実践! 「MapReduceでテキストマイニング」徹底解説:テキストマイニングで始める実践Hadoop活用(2)(2/3 ページ)
重みベクトルの推定を分散化する方法とは
青空文庫の作品を1つずつ見ていって重みベクトルを更新していけばよいということが分かりましたが、では、どうMapReduceで分散すればよいのでしょうか?
「Mapperで、それぞれ分割されたデータに対して別々に重みベクトルを推定し、Reducerで、それらの重みベクトルの平均を求める」プロセスを繰り返すという方法を取りましょう。
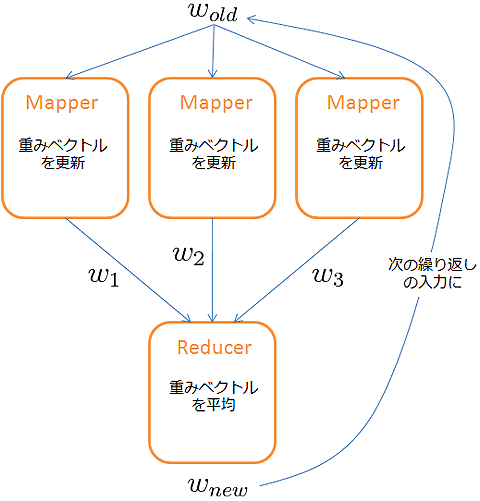
ちなみに以下の論文で、この分散化の方法の有効性が書かれています。
形態素解析には、「gomoku」を使用します。Mecab互換で、jarに辞書が含まれているので、扱いやすいです。
青空文庫の作品をベクトル化するMapReduce
では、実際にMapReduceプログラムを作成していきましょう。はじめに、青空文庫のファイルを入力にして、形態素解析を行ってbag-of-wordsでベクトル化し、その著者の寿命をKey、ベクトルをValueにして出力します。
なお、単純にベクトル化すると扱いにくいので、実際には「単語:頻度」の連想配列として出力します。
青空文庫のファイル→<作者の寿命, 作品ベクトル>
このプロセスでは、Reducerは必要ないので、Mapperの結果を直接ファイルに出力します。
作者の寿命は、こちらのページから抜き出して、以下のようなファイルを用意しておき、Mapperの初期化処理で読み込みます。
平井肇,50 薄田泣菫,68 後藤朝太郎,64
MapReduceを起動するためのDriver
では、MapReduceを起動するためのDriverを書いてみます。
1 public class ExtractAozoraFeatureDriver {
2 public static void main(String[] args) throws Exception {
3 Configuration conf = new Configuration();
4 String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
5 if (otherArgs.length < 2) {
6 System.err.println("Usage: hadoop <in> <out>");
7 System.exit(2);
8 }
9 Job job = new Job(conf, "extract aozora feature");
10 job.setJarByClass(ExtractAozoraFeatureDriver.class);
11 job.setMapperClass(ExtractAozoraFeatureMapper.class);
12 job.setInputFormatClass(CombineWholeFileInputFormat.class);
13 job.setOutputFormatClass(SequenceFileOutputFormat.class);
14 job.setOutputKeyClass(VIntWritable.class);
15 job.setOutputValueClass(MapWritable.class);
16 job.setNumReduceTasks(0);
17 FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
18 FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
19 System.exit(job.waitForCompletion(true) ? 0 : 1);
20 }
21 }
4行目のGenericOptionsParserで、コマンドラインで設定したHadoopのオプションをパースし、5〜10行目で残りの引数を読み込んでいます。このコマンドラインで設定するオプションについては、後で解説します。
9行目でJobクラスのインスタンスを生成し、10行目はこのクラス自体を指定します。12行目は、入力ファイルがどういう形式で、Mapperごとにどう分割するかを決めるクラスを指定しています。
青空文庫は1ファイルに1作品という形式になっているので、map関数の1回の入力ごとに、1ファイル全体を読み込みます。
さらに、Mapperごとに複数のファイルを割り当てられるように工夫した、「CombineWholeFileInputFormat」というクラスを独自で用意して設定しています。
13行目は、どういう形式でファイルを出力するかを決めるクラスを設定していて、「SequenceFileOutputFormat」という、HadoopのKeyとValueをそのまま出力できるHadoopの独自形式を指定しています。
14、15行目は、それぞれ、出力のKeyとValueの形式を指定していて、Keyに可変長のintを出力できる形式(著者の寿命)、Valueに連想配列(作品ベクトル)を指定しています。16行目で、setNumReduceTasksに「0」を指定することで、Reducerを起動せず、Mapperから直接ファイルに出力できます。
最後に、17〜19行目で入力ファイル、出力ファイルのパスを指定して、MapReduceを起動しています。
Mapper
次にMapperを記述します。
1 public class ExtractAozoraFeatureMapper
2 extends Mapper<NullWritable, BytesWritable, VIntWritable, MapWritable> {
3 Map<String, Integer> lifeMap = new HashMap<String, Integer>();
4 @Override
5 public void setup(Context context) throws IOException, InterruptedException {
