僀儞僞乕儕儏乕僪: Twitter偲R丗幚慔両 R偱妛傇摑寁夝愅偺婎慴乮5乯乮1/2 儁乕僕乯
崱夞偼Twitter偲偄偆恎嬤側戣嵽傪巊偭偰丄R偵傛傞僨乕僞廂廤偲壜帇壔傪傗偭偰傒傑偡丅R偺朙晉側儔僀僽儔儕傪巊偊偽堄奜偵庤寉偵偱偒傑偡丅
崱夞偼娫憈揑偵IT婑傝偺榖戣傪
丂偙偺楢嵹偼仐IT偺楢嵹偱傕偐側傝栄怓偺堘偆撪梕偱偡丅偦傟偵傕偐偐傢傜偢慜夞傑偱偺4夞偼丄摑寁揑専掕傪偄偒側傝摫擖偟偨傝丄擔杮惌晎傗悽奅嬧峴偺宱嵪摑寁偵傾僋僙僗偟偰傒偨傝丄偝傜偵偼WikiLeaks偺朶業僨乕僞傪摑寁夝愅偟偰傒偨傝偲丄偐側傝僴乕僪僐傾側撪梕偵憱偭偰偟傑偄傑偟偨丅
丂戞4夞偺乽偁偲偑偒乿偱偼摨偠楬慄偱撍偭憱傠偆偲偄偆偙偲傪怽偟忋偘偰偄偨偺偱偡偑丄崱夞偼娫憈乮僀儞僞儕儏乕僪乯偲偟偰丄傛傝仐IT傜偟偔丄IT婑傝偺榖戣傪庢傝忋偘偨偄偲巚偄傑偡丅
Twitter偲R
丂Twitter偺恖婥偼悽奅揑偵傑偩傑偩懕偄偰偄傞傛偆偱偡丅2010擭8寧屻敿偵敪昞偝傟偨2010擭6寧暘偺摑寁偵傛傟偽丄尰嵼偼僀儞僪僱僔傾傗僽儔僕儖丄儀僱僘僄儔側偳偺怴嫽崙偺怢傃偑偡偛偄偦偆偱偡丅
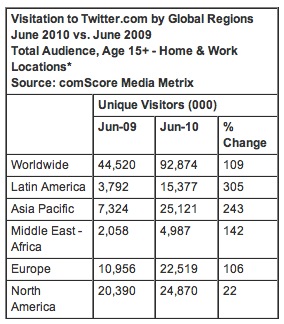
丂擔杮偱傕傑偩17亾偲偄偆媫惉挿傪懕偗偰偄傑偡丅暷崙偱偼Twitter偺惉挿偑巭傑偭偨偲偄偆榑峫偑壗搙傕弌偰偄傑偡偑丄幚偼儌僶僀儖傪娷傔偨摑寁傪尒傞偲丄偙偪傜傕傑偩傑偩怢傃戙偑廫暘側傛偆偱偡丅
丂偝偰丄偦偺恖婥偺Twitter偱偡偑丄偙偺傛偆偵儐乕僓乕偺悢傗棙梡昿搙偑戝偒偔側偭偰偔傞偲丄偩傫偩傫偲擔忢惗妶偵寚偔偙偲偺偱偒側偄幮夛娭學帒杮乮social capital丗幮夛偵偍偄偰恖乆偑帩偮恖娫娭學傗怣棅娭學偺偙偲乯偺僀儞僼儔僗僩儔僋僠儍乕偺傛偆側懚嵼偵側偭偰偒偰偄傞偲尵偊傞偱偟傚偆丅偁傞柺偱偼丄屄恖偺歯岲乮偟偙偆乯傗慖岲丄幮夛偺尰嵼偺僩儗儞僪側偳偑奿擺偝傟偰偄傞丄恖娫娭學媦傃屄恖偺歯岲偺娙堈揑側僨乕僞儀乕僗偲峫偊傞偙偲傕偱偒偦偆偱偡丅偦偺傛偆偵峫偊傞偲丄Twitter偺儐乕僓乕摨巑偺娭學傗擔乆傗傝偲傝偝傟傞朿戝側tweet傪僨乕僞儅僀僯儞僌傗僨乕僞夝愅偵棙梡偡傞偙偲偱桳梡側忣曬傪摼傞偙偲偑偱偒側偄偐丄偲偄偆峫偊偑弌偰偔傞偙偲偲巚偄傑偡丅崱夞偺婰帠偱偼丄僴乕僪僐傾側僨乕僞儅僀僯儞僌傗僨乕僞夝愅偼峴偄傑偣傫偑丄偦偺儅僀僯儞僌傗夝愅傪偡傞擖傝岥傑偱偺傾僾儘乕僠傪採帵偡傞偙偲傪栚揑偲偟傑偡丅
丂Twitter傪僨乕僞儀乕僗偲偟偰棙梡偟丄R傪巊偭偰偦偺僨乕僞夝愅傪偡傞偨傔偵偼丄R偲Twitter傪楢実偝偣傞昁梫偑偁傝傑偡丅偦偺偨傔偺僷僢働乕僕偑CRAN偵偁傝傑偡丅偦傟偑twitteR偱偡丅twitteR偼Twitter偺REST API傪儔僢僺儞僌偟偰偄傞僷僢働乕僕偱丄偙傟傪棙梡偡傞偲R傪Twitter偺僋儔僀傾儞僩偵偡傞偙偲偑偱偒傑偡丅
