大相撲のアノーマリー (1):実践! Rで学ぶ統計解析の基礎(7)(1/2 ページ)
大相撲の勝敗結果を分析すると、ちょっとした不自然さが見つかります。今回は、ベストセラーとなった書籍「ヤバい経済学」でも紹介されていた論文を元ネタにネット上のデータを利用して解析を試みます。
今回の前口上
諸事情により2カ月の間連載を空けてしまいました。申し訳ございませんでした。実は10月、11月に用意した時事ネタがいろいろあるのですが、こちらは少しタイミングを逸して旬が過ぎたので、もう少し寝かせてから提示したいと思います。また、何人かの読者の方から励ましのお言葉を戴きまして大変感謝しています。本当に励みになります。ありがとうございました。もしもこの連載で取り上げてほしい問題やネタ、改善点などがありましたら、遠慮なく以下のメールアドレスにリクエストやご意見をお送りください。
knife@bakfoo.com
今回から数回は、大相撲の統計データをネタにして、「公になっているが混乱しているデータ」(英語では“messy data”といいます)を、いかにしてキレイにし、キレイにしたデータをどのように解析するかという一連の手順を提示します。データ解析を実務で行う場合には、ここが一番の肝の部分になり、それを具体的な事例を用いて解説しようと思っています。
汚いデータをどうする?
この連載で以前紹介した世界銀行のWeb APIサービスは、ウェブにおける現在最も洗練されたデータ公開方法の1つです。APIの仕様さえ守れば、RESTインターフェイスから誰でも必要な情報にアクセスでき、データを入手することが可能です。しかし、すべての組織や個人がこのように洗練した形でデータを公開しているわけではありません。むしろ、ウェブにあるほとんどの情報は、コンピュータの視点からみると混乱している汚いデータである、といっていいでしょう。
混乱している汚いデータの筆頭として、構造化を考えて記述されていないHTMLによるデータがあります。ポータルサイトにあるスポーツの勝敗表などがその代表例です。このようなウェブにあるHTMLなどで表現された情報を入手し、必要なデータを取り出すことを、「HTMLスクレイピング」と言います。
スクレイピングは一見するとウェブを効率よく利用しているように見えますが、特定のURLやHTMLに依存して目的のデータを探すわけで、スクレイピング対象のWebサイトのシステム変更や、HTMLの仕様変更にとても弱く、スクレイピングプログラムはメンテナンスが大変ですぐに利用ができなくなりがちです。
最近はPerlのWWW::Mechanizeや、RubyのscRUBYt!などの便利で高機能なスクレイピングライブラリが出て各方面で積極的に利用されています。しかし、便利で高機能なスクレイピングフレームワークを利用しても、スクレイピングするにはHTMLの特定タグや語をテキスト解析しながらプログラミングすることが必要です。変更に弱く、容易にプログラミングしにくいことは変わりません。
ここで問題を切り分けましょう。汚いデータがあるのは事実と認め、そのデータが容易に変更されることも事実と認めましょう。この2つの要件は所与であると。汚いデータが容易に変更されたとしても、その変更に対応できるような手法を見つけることにフォーカスします。
仕様が変更になりがちな汚いHTMLを、効率よくテキスト解析してデータを入手する。そのためには、探索的にHTMLを解析できること、1度解析した手順を何度も使い回せること、という2つが必要です。今回はこの要件を満たすためのシステムとして、Google Refineを利用しましょう。
そして汚いデータの筆頭として、Yahoo! Japanにある大相撲の取り組み結果を取り上げます。このデータを取り上げた理由は2つあります。1つはHTMLの構造が混乱しているのでテキスト解析のプログラミングが面倒なこと、もう1つは大相撲の取り組み結果は非常に面白い解析結果が知られていることです。
Yahoo! Japanスポーツの大相撲の取り組み結果
Yahoo! Japanスポーツにおける大相撲の取り組み結果の表示は以下の通りです。(http://sports.yahoo.co.jp/sumo/etc/torikumi/199901/)
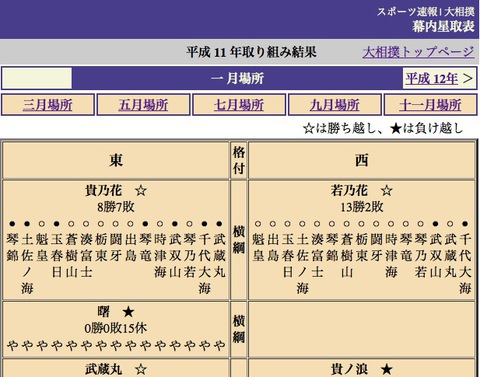 Yahoo! Japanスポーツにおける大相撲の取り組み結果
Yahoo! Japanスポーツにおける大相撲の取り組み結果このHTMLは以下のようになっています。
...
