Google、App Engineの障害について経緯を説明:ルータ負荷の上昇がきっかけ
Googleは、米国時間の10月26日にGoogle App Engineで発生したサービス障害について、同日付のブログで経緯や再発防止策について説明した。
米Googleのクラウド環境「Google App Engine」で、米国時間の10月26日にサービス障害が発生した。Googleは同日のブログで、障害発生から復旧に至るまでの経緯や再発防止策について説明している。
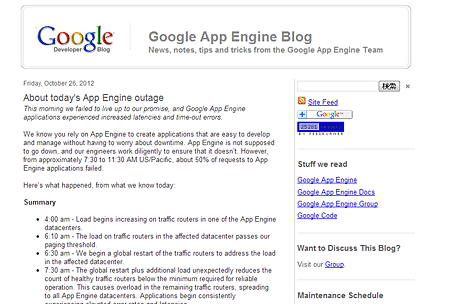
それによると、障害は米太平洋時間の26日午前7時半ごろから11時半ごろにかけて発生し、App Engineアプリケーションのリクエストの約50%が処理できなくなった。
発端は、複数あるApp Engineデータセンターの1カ所で午前4時ごろからトラフィックルータ群の負荷が増大し、6時過ぎに限界値を突破したことだった。同社はこのデータセンターの負荷に対応するため、6時半ごろからトラフィックルータのグローバルなリスタートを実施。ところがこのリスタートと負荷がさらに加わったことにより、7時半ごろには健全なトラフィックルータの数が予想外に減り、安定した運用のために必要な最低レベルを下回った。
これが原因となって残るトラフィックルータも過負荷状態に陥り、App Engineデータセンター全体に問題が拡大、アプリケーションのエラー率上昇や遅延が発生したという。
ユーザーには8時28分の通知で障害の発生を告知し、11時過ぎになって、App Engineのトラフィックルータ群が連鎖的な障害に陥っているのを発見。サービスを復旧させるためにはフルリスタートを実行してトラフィックを徐々に増やすほかに選択肢がないと判断した。11時45分にはトラフィック増大が完了し、App Engineは通常の状態に復旧した。
再発防止のための対策としては、トラフィックルータの容量を増やし、設定を変更して連鎖的障害が再発する可能性を減らすなどの措置を講じているという。
障害によるアプリケーションのデータ消失は発生せず、アプリケーションの動作は手作業による介入なしに復旧されたとGoogleは説明。サービス品質保証契約に基づいて、有料のアプリケーションについては10月の月額料金の10%に相当するクレジットを発行し、11月の料金に利用できるようにするとしている。
関連記事
- AWSの障害はメモリリークのバグに原因、Amazonが報告書公表
- Google App Engineで手軽に試すJavaクラウド
- GAE+PHP/Rubyで拓く新世界
- 【詳報】「Google App Engine」ってなんだ
関連リンク
Copyright © ITmedia, Inc. All Rights Reserved.




![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。