丂偙偙偐傜偼丄twitteR傪棙梡偟偰丄Twitter偐傜堷偒弌偣傞忣曬偺壜帇壔偲僥僉僗僩儅僀僯儞僌偺僀儞僩儘僟僋僔儑儞傪峴偄偨偄偲巚偄傑偡丅
丂傑偢twitteR傪僀儞僗僩乕儖偟傑偡丅R偺懳榖僾儘儞僾僩偐傜install.packages娭悢傪屇傃弌偟傑偡丅CRAN僒僀僩偵偮偄偰偼丄椺偊偽乬Japn乮Tukuba乯乭傪慖戰偟偰偔偩偝偄丅
> install.packages("twitteR")
丂崱夞偼偙偺twitteR埲奜偵傕丄igraph偲RMeCab傪棙梡偟傑偡丅偙傟傕偙偙偱僀儞僗僩乕儖偟偰偟傑偄傑偟傚偆丅偨偩偟丄RMeCab偵偮偄偰偼丄install.packages娭悢偱僀儞僗僩乕儖偱偒傑偣傫丅偙傟偼丄屻傎偳婰弎偟傑偡偑丄僟僂儞儘乕僪僒僀僩傛傝僶僀僫儕僼傽僀儖傪僟僂儞儘乕僪偟偰丄儘乕僇儖僨傿僗僋偐傜僀儞僗僩乕儖偡傞偙偲偵側傝傑偡丅
> install.packages("igraph")
friends偲followers傪壜帇壔偡傞
丂偝偰丄偙偺twitteR偺棙梡曽朄偱偡偑丄晛捠偺僋儔僀傾儞僩偲摨偠傛偆偵丄Twitter偺傾僇僂儞僩乮傾僇僂儞僩柤偲僷僗儚乕僪乯偑昁梫偱偡丅傑偢丄twitteR傪Twitter僋儔僀傾儞僩傪僗僞乕僩偝偣傞偨傔偵僙僢僔儑儞傪奐巒偡傞昁梫偑偁傝傑偡丅偦傟偵偼initSession娭悢傪棙梡偟傑偡丅
> library(twitteR)
> session <- initSession("YOURNAME", "YOURPASS")
> session
An object of class 乬CURLHandle乭
Slot "ref":
<pointer: 0xa50000>
丂 YOURNAME偲YOURPASS偵偼偦傟偧傟丄偛帺恎偺Twitter傾僇僂儞僩柤偲僷僗儚乕僪傪棙梡偟偰偔偩偝偄丅initSession娭悢偐傜曉偝傟傞偺偼Unix偺CURL僐儅儞僪傪儔僢僾偟偨乬CURLHandle乭僆僽僕僃僋僩偱丄twitteR偺娭悢傪棙梡偡傞偲偒偵偙偺僆僽僕僃僋僩傪堷悢偵搉偟偰傗傞昁梫偑偁傝傑偡丅
丂Twitter傪摿挜揑偵偟偰偄傞傕偺偺1偮偵丄Twitter偺嶲壛幰偺娫偱following/follwer娭學偲偄偆朿戝側幮夛娭學偑僀儞僞乕僱僢僩忋偵峔抸偝傟偰偄傞丄偲偄偆偙偲偑嫇偘傜傟傞偲巚偄傑偡丅偦偺堄枴偱丄Twitter偼幮夛娭學帒杮乮social capital乯偺僀儞僼儔僗僩儔僋僠儍乕偵側傝摼傞偲丄偙偺峞偺朻摢偱弎傋傑偟偨丅偙偙偱偼偦偺Twitter偺follwing/follower娭學傪壜帇壔偟偨偄偲巚偄傑偡丅
