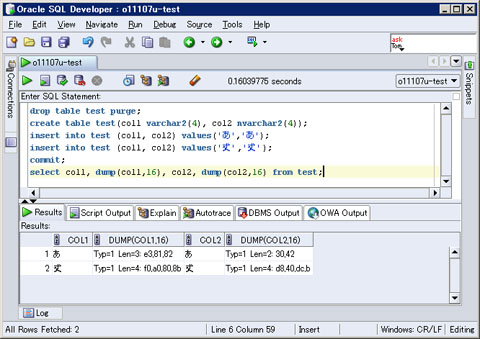 図8 SQL Developerでの実行例
図8 SQL Developerでの実行例| 文字 | COL1(varchar2型) | COL2(nvarchar2型) |
|---|---|---|
| あ | Typ=1 Len=3: e3,81,82 | Typ=1 Len=2: 30,42 |
| ※ | Typ=1 Len=4: f0,a0,80,8b | Typ=1 Len=4: d8,40,dc,b |
| 表4 dump()の実行結果 | ||
dump()の結果を見ると、VARCHAR2型のカラムには、通常のマルチバイト文字である「あ」は3bytesのデータとして格納されています。
一方、補助文字(追加文字)は4bytesのデータで格納されていることが分かるでしょう。ここでは、データベースキャラクタセットはAL32UTF8ですから、VARCHAR2型のカラムのデータはUTF-8エンコーディングで格納されています。
NVARCHAR型で格納した場合の補助文字の扱いは
次に、NVARCHAR型のカラムでの格納状態を確認してみましょう。
なお、NCHAR、NVARCHAR2、NCLOBは各国語キャラクタセットと呼ばれる補完的なキャラクタセットでデータを格納するための文字データ型で、現在は基本的にAL16UTF16キャラクタセットのみが指定可能です注3。
注3:UTF8も指定可能ですが、使用は推奨されません。UTF8は過去の互換性維持のために存在します。
AL16UTF16はデータをUTF-16エンコーディングで格納します。なお、AL16UTF16はデータベースキャラクタセットには使用できないことに注意してください。
同じくdump()の結果から、NVARCHAR型のカラムには、通常のマルチバイト文字である「あ」は2bytesのデータとして格納されており、一方、補助文字(追加文字)である「※」は4bytesのデータで格納されていることが分かるでしょう。UTF-16は基本的に1文字が2bytesのデータとなりますが、補助文字(追加文字)は1文字をサロゲート領域の文字2つで表しているため、2文字分の4bytesのデータとなります。
このように、補助文字(追加文字)をOracle Databaseに格納した場合、必要なbytes数は、通常の文字よりも大きくなります。
データベースキャラクタセットにAL32UTF8を使用し、CHAR型、VARCHAR2型、CLOB型の長さセマンティクスがデフォルトのBYTEである場合は、カラムの最大サイズがバイト単位で制限されるため、注意が必要です。
また、NCHAR型、NVARCHAR2型、NCLOB型の場合は、デフォルトで長さセマンティクスがCHARであるにもかかわらず、サロゲートペアについては例外的に2文字分の領域を消費するため注意が必要です。
加えて、CHAR型、VARCHAR2型、NCHAR型、NVARCHAR2型の最大サイズは、カラムの定義によるサイズ指定によらず、最大4000bytesという制限が課せられるため、カラム定義上、サイズが大きいカラムが4000bytesを超えないように注意が必要です。
JIS X 0213の利用により、従来外字などの仕組みを用いて扱ってきた文字を汎用的な方法で扱うことができるようになりましたが、実装上の特徴から取り扱いには十分な注意が必要です。本章の記述がJIS X 0213対応のお役に立てば幸いです。
Copyright © ITmedia, Inc. All Rights Reserved.




![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。