<table border=0 cellpadding=2 cellspacing=1 width=95%>
<tr><td align="right">
☆は勝ち越し、★は負け越し
</td></tr>
</table>
<table border=3 cellpadding=2 cellspacing=1 width=95% bgcolor="#F5DEB3">
<tr>
<th width=48%><font size="+1">東</font></th>
<th width=4% nowrap>格<br>付</th>
<th width=48%><font size="+1">西</font></th>
</tr>
<tr align="center" valign="top">
<td>
<b>貴乃花 ☆</b><br>
8勝7敗<br>
<table border=0 cellpadding=1 cellspacing=1>
<tr align=center valign=top>
<td>●<br>琴<br>錦</td>
<td>●<br>土<br>佐<br>ノ<br>海</td>
<td>○<br>魁<br>皇</td>
<td>●<br>玉<br>春<br>日</td>
<td>○<br>蒼<br>樹<br>山</td>
<td>○<br>湊<br>富<br>士</td>
<td>○<br>栃<br>東</td>
<td>○<br>闘<br>牙</td>
<td>○<br>出<br>島</td>
<td>●<br>琴<br>竜</td>
<td>○<br>時<br>津<br>海</td>
<td>●<br>武<br>双<br>山</td>
<td>○<br>琴<br>乃<br>若</td>
<td>●<br>千<br>代<br>大<br>海</td>
<td>●<br>武<br>蔵<br>丸</td>
</tr>
</table>
</td>
...
番付表と同じ見目を保持させるためか、意味的に異なる勝敗の星と対戦相手が同じセルに書かれていて、対戦相手の名前も<br>タグで見かけ上、縦書きにしています。もちろん、このくらいのHTMLなら正規表現をふつうに使える方や、scRUBYtの使い手でしたら、少し頑張れば試行錯誤しながらパースできるかもしれませんが、もっと簡単にパースできる方法があるとすれば、それを使わない手はありません。
7勝8敗が少なく8勝7敗多い、大相撲の不自然
世界的ベストセラーになったSteven D. LevittとStephen J. Dubnerの“Freaknomics”(邦訳「ヤバい経済学」)では、「相撲の八百長疑惑」が話題になりました。その元ネタとなったのが以下のMark DugganとSteven D. Levittの論文です。
"Winning Isn't Everything: Corruption in Sumo Wrestling"
この論文でDugganとLevittは1989年から2000年までの十両以上の取り組み表、70程度の力士の対戦を解析して、不自然なアノーマリーを報告しました。それは、7勝8敗の力士の数が非常に少ないというものです。ふつう大相撲は1人の力士の取り組み数は場所あたり15回です。すると、勝ち越し・負け越しが決まるのは7勝8敗と8勝7敗のラインで、ふつうのランダムな対戦を考えるとどちらも同じ程度の出現数になるはずです。しかし、論文のFigure2を見ると、明らかに7勝8敗が少なくて、8勝7敗が多いという「アノーマリー」が生じています。
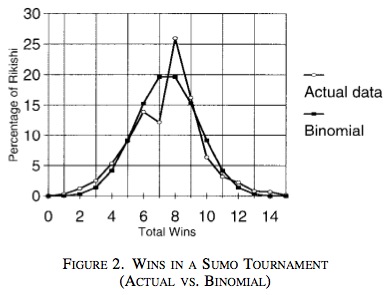 明らかに7勝8敗が少なくて、8勝7敗が多い(Levittらの論文から引用)
明らかに7勝8敗が少なくて、8勝7敗が多い(Levittらの論文から引用)論文は、このアノーマリーをさらに詳しくみて、最終日の対戦において7勝7敗の力士が、すでに勝ち越しを決めている力士と対戦するときに、7勝7敗の力士が勝つ確率が高いことを統計解析により示しました。また、この現象を説明できる可能性のある仮説を立て、仮説検定をし、やはり勝ち越し・負け越しのギリギリの当落線上にいる力士が勝ちやすいという傾向があることを明らかにしました。そして、ここからなぜ当落線上の力士が勝ちやすいかということを、経済学的なインセンテティブ構造からアネクドート的に記述します。ここでは詳しくは書きませんが、大変面白い論文なので機会があったら読むことを是非オススメします。