丂twitteR偱偼丄帺暘傗懠偺恖娫偺following偟偰偄傞恖暔傪僞乕僎僢僩偲偟偰丄偦偺僞乕僎僢僩偺儕僗僩傪摼傞偵偼userFriends傪棙梡偟傑偡丅戞1堷悢偵偼挷傋偨偄傾僇僂儞僩傪僗僩儕儞僌偐twitteR偺user僆僽僕僃僋僩傪擖傟丄戞擇堷悢偵偼嵟戝抣丄戞嶰堷悢偵偼愭傎偳庢摼偟偨僙僢僔儑儞僆僽僕僃僋僩傪擖傟傑偡丅儐乕僓偺儕僗僩偑曉偝傟傑偡丅偙偙偱拲堄揰偱偡偑丄戞擇堷悢偺n傪100埲壓偵偟偰傕100屄偺儕僗僩偑曉傞傛偆側巇條偵側偭偰偄傞傛偆偱偡丅
> target <- "hatoyamayukio" > friends.obj <- userFriends(target, n = 100, session) > head(friends.obj) [[1]] [1] "barthkoch" [[2]] [1] "rimaruko" [[3]] [1] "sean_fuji" [[4]] [1] "gu_cci" [[5]] [1] "usavich3" [[6]] [1] "amanecs"
丂幚嵺偵撉幰偺奆偝傫偺夋柺偵昞帵偝傟偨寢壥偼丄忋偺傕偺偲偼堎側傞偐傕抦傟傑偣傫丅偦傟偼丄Twitter偵偍偗傞娭學偼帪乆崗乆曄壔偟偰偄傞偨傔偱偡丅摨條偵followers傪庢摼偡傞偵偼丄userFollowers傪棙梡偟傑偡丅偝偰丄偙偙偱僞乕僎僢僩偺following偲follower偺儕僗僩傪庢摼偟丄偦偺僨乕僞傪僌儔僼昞尰偱帇妎壔偟偨偄偲巚偄傑偡丅偦偺偨傔偵丄follwing偲follwers偺傾僇僂儞僩柤傪1偮偺僨乕僞僼儗乕儉偵奿擺偟傑偡丅userFriends傗userFollowers偐傜曉偝傟傞儕僗僩僆僽僕僃僋僩偺拞恎傪尒偰傒傞偲埲壓偺傛偆偵側偭偰偄傑偡丅
> str(friends.obj) List of 100 $ :Formal class 'user' [package "twitteR"] with 14 slots .. ..@ description : chr "" .. ..@ statusesCount : num 17 .. ..@ followersCount: num 20 .. ..@ favoritesCount: num(0) .. ..@ friendsCount : num 80 .. ..@ url : chr(0) .. ..@ name : chr "barthkoch" .. ..@ created : chr "Thu Aug 20 21:03:33 +0000 2009" .. ..@ protected : logi FALSE .. ..@ verified : logi FALSE .. ..@ screenName : chr "barthkoch" .. ..@ location : chr "Brazil" .. ..@ id : num 67424072 .. ..@ lastStatus :Formal class 'status' [package "twitteR"] with 10 slots ...
