Rによるオープン・データの可視化(1):実践! Rで学ぶ統計解析の基礎(3)(1/2 ページ)
今回はパブリックに入手可能な“オープン・データ”とRを使い、人口統計や株式相場などのデータを可視化します。自分の手を動かすことで、社会状況の把握や仮説の検証ができるのです。
オープン・データを図示・可視化する
今回から数回にわたって、比較的話題にされることが多い社会の状況を表すオープン・データを図示・可視化することをテーマとしたいと思います。
そういった公的なオープン・データは、いろいろな新聞、書籍、雑誌、Webサイト、論文などで取り上げられることが多いので、わざわざ可視化する必要がないという意見もあります。しかし、筆者の意見では、それだからこそ問題を自分の頭で考えるためのきっかけにするために、自分でデータを図示・可視化する必要があると思っています。すべての考察は自分が寄って立つ土台が必要で、その土台の検証を始めることで、いろいろな吟味、検討を行うに耐える足場を確認できます。そして、その確認作業の際に新たな知見を得ることも少なくありません。なにより、原データを知っていることで、自分の考察にブレが少なくなりますし、議論にも説得力が出てきます。
これはビジネスでも同様でしょう。消費者統計や自社の顧客の分析など、基本的なデータを常に自分で可視化して把握しておくことは、ビジネスプランの策定や、事業の舵取りといった面で、確かな足場を与えてくれるものとなるはずです。
また、今回の内容はわざわざRを用いなくてもExcelやほかのグラフ作成ツールで十分なものですが、「オープン・データを取り込み、図示・可視化し、そして統計解析する」という一連の流れを実践するための準備として、Rを利用することにします。
数量のパターン認識
人間の認知能力のうち一番優れているのは視覚で、特にパターン認識が優れているといわれています。普通の人間は数量的な情報を直接把握するよりも、パターンとして把握するほうが得意であるといわれています。グラフはチャートは数量的な情報をビジュアルな位置の情報に変更することで、パターン認識ができるように変換したものです。最近の研究では、人間がそのグラフやチャートのパターンから、そのプロットの位置関係や大きさ、そして角度を特によく捉えることができることが示されています。
Graphical Perception and Graphical Methods for Analyzing Scientific Data
William S. Cleveland and Robert McGill
Source: Science, New Series, Vol. 229, No. 4716 (Aug. 30, 1985), pp. 828-833
Graphical Perception and Graphical Methods for Analyzing Scientific Data
Graphical Perception and Graphical Methods for Analyzing Scientific Data(pdf)
ですから、人間のパターン認識能力を活用することで、統計解析ソフトウェアが出力する数値からだけでは分からない情報を捉えることができるよう、統計解析の最初にデータを図示・可視化することは必須だといえるでしょう。
Rにおける図示・可視化
Rは統計解析環境・ソフトウェアとして非常に優れたグラフ・チャート作成能力を持っています。組み込みのプロット関数だけでも以下のようにたくさんあります。
> apropos("plot")
[1] ".__C__recordedplot" "assocplot" "barplot"
[4] "barplot.default" "biplot" "boxplot"
[7] "boxplot.default" "boxplot.matrix" "boxplot.stats"
[10] "cdplot" "coplot" "fourfoldplot"
[13] "interaction.plot" "lag.plot" "matplot"
[16] "monthplot" "mosaicplot" "plot"
[19] "plot.default" "plot.density" "plot.design"
[22] "plot.ecdf" "plot.lm" "plot.mlm"