上記の論文では1989年から2000年のデータを利用しています。すると当然のことながら最近のデータを利用すればどうなるか? ということが気になります。このシリーズではそれを手順を追って見ていきましょう。ただし、あまり隠すのも趣味が悪いので、先に結果だけを提示していきます。コードの詳しい解説は次回以降に回しますが、1999年から2010年9月までの大相撲の勝敗分布を再現するコードは次のようになります。CRANのplyrライブラリを利用して、なかなかエレガントなコーディングができたので、それを早く解説したいとは思いますが、長くなるので後に回します。また、ここでは、後ほどGoogle Refineでクリーニングして手に入れる予定のデータを先取りして利用していますが、そのデータはGoogle DocsにCSV形式で置いておきました。
df <- read.csv("http://spreadsheets.google.com/pub?key=0AlBuJgqcP5f3dElpb0lWcDRjZldkMzE1LW5aY1VtMHc&hl=en&single=true&gid=0&output=csv", header=FALSE)
names(df) <- c("rikishi", "vs", "win", "year", "month")
nrow(df)
df <- subset(df, df$win!=-100 & df$win!=-1)
library(plyr)
df <- ddply(df, .(rikishi, year, month), summarize, numwin=sum(win))
library(ggplot2)
p2 <- ggplot(df, aes(numwin)) + geom_histogram(aes(y = ..count..))
ggsave(plot = p2, filename = "sumoobservation.png")
dsumo <- function(x, total) total*dbinom(x, size = 15, prob = 1/2)
dft<- data.frame(x = c(0:15), win_theory = dsumo(c(0:15), nrow(df)))
df2 <- as.data.frame(table(df$numwin))
names(df2) <- c("x", "win_observ")
str(df2)
df2 <- transform(df2, x = as.integer(x)-1, win_theory = dft$win_theory)
ggplot(data = melt(df2, id = 'x'), aes(x = x, y = value, colour = variable)) + geom_line()
ggplot(data = df2, aes(x)) + geom_point(aes(y = win_observ, colour = "win_observ")) + geom_line(aes(y = win_observ, colour = "win_observ")) + geom_line(aes(y = win_theory, colour = "win_theory"))
結果は以下のグラフになります。

横軸が勝ち星の数で、縦軸が実際にその勝ち星を稼いだ力士の人数です。赤の線が1999年1月場所から2010年9月場所までの勝敗結果の分布で、青緑の線が勝負がランダムに生じたと仮定したときに描かれる二項分布になります。これを見ると分かるように、本来は500人ほどいてもいいはずの7勝8敗の力士数が、350人程度と、かなり少なくなっています。また、DugganとLevittの結果よりも、負け星が極端に多い力士と勝ち星が極端に多い力士の人数が多くなっていて、裾が広い分布になっています。これについて、筆者はDugganとLevvitの結果に疑問があります。彼らのグラフには全勝力士がゼロか、それに近い分布となっていまっす。しかし、1999年から2010年の結果を見ても、結構全勝優勝はありますし、DugganとLevittが使用した1989年から2000年にも全勝優勝は耳にしたことがあります。当時は若貴全盛期だったはずで、なぜ全勝がゼロなのでしょうか? とりあえず、この疑問は脇において、このシリーズでは、まずはこの「大相撲のアノーマリー」を自分で確かめることを試みます。
Index
大相撲のアノーマリー (1)
Page1
今回の前口上
汚いデータをどうする?
Yahoo! Japanスポーツの大相撲の取り組み結果
7勝8敗が少なく8勝7敗多い、大相撲の不自然
Page2
Google Refine
次回について
Copyright © ITmedia, Inc. All Rights Reserved.




![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。