素朴なBigtable、できること できないこと:分散Key-Valueストアの本命「Bigtable」(2)(2/2 ページ)
Bigtableは「検索」ができない!?
ではなぜ、Bigtableはこのようなケタ違いのスケーラビリティやコストパフォーマンスを実現できるのでしょうか。
その理由の1つは、前回も説明したとおり、それがRDBではなく「キーを指定して値を読み書きする」という、ごく単純な機能しかサポートしていないことにあります。よって、Bigtableの「テーブル」とRDBの「テーブル」は、名前こそ似ていますが、それらの機能や性質は大きく異なります。
Bigtableにできることは、以下の2種類の処理だけです。
【1】キーに基づく行のCRUD
「キーに基づく行のCRUD」とは、個々の行に割り当てられた「キー」を指定して、行のCRUD(追加、取得、更新、削除)を行うことです。このCRUDに際しては、ACID特性が保証されており、例えば2件の更新処理がある1行に集中してそれぞれが書き込んだ値が混在してしまうようなことは起きません。

なお、Bigtableでは複数行に渡るCRUDについてはACID特性が確保されませんが、App Engineでは、これを補う形で特定範囲内の複数行のACIDを保証する機能を提供しています。
【2】キーに基づく「スキャン」
一方、「キーに基づくスキャン」とは、キーの前方一致検索もしくは範囲指定検索により、複数の行を一括取得する機能です。以下の図3をご覧ください。
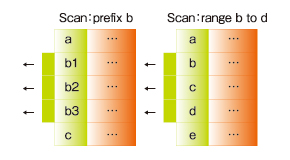 図3 「キーによるスキャン」の例(出典:グーグル「Under the Covers of the Google App Engine Datastore」Ryan Barrett著)
図3 「キーによるスキャン」の例(出典:グーグル「Under the Covers of the Google App Engine Datastore」Ryan Barrett著)このように、例えば「bで始まるキーを持つすべての行を取得」したり、「b〜dで始まるキーを持つすべての行を取得」したりできます。
どう動いてる? Bigtableの「中の人」
最後に、グーグルのクラウドの内部では、このBigtableがどのようなシステム構成によって実装されているのかを説明します(なお、以後紹介する内容は2006年時点で公開された情報に基づいているため、2009年9月現在は変更されている可能性もあります)。
Bigtableのデータは「タブレット」単位で分かれる分かれる
ご存じのとおり、グーグルのクラウドの特徴は、「高価な高性能サーバは使用せず、安価なPCサーバを大量に並べて負荷分散と高可用性を実現している」という点です。Bigtableはその典型例で、以下のようなグーグルの典型的なPCサーバ上で稼働しています。
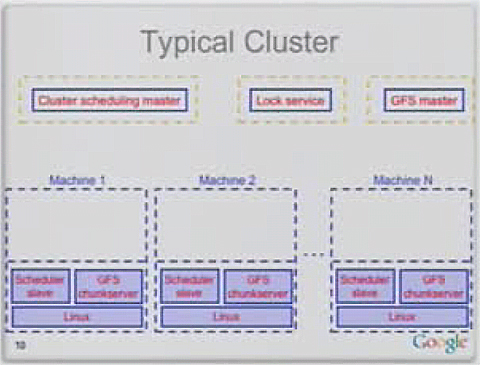 図4 グーグルのデータセンターにおける典型的なクラスタノード構成(引用元:グーグル「Big Table: A Distributed Structured Storage System」Jeff Dean著)
図4 グーグルのデータセンターにおける典型的なクラスタノード構成(引用元:グーグル「Big Table: A Distributed Structured Storage System」Jeff Dean著)グーグルのデータセンターには、こうしたPCサーバが数万台規模で並んでいます。これらのうち、Bigtableが稼働する個々のPCサーバは、以下のような構成になっています。
- Linux OS
- Bigtableタブレットサーバ
- GFSチャンクサーバ
「Bigtableタブレットサーバ」とは、Bigtableのテーブルのデータを100〜200Mbytes程度の大きさに分割した「タブレット」を管理するサーバです。1台のタブレットサーバは100個以下のタブレットを保存しますので、PCサーバ1台当たり約10〜20Gbytes程度を管理する計算になります。