[25] "plot.new" "plot.spec" "plot.spec.coherency"
[28] "plot.spec.phase" "plot.stepfun" "plot.ts"
[31] "plot.TukeyHSD" "plot.window" "plot.xy"
[34] "preplot" "qqplot" "recordPlot"
[37] "replayPlot" "savePlot" "screeplot"
[40] "spineplot" "sunflowerplot" "termplot"
[43] "ts.plot"
> apropos("chart")
[1] "charToRaw" "chartr" "dotchart" "piechart" "stripchart"
これに加えて、数千を超える豊かな外部ライブラリには、そのグラフ作成能力を強化するためのライブラリが多数あります。前半の回では組み込みのグラフ作成関数(プロット関数)であるplot関数や、時系列データのプロット関数であるts.plotだけを用いてオープン・データを図示するようにし、後半の回では最近ユーザベースを特に増やしているggplot2というR向けのグラフィックライブラリを用いて図示することにします。
オープン・データを図示・可視化するときには、大きな注意点があります。Rのような統計解析ソフトウェアにオープン・データを読み込むためには、データを整形するという前処理が必ず必要になり、実はそれがかなり大変な作業である、ということです。というのも、オープン・データは最近はデジタルデータとして提供される場合が多いのですが、その提供の形にはいろいろな形式があって、それを統計解析ソフトウェアに取り込むのに苦労することが多いのです。もちろん、データのレイアウト(例えば時系列が行方向なのか列方向なのかなど)が、提供側によってマチマチなのは仕方ありません。しかし、それ以前の作業に大きな手間が必要になっているのが現状です。その問題点のうち、大きな問題のいくつかを以下で指摘します。
まず、ファイルのフォーマットに問題がある場合があります。最近は汎用的なテキストファイルであるCSVファイルで提供されることが多くなってはきています。しかし、中には公平性を担保するべき公的機関であるのにもかかわらず、特定営利企業の特定フォーマットで提供されている場合が少なくありません。特に日本の公的機関ではMicrosoft Excelで提供されている場合が非常に多く、網羅的には調べていませんが、いままで筆者が利用してきた限りでは、むしろ日本ではこのExcelでの提供がデフォルトのような気がします。これには、納税者として、税金の使い道について問い質したくなります。さらに、その中には1つのExcelファイルの中に、ワークシートがいくつも(中には20以上も)含まれている場合もあり、そのようなデータを手にしたときは、こんなトリックを使ってまで隠しごとをしたいのか、という不信感すら抱いてしまいます。
次に、CSVファイルで提供される場合でも罠があります。データ系列に対する注意書きは、本来は「メタデータ」として別途提供するべきだと思うのですが、その注意書きがCSVファイルに直接書き込まれている場合がほとんどです。ひどいケースになると、データ行のど真ん中に文字列として行が挿入されている場合もあります。こういうケースに行き当たった場合、そのデータを利用することをワザと妨げているのではないかと悪意すら感じてしまいます。
そして、データを提供するシステムにも問題が少なくありません。「政府統計の総合窓口」が典型的です。データをドリルダウンしながら探索的に検索していくという主旨は讃えるべきだとは思いますが、その際のデータを選択させるインターフェイスが稚拙で、レスポンスが遅いのにうんざりします。また、このシステムには珍妙なグラフ作成機能が存在しますが、これはグラフ作成という点からはあまり役に立たない代物となっていて、なぜこのようなシステムが作られたのか、疑問を抱かざるを得ません。今後は、このような不思議システムを税金を使って開発する事業については、ぜひとも事業仕分にて検討をして頂きたいものだと、政権与党の皆様にはお願いしたいと思います。