6 Configuration conf = context.getConfiguration();
7 String lifeFile = conf.get("author.classifier.life.file");
8 FileSystem fs = FileSystem.get(conf);
9 FSDataInputStream is = fs.open(new Path(lifeFile));
10 BufferedReader br = new BufferedReader(new InputStreamReader(is,
11 "UTF-8"));
12 try {
13 String line = null;
14 while ((line = br.readLine()) != null) {
15 String[] items = line.split(",");
16 lifeMap.put(items[0], Integer.parseInt(items[1]));
17 }
18 } finally {
19 br.close();
20 is.close();
21 }
22 }
23 @Override
24 public void map(NullWritable key, BytesWritable value, Context context)
25 throws IOException, InterruptedException {
26 String rawText = new String(value.getBytes(), "Shift_JIS");
27 Aozora aozora = AozoraParser.parse(rawText);
28 Integer life = lifeMap.get(aozora.getAuthor());
29 if (life != null) {
30 MapWritable wordFreqMap = new MapWritable();
31 for (Morpheme m : Tagger.parse(aozora.getNormalizedBody())) {
32 Text word = new Text(m.surface);
33 if (!CommonUtil.isContentWord(m.feature))
34 continue;
35 VIntWritable freq = (VIntWritable) wordFreqMap.get(word);
36 if (freq == null) {
37 wordFreqMap.put(word, new VIntWritable(1));
38 } else {
39 freq.set(freq.get() + 1);
40 }
41 }
42 context.write(new VIntWritable(life), wordFreqMap);
43 }
44 }
45 }
6〜21行目は、Mapperで最初に1回呼び出される初期化処理で、作者の寿命を記述したファイルを読み込んで、lifeMapに設定しています。7行目で、コマンドラインで指定したHDFS上のファイル名を読み込んでいます。
26〜43行目は、1つのファイルを読み込むたびに呼び出され、valueにファイル全体がバイト列として設定される、処理のメインとなる関数です。通常は、ファイルの1行を読み込むたびにmap関数が呼び出されますが、CombineWholeFileInputFormatを設定しているためにファイルごとになっています。
26行目で、バイト列をStringにデコードし、27行目で、青空文庫のフォーマットに従ってAozoraParserでパースします。パースされた結果は、Aozoraクラスに指定され、タイトル、著者名、ノーマライズ済みのテキストなどが取得できます。
28行目では、作者の寿命を設定しています。31行目で、形態素解析を行い、単語ごとに繰り返し処理を行います。35行目は、内容語(名詞、形容詞、動詞)かどうかをチェックして、そうでない場合は省いています。
35〜40行目で、Mapperで出力する連想配列に「単語:頻度」という形で設定し、42行目で出力しています。
MapReduceを起動
以下のように実行します。
$ hadoop jar job.jar ExtractAozoraFeatureDriver -libjars /local/path/to/gomoku.jar -D author.classifier.life.file=/hdfs/path/to/life.txt -D mapreduce.input.fileinputformat.split.maxsize=16777216 /hdfs/path/to/input /hdfs/path/to/output
「-libjars」は、Mapperに配布してMapperの起動時に読み込むJarファイルで、形態素解析を行うgomoku.jarを指定しています。「-D」オプションはMapReduceプログラム内部で読み込める値を設定していて、author.classifier.life.fileで、寿命を記述したファイルパス、「mapreduce.input.fileinputformat.split.maxsize」で、1つのMapperで読み込むデータの合計の最大サイズ(バイト)を設定しています。最後に、入力ディレクトリと出力ディレクトリを設定しています。
あらかじめ、入力ディレクトリに青空文庫のテキストファイルをすべて転送してから実行してください。また、実行前に、出力ディレクトリは存在しないことを確認してください。
次ページでは、 重みベクトルを計算するMapReduceプログラムについて解説し、実行してみます。
Copyright © ITmedia, Inc. All Rights Reserved.




![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。