丂偳偆傗傜丄screenName偑儐乕僓偺傾僇僂儞僩柤偺傛偆偱偡丅偙偙偱@偱巒傑傞傕偺偑儕僗僩偵奿擺偝傟偰偄傞懏惈僆僽僕僃僋僩偱丄懏惈僆僽僕僃僋僩偼乽僉乕乿偲乽抣乿偺儁傾偵側偭偰偄傑偡丅懏惈僆僽僕僃僋僩偐傜懏惈抣傪庢傝弌偡偵偼丄偦偺僉乕傪娭悢偲偟偰揔梡偟傑偡丅帋偟偵儕僗僩偐傜1偮栚偺懏惈僆僽僕僃僋僩偩偗傪庢傝弌偟偰丄偦偺僉乕screenName傪娭悢偲偟偰揔梡偟偰傒傑偟傚偆丅
> screenName(friends.obj[[1]]) [1] "barthkoch"
丂偙傟偱丄userFriends傗userFollowers偐傜曉偝傟傞儕僗僩僆僽僕僃僋僩偵奿擺偝傟偰偄傞傾僇僂儞僩柤傪庢傝弌偡曽朄偑暘偐傝傑偟偨丅偙傟傪慡偰偺儕僗僩偵揔梡偟丄w偮偺僨乕僞僼儗乕儉偵摑崌偡傞偵偼師偺傛偆偵偟傑偡丅followers偺儕僗僩傕偮偄偱偵庢摼偟偰偍偒傑偟偨丅
> followers.obj <- userFollowers(target, n = 100, session)
> friends <- sapply(friends.obj, screenName)
> followers <- sapply(followers.obj, screenName)
> relationsdf <- merge(data.frame(User = target, Follower = friends),
+ data.frame(User = followers, Follower = target),
+ all = T)
> head(relationsdf)
User Follower
1 hatoyamayukio 178REIJI
2 hatoyamayukio 3hit
3 hatoyamayukio 921_u3u3
4 hatoyamayukio a_ikenag
5 hatoyamayukio ace_champ
6 hatoyamayukio achora
> tail(relationsdf)
User Follower
195 YoshidaFumitaka hatoyamayukio
196 yoshitada9646 hatoyamayukio
197 ysugihara1221 hatoyamayukio
198 yuki70424b hatoyamayukio
199 yunikonnyaku hatoyamayukio
200 yutakakanagawa hatoyamayukio
丂偙偙偱丄following儕僗僩僆僽僕僃僋僩偲followers儕僗僩僆僽僕僃僋僩偵screenName傪堦妵揔梡偡傞偨傔偵sapply傪棙梡偟傑偟偨丅傑偨丄僨乕僞僼儗乕儉傪嶌惉偡傞偵偼data.frame丄嶌惉偟偨2偮偺僨乕僞僼儗乕儉傪摑崌偡傞偵偼mearge傪棙梡偟傑偟偨丅
丂head偲tail偱嵟弶偺曽偲嵟屻偺曽偺User-Follower娭學傪傒傑偡偲丄惓忢偵僨乕僞僼儗乕儉偑偱偒偰偄傞傛偆偱偡丅
丂師偼偙偺User-Follwer娭學偺帇妎壔偱偡丅偙傟偼User -> Follower娭學偵側偭偰偄傞偺偱丄僌儔僼棟榑偺奣擮偱偄偆偲偙傠偺桳岦僌儔僼偱偡丅R偱桳岦僌儔僼傪帇妎壔偡傞偵偼igraph僷僢働乕僕傪棙梡偡傞偺偑堦斣庤偭庢傝憗偄偱偡丅
丂igraph僷僢働乕僕傪棙梡偡傞偟偰僌儔僼傪昤夋偡傞偵偼丄捠忢偺僨乕僞僼儗乕儉傪捀揰偲曈偺懏惈傪晅偗壛偊偨僨乕僞僼儗乕儉偵曄姺偡傞昁梫偑偁傝傑偡丅偙傟傪峴偆偺偑graph.data.frame偱偡丅
> library(igraph)
> g <- graph.data.frame(relationsdf, directed = T)
> g
Vertices: 201
Edges: 200
Directed: TRUE
Edges:
[0] 'hatoyamayukio' -> '178REIJI'
[1] 'hatoyamayukio' -> '3hit'
[2] 'hatoyamayukio' -> '921_u3u3'
[3] 'hatoyamayukio' -> 'a_ikenag'
...