以上、要するに、データはコンピュータで作成されているのにもかかわらず、それをコンピュータで取り込むときには一筋縄ではいかないというおかしな状況を指摘しました。データを提供する側は、ソフトウェアに取り込めるような、広く汎用的なテキスト形式またはインターフェイスを公開したWebサービスの形式でデータを提供する、というコンセンサスがぜひとも必要だと思います。後者のWebサービスのインターフェイスについては、次回にて世界銀行の例を紹介します。あまりにスムーズにデータを取り込めるのでビックリされるでしょう。
それでは、オープン・データとしてのデータを具体的に取得し、図示・可視化するという作業を行います。最初は冗長ですが、少し細かくやってみたいと思います。
人口統計のプロットから出てくるハードファクト
現在の日本において、一番広域にかつ壊滅的な影響を及ぼす問題といえば、少子高齢化問題です。少子高齢化、つまり人口統計の老齢人口への偏りという問題に匹敵するような大問題は、ほかにあまりありません。この状況を図示・可視化することで問題の深刻度を確認したいと思います。
(注)本稿公開時に「人口動態」という言葉を使ってしまいましたが、これは誤りで、「人口統計」という言葉に修正いたしました。ご指摘くださった群馬大学医学部の中澤港様、ありがとうございました。
日本の人口統計は、複数の組織が公開していますが、将来の人口も考慮したいと思いますので、ここでは人口問題研究所のデータを利用することにします。最新のデータではありませんが、2006年推計のデータを利用したいと思います。
このページにおいて以下の2つのデータを入手します。1つは2005年までの総人口の実績値で、もう1つは2005年から2055年まで人口を推計したデータ(出生中位(死亡中位)推計)です。現在は2010年ですので、少なくとも2008年までの総人口の速報値が存在します。最新情報を利用するには、「政府統計の総合窓口」からそのデータを入手できますが、ここでは大体の傾向が分かれば十分ですので、人口問題研究所の2006年推計データをこのまま利用します。
資料表1 総人口、年齢3区分(0〜14歳、15〜64歳、65歳以上)別人口および年齢構造係数:1947〜2005年
表1-1 総人口、年齢3区分(0〜14歳、15〜64歳、65歳以上)別人口および年齢構造係数
これからやる作業は、この2つのデータをRに取り込むことができるように、(1)整形し、(2)Rに取り込み、(3)1つのデータとして結合し、(4)図示・可視化することです。
まずは(1)の整形作業です。
2つのデータフォーマットはExcel形式であるので、データを開いて確認するためにはMicrosoft ExcelかOpenOfficeが必要です。そして、それらのアプリケーションを利用して、Rでも直接利用することができる汎用的なCSV形式に変換します。ただ、このファイルを開いて確認すれば分かるのですが、このままCSVファイルに書き出してもすぐに使えません。注意書きが直接セルに書かれていことと、タイトルのセルが結合されているためです。タイトルセルの不必要な結合を解除し、空白のカラムを削除し、余計な注意書きをなくすという整形を加えた後に、CSVを書き出します。この加工してCSVに書き出したものを筆者のほうでGoogle Docsに上げておきました。
ここでこのCSVをダウンロードする必要はありません。Rにはインターネット上にあるCSVファイルを直接読み込む機能がread.csv関数にありますので、そのままリンクを利用します。Rすぐに利用できるCSVをGoogle Docsで公開する手順は、動画として以下にまとめておきました。参考にしてください。
それでは、(2)の手順のRへの取り込みとして、2つのCSVを読み込みます。Rのread.csv関数を利用し、オプションとしてタイトル行をカラムの名前とするようにheader=TRUEを指定します。read.csv関数で読み出されたものは、Rのデータフレームオブジェクトになります。
> demo1 <- read.csv("http://spreadsheets.google.com/pub?key=0AlBuJgqcP5f3dHRXUk5PYVMxdWtrOEt3aEwwR0d5Q0E&hl=en&single=true&gid=0&output=csv", header=TRUE)
> demo2 <- read.csv("http://spreadsheets.google.com/pub?key=0AlBuJgqcP5f3dGRvQU5jczhaaF9oQVNLY1ZQSHExRGc&hl=en&single=true&gid=0&output=csv", header=TRUE)
