Hadoopの現実解「バッチ処理」の常識をAsakusaで体得:ビッグデータ処理の常識をJavaで身につける(7)(4/4 ページ)
【7】ジョブフローの記述
データフローのベースクラスであるFlowDescriptionを継承したJavaのクラスとして宣言します。
【8】バッチの記述
今回作成したジョブフローは1つなので、下記のように、「run({ジョブフロークラス}).soon()」で、すぐに実行するように記述します。
package tc.asakusa.day2.batch;
import tc.asakusa.day2.jobflow.JfItemSalesSummary;
import com.asakusafw.vocabulary.batch.Batch;
import com.asakusafw.vocabulary.batch.BatchDescription;
@Batch(name = "Day2ItemSummary")
public class BtSummarize extends BatchDescription {
@Override
protected void describe() {
run(JfItemSalesSummary.class).soon();
}
}Tips
例えば、Job1の終了後、Job2を起動するような場合は、「run(Job2.class).after(job1)」のように記述します。図のようにJob1の終了後、Job2とJob3を並列で起動して、Job2とJob3の両方が終了した後、Job4を起動したい場合は、(例)のように記述します。
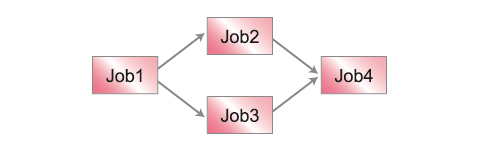
Work job1 = run(Job1.class).soon();
Work job2 = run(Job2.class).after(job1);
Work job3 = run(Job3.class).after(job1);
Work job4 = run(Job4.class).after(job2, job3);
アプリケーションのビルド
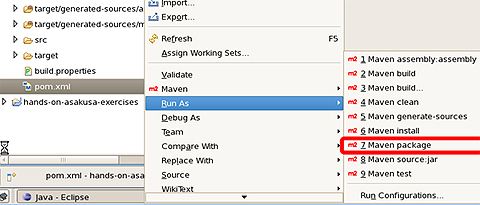
さて、ようやく1本のバッチが完成しました。早速ビルドしてみましょう。アプリケーションのビルドは、pom.xmlを右クリックして[Run As]→[Maven package]を選択します。
コマンドラインからビルドする場合は、プロジェクトのディレクトリ(pom.xmlがあるディレクトリ)に移動してから下記のMavenコマンドを実行します。
$ cd ~/workspace/プロジェクトのディレクトリ
$ mvn packagemvn packageを実行すると、テストコードをすべて実行されます。すべてのテストにパスすれば、プロジェクトのターゲットディレクトリにパッケージが作成されます。
Tips
大量にテストコードがあり、テストの実行だけで数十分かかってしまうということもあるでしょう。ちょっと急いでいるので、テストはスキップしたいということもあると思います。そんな場合は、下記のコマンドで、テストをスキップしてパッケージを作成できます。
$ cd ~/workspace/プロジェクトのディレクトリ
$ mvn -Dmaven.test.skip=true packageただし、あまり乱用しないようにしてください。「これぐらいの修正であれば、影響ないだろう」という妄信は、トラブルの元です。
バッチのデプロイと実行
バッチのデプロイ先は、「$ASAKUSA_HOME/batchapps」です。デプロイは、ここにjarファイルを展開します。
デプロイが完了したら、「$ASAKUSA_HOME/batchapps」ディレクトリの下に、バッチIDのディレクトリが作成されます。
├ Day2ItemSummary ←バッチIDのディレクトリ
│ ├ bin
│ │ └ experimental.sh ←テスト実行用のシェル(deprecated予定)
│ ├ etc
│ │ ├ build.log
│ │ └ yaess-script.properties
│ └─ lib
│ ├ jobflow-JFItemSummary-sources.jar
│ └ jobflow-JFItemSummary.jarjarファイルを展開すると、テスト実行用のシェルスクリプト(experimental.sh)ができますが、このシェルスクリプトは、deprecated 予定なので、バッチの実行にはYAESSを使用することが推奨されます。YAESSを使ったバッチの実行は、「$ASAKUSA_HOME/batchapps」ディレクトリで「yaess-batch.sh」にバッチIDを引数に指定して起動します。
Tips
YAESSで実行するバッチに引数を渡したい場合は、yaess-batch.sh実行時に「 -A {変数名}={値}」のように指定します。
※プログラムの中からバッチ引数の値を参照するには、コンテキストAPIを使用します。
:
Import com.asakusafw.runtime.core.BatchContext;
:
:
String shop_code = BatchContext.get("shop_code");
String sum_month = BatchContext.get("sum_month");
:新しい価値を生み出す「バッチ処理」の高速化
現行で5分かかっている「バッチ処理」が1分になったところで、そんなにうれしいことはないでしょう。例えば、8時間かかるので月次でしか実行できない商品別販売数の集計バッチ処理が20分で終わるようになれば、日次で実行することも可能になるかもしれません。
意思決定の周期が短くなれば、適宜、必要な商品を必要なだけ仕入れられるようになり、過剰在庫をかかえて腐らせてしまうこともありません。これは、一例でしかありませんが、皆さんがお使いになっているシステムや、お客さまに提供しているシステムでも「バッチ処理」が早く終われば、「機会損失が少なくなる」「もっとダイナミックな営業展開ができる」「いままであきらめていたことが、できるようになる」といったことがあるのではないかと思います。
また、データ量の増大に伴い、「バッチ処理」が実行できる時間帯で、実行が終わらなくなりそうなので、「そろそろハードウェアを増強しないと」みたいな話もあると思います。高価で高性能なハードウェアを増強するよりも、コモディティなマシンで構成したHadoopクラスタで、長時間バッチの実行時間を短縮するという解決法も考えられます。
とはいえ、自社でHadoopクラスタ構築、運用するというのも、若干、ハードルが高かったりもします。そんなに「たくさんのマシンを導入して管理しきれるのか」であるとか、「1台故障したときにどのように対処すればいいのだろう」であるとか、Hadoopクラスタを導入するのであればそれなりに検討しておかないといけないことがあります。
最近では、AWS(Amazon Web Serves)などのパブリッククラウドを必要なときに必要な時間だけ借りて、並列分散で「バッチ処理」を行うような事例も発表されています。これなら、時間単位で使用した分だけ課金されるので、比較的少ないコストで、「バッチ処理の時間短縮することによる新しい価値」を得られます。本当に時間短縮できるのか、試験的にHadoopクラスタを使ってみるのにも適しています。
「ビッグデータ」を安価な「クラウド環境」で高速に処理して「新しい価値」を得られるという、うれしい時代になってきたのです。
著者紹介
笹尾 一夫(ささお かずお)
ビッグデータの分析ツールの調査、検証に従事。本番業務システムにおいて300時間かかっていたバッチ処理をAsakusaFWで設計・実装し直し5時間弱に時間短縮可能であることを検証した。
TIS先端技術センターでは、採れたての検証成果や知見などをWebサイトで発信中
関連記事
- 次世代Hadoopの特徴は、MapReduce 2とGiraph
Hadoopの父に聞く、HadoopとClouderaの現在・未来 - テキストマイニングで始める実践Hadoop活用
- Javaで覚えるIT技術者の40の常識
新人プログラマ/SEは覚えておきたい“まとめ” - 実践! Rで学ぶ統計解析の基礎
Copyright © ITmedia, Inc. All Rights Reserved.




![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。