丂崱夞偼graph.data.frame偵directed = T偲偄偆曽岦晅偗僆僾僔儑儞傪巜掕偟偨偺偱丄User -> Follower娭學偑昞尰偱偒傑偟偨丅偙偺g偑igraph偱棙梡偡傞僨乕僞僼儗乕儉偱偡偑丄捀揰僆僽僕僃僋僩偲曈僆僽僕僃僋僩傪庢傝弌偡偵偼丄V偲E傪棙梡偟傑偡丅V偼"V"ertec乮捀揰乯丄E偼"E"dge乮曈乯傪堄枴偟傑偡丅捀揰偺僆僽僕僃僋僩偺柤慜傪庢傝弌偡偵偼$name偵傛傝庢傝弌偟傑偡丅
> head(V(g))
Vertex sequence:
[1] "20100912pm3" "24KinKiKids51" "313so" "9_nanatuki" "Airi0419" "ak3161"
> head(E(g))
Edge sequence:
[1] hatoyamayukio -> 3hit
[2] hatoyamayukio -> 921_u3u3
[3] hatoyamayukio -> a_ikenag
[4] hatoyamayukio -> ace_champ
[5] hatoyamayukio -> achora
[6] hatoyamayukio -> ahoneko_tom
> head(V(g)$name)
[1] "hatoyamayukio" "20100912pm3" "24KinKiKids51" "313so" "9_nanatuki" "Airi0419"
> V(g)$label
NULL
> V(g)$label <- V(g)$name
丂嵟屻偺僐乕僪偼丄僌儔僼傪彂偄偨偲偒偵婰弎偝傟傞捀揰偺儔儀儖$label偵$name懏惈偵偁傞傾僇僂儞僩柤傪偦偺傑傑擖傟傑偟偨丅偙傟偱僌儔僼傪昤偔弨旛傪偑惍偄傑偟偨丅僌儔僼傪昤偔偺偼幚偼偡偛偔梕堈偱丄堦斣娙扨側僌儔僼偼plot娭悢傪僌儔僼僨乕僞僼儗乕儉偵揔梡偡傞偩偗偱偡丅

丂偟偐偟丄100埲忋偺捀揰僆僽僕僃僋僩偑偁傞応崌丄僆僽僕僃僋僩偑廳側偭偰偟傑偄偙傟偱偼傛偔暘偐傝傑偣傫丅偦偙偱斾妑揑崅婡擻偺僌儔僼昤夋娭悢偱偁傞tkplot傪棙梡偟偰傒傑偡丅偙傟偼tk僌儔僼傿僢僋儔僀僽儔儕忋偵嶌惉偝傟偨僌儔僼僾儘僢僩儔僀僽儔儕偱偡丅
> tkplot(g)
丂tkplot娭悢偱偼丄丄乬Layout乭儊僯儏乕偐傜僌儔僼偺攝抲傪曄峏偡傞偙偲偑偱偒傑偡丅椺偊偽丄Kawada-Kawai傾儖僑儕僘儉傪慖傫偱僾儘僢僩偡傞偲埲壓偺傛偆側僌儔僼偵側傝傑偡丅

丂偙偺tkplot偱昤偐傟偨僌儔僼忋偺僆僽僕僃僋僩偼儅僯儏傾儖偱攝抲偑曄峏偱偒傑偡丅傑偨曈傪慖傋偽偦偺曈偑僴僀儔僀僩偟傑偡偟丄捀揰傪慖傋偽捀揰偑僴僀儔僀僩偟丄捀揰娫偺娭學偑偁傞掱搙暘偐傞傛偆偵側偭偰偄傑偡丅
丂埲忋偑丄Twitter偺幮夛娭學傪帇妎壔偡傞偨傔偵丄twitteR偐傜庢摼偟偨follwing/follower偺儕僗僩傪僌儔僼壔偟偡傞堦楢偺庤弴偱偡丅
Index
僀儞僞乕儕儏乕僪: Twitter偲R
Page1
崱夞偼娫憈揑偵IT婑傝偺榖戣傪
Twitter偲R
friends偲followers傪壜帇壔偡傞
Page2
Twitter僥僉僗僩儅僀僯儞僌偺擖栧偺擖栧
師夞偵偮偄偰
Copyright © ITmedia, Inc. All Rights Reserved.




![]() ITmedia偼傾僀僥傿儊僨傿傾姅幃夛幮偺搊榐彜昗偱偡丅
ITmedia偼傾僀僥傿儊僨傿傾姅幃夛幮偺搊榐彜昗偱偡丅