> head(demo1)
Nenji year total_new total X0_14 X15_64 X65_ X0_14_rate X15_64_rate X65_.1
1 S22 1947 78101 78101 27573 46783 3745 35.3 59.9 4.8
2 23 1948 80002 80002 28297 47863 3844 35.4 59.8 4.8
3 24 1949 81773 81773 29029 48775 3968 35.5 59.6 4.9
4 25 1950 83200 83200 29428 49658 4109 35.4 59.7 4.9
5 26 1951 84573 84573 29657 50734 4176 35.1 60.0 4.9
6 27 1952 85852 85852 29700 51844 4304 34.6 60.4 5.0
> head(demo2)
nenji year total X0_14 X15_64 X65_ X0_14_rate X15_64_rate X65_rate
1 H17 2005 127768 17585 84422 25761 13.8 66.1 20.2
2 18 2006 127777 17451 83729 26597 13.7 65.5 20.8
3 19 2007 127761 17305 83010 27446 13.5 65.0 21.5
4 20 2008 127703 17158 82334 28211 13.4 64.5 22.1
5 21 2009 127603 16971 81644 28987 13.3 64.0 22.7
6 22 2010 127463 16766 81285 29412 13.2 63.8 23.1
読み込んだデータを見ると分かるのですが、yearカラムが年を表し、totalカラムが総人口、X15_64カラムが15歳から64歳までの年齢別人口、X65_カラムが65歳以上の年齢別人口を表します。また、忘れてはいけないのは、2つのデータには同じ2005年のデータが含まれていて、そのまま結合すると重複が生じてしまうということです。
(3)の手順である、2つのデータを結合するには、"year", "total", "X15_64", "X65_"のカラムだけを取り出して新たなデータフレームとしたあとに、行方向への結合をします。カラムを抽出するにはsubset関数を利用します。データフレームを行方向へ結合するためにはrbind関数を利用します。
> demo <- rbind(subset(demo1, select=c("year", "total", "X15_64", "X65_")), subset(demo2, select=c("year", "total", "X15_64", "X65_")))
> subset(demo, demo$year==2005)
year total X15_64 X65_
59 2005 127768 84092 25672
60 2005 127768 84422 25761
> demo <- demo[-60, ]
> head(demo)
year total X15_64 X65_
1 1947 78101 46783 3745
2 1948 80002 47863 3844
3 1949 81773 48775 3968
4 1950 83200 49658 4109
5 1951 84573 50734 4176
6 1952 85852 51844 4304
重複していた2005年のデータは、推計値の60行目を取り除くことで対処しました。データ行を取り除くには、Rの添字スライス機能を利用します。コードにあるdemo[-60, ]という"-60"とカンマの指定がそれです。まず、角括弧"[x, y]"の意味は、x行目とy列目のデータを指定するということです。xやyを指定しない空白の場合は、その行や列全体を指定するということです。"[-60, ]"で、-60行目と列方向全部を指定ということです。添字のマイナス"-"指定は、その指定されたものだけを削除しろ、ということです。つまり"[-60, ]"で、60行目のデータを削除し、カラム方向はそのままにしろ、ということです。これを利用すれば、2005年の重複のない実績と推計を結合させたデータをそろえることができます。