タブレットサーバが管理するタブレットのデータは、先に述べたとおり分散ファイルシステムGFSの「チャンク」と呼ばれる形式で保存されます。このとき、タブレットサーバと同じPCサーバ上の(=ローカルの)「GFSチャンクサーバ」を優先して保存先に選びます。また、同じデータのコピーをほかの2つのGFSチャンクサーバにも保存します。
よって、例えば100個のタブレットを持つあるPCサーバがダウンしたり過負荷状態に陥っても、同じタブレットを持つほかの100台のPCサーバが処理を引き継ぐため、利用者がPCサーバの障害や過負荷に気付くことなくサービスを継続運用できる仕組みです。
Bigtableのキャッシュメカニズムはオーソドックス
またBigtableは、データモデルこそRDBとはまったく異なるものの、キャッシュメカニズムなどの内部構造は、意外にオーソドックスな設計となっています。
例えば、Bigtableのテーブルに対して読み書きされた内容は、まず「memtable」と呼ばれるメモリ上のキャッシュに保存し、一定間隔でディスクに保存する仕組みです(「minor compaction」)。もちろん、キャッシュ内容が失われる場合もあるので、読み書き履歴は「コミットログ(ジャーナルログ)」としてディスクにも保存されます。この辺りの仕組みは、例えばOracleデータベースのREDOログやDBWRプロセスなどのメカニズムとよく似ています。
また、GFS上へのデータを書き込む際には、PostgreSQLと同様に「既存のデータは一切変更せずに、変更内容を追記していく」という方式を採用しています。これによりロックの不要な読み込みアクセスや負荷分散を実現していますが、同時に定期的に削除済みデータをGC(ガベージコレクション)する仕組みも用意されています(「major compaction」)。これはPostgreSQLの「vacuum」と同様のメカニズムです。
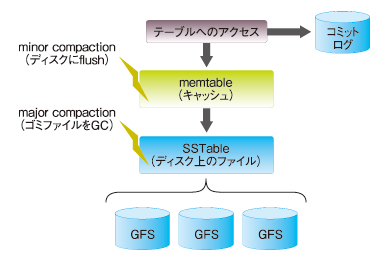 図5 Bigtableのキャッシュメカニズム
図5 BigtableのキャッシュメカニズムBigtableは“素朴”。だから、使い方が重要
Bigtableにできることは、これだけです。ちょっとびっくりするかもしれませんが、Bigtableでは「値を条件に行を検索する」という、RDBではごく当たり前の検索処理(クエリ)をまったくサポートしていません。「それでどうやってアプリケーションを実装するのだろう?」と疑問を持つ方も多いはずです。筆者もBigtableを学び始めたときは、そう思いました。
しかし、いくつかの手法を組み合わせることで、こんな“素朴”な仕様のデータストアであっても数多くのWebアプリケーションを実装可能です。実際、先に示したYouTubeやGoogleマップ、Google Earthといったメジャーなサービスは、いずれもこうした制約の範囲内でBigtableを駆使しながら豊富なサービス機能を実装しています。
またApp Engineでは、Bigtable上で簡単なクエリやCRUDを実装した「Datastore API」を提供しています。そこで次回は、このDatastore APIについて詳しく紹介し、現実的なWebアプリケーション開発ではBigtableをどのように使いこなせるのかを紹介する予定です。
著者プロフィール
吉川 和巳(よしかわ かずみ)
スティルハウス
Adobe AIR/Flex、Ruby on Rails、Google App Engine for Javaを主軸とする開発業務に従事しています。
関連記事
Copyright © ITmedia, Inc. All Rights Reserved.




![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。