最後に(4)の図示です。まず、総人口の実績値と推計値を1947年から2055年にわたってプロットします。プロットには、demoデータフレームにある、totalカラムとyearカラムを利用します。Rで2次元散布図プロットするにはplot関数を利用します。plot関数において、プロットするべきカラムを指定する方法は2つあって、1つは目的変数~従属変数と、チルダ"~"で変数を関係付けする方法です。もう1つは、従属変数, 目的年数というように、カラムを","で区切る方法です。ここでは変数を関係付ける方法を選択しました。また、データフレームの中のカラム変数を指定するためには、データフレームを明示的に指定した後にドルマーク"$"で区切る必要があります。
> plot(demo$total~demo$year, type="l") > abline(v = 2010, lty="dashed")
散布図のプロット点を線でつなぐために、plot関数のオプションtype="l"を指定しました。"l"は"line"でプロット点を結べ、ということです。また参考として、現時点の年を示す2010年の線を表すためにablineで垂直線を引いています。ablineはvで垂直線("v"ertical)、hで水平線("h"orizontal)を指定できます。
さて、この1947年から2055年にわたって総人口の実績値と推計値をプロットした図と、それを表示している様子は以下のとおりです。

これを見ると分かるのは、総人口は2005年くらいをピークに、あと40年もすると1970年のレベルにまで落ち込むだろうということです。総人口が減少していく……、実はこれはまだ序の口です。生産年齢である15歳から64歳の人口変化を見てみましょう。
> plot(demo$X15_64~demo$year, type="l") > abline(v = 2010, lty="dashed")
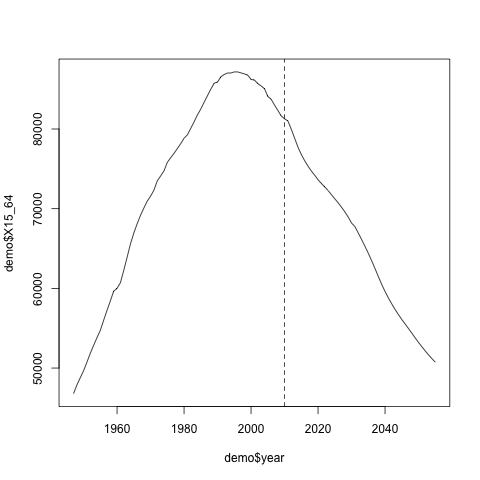
これを見ると分かるように、1995年あたりをピークに、すでに坂を転げ落ちるように生産年齢人口が下がっている真っ最中なのです。40年もすると高度経済成長期以前の人口レベルになってしまいます。これをさらに衝撃的にしたのが、高齢者と生産年齢の人口比をとった以下の図です。
plot(demo$X65_/demo$X15_64~demo$year, type="l") abline(v = 2010, lty="dashed")
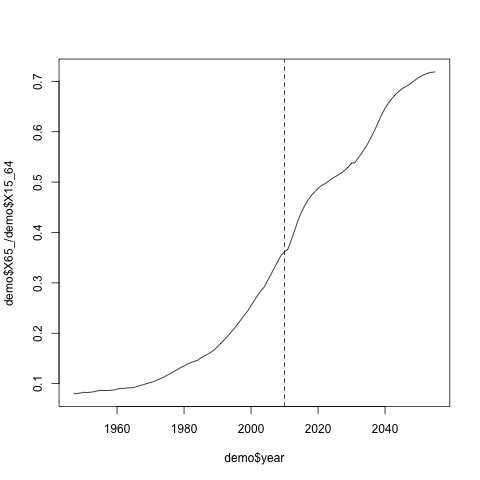
2010年は破線で表していますが、現在でも高齢者と生産年齢の人口比は0.36、つまり逆数をとって現役2.76人で高齢者1人を支える構造になっています。これが2055年には0.7になります。つまり現役1.4人で高齢者1人を支えるという、ある意味絶望的ともいえる数字になってしまいます。この状況では、政府や公共的な社会保障システムは頼りになるとはあまり言えないかもしれません。45年後といえば、現在35歳の働き盛りが80歳になる年です。
この人口統計の簡単な図示・可視化から分かるのは、自分たちがどのような行動を今から起こすべきか、ということを考えるための重要な手がかりです。今のまま事態が進行すると仮定すれば、生きている間じゅう自分の手で稼がなければ自分の生活を維持していけない、という厳しい予想を得ることができます。
そして、ある程度文化的な生活を生きている間じゅう続けるためには、70歳になっても80歳になっても現役で働き続けることができるような技術や能力、体力を維持するか、もしくは老後の生活に不安がないような十分な私有財産をどこかで築くか、ということになりそうです。いずれにしろ、あまり楽な話にはなりそうにありませんが、将来の状況を蓋然的につかむことができれば、その予想から逆算して、自分たちが起こすべき行動の範囲を狭めることができるとは言えるでしょう。
Copyright © ITmedia, Inc. All Rights Reserved.




![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。