「データ」をめぐって聞こえてきた2つの新しいメッセージ:Database Watch(2013年4月版)(2/2 ページ)
Hadoopにも手が届くMicrosoft SQL Server 2012 Parallel Data Warehouse
ビッグデータつながりで、次はマイクロソフトです。マイクロソフトは3月21日、記者向けにビッグデータ戦略説明会を開催しました(関連記事)。顧客からマイクロソフトに寄せられる要望には、ビッグデータ分析による競争力強化、社内外などあらゆるデータソースを統合することによる情報精度を向上、センサデータの活用による業務効率化などがあるそうです。加えてデータ分析ができる人材の育成も昨今の切実な課題となっています。
マイクロソフトが掲げるビッグデータ戦略を一言でいうと「全社員 データサイエンティスト化」。ビッグデータを誰もが使えるようにすることです。そのための製品戦略とロードマップが示されました。製品戦略については日本マイクロソフト サーバープラットフォームビジネス本部 アプリケーションプラットフォーム製品部 部長 斎藤泰行氏(写真)が説明しました。

ビッグデータというとやはりデータ量が膨大ですから、何はともあれ体力、つまり処理能力が必要になってきます。既存製品としてはFast Track Data WarehouseやSQL Server SSD Applianceが有効です。後者はSQL Server EnterpriseとSSDを組み合わせたアプライアンス。ストレージにSSDを用いることで飛躍的に性能を向上させられるので、「禁断のチューニング」とも言われています。
SQL Server SSD Applianceは最近提供するハードウェアメーカーが増えてモデルが9つになりました。当初は日本HP、デル、ユニシス、東芝ソリューション、ソフトバンクテクノロジー、SCSK・NECの6つでしたが(関連記事)、最近では日本IBM、日立製作所、富士通がラインアップに加わりました(関連記事)。
さらに5月からはよりビッグデータに向けた最新アプライアンスが登場する予定です。それがMicrosoft SQL Server 2012 Parallel Data Warehouse(以下、PDW)です。ハードウェアはデルと日本HPが予定されており、ペタバイトクラスの大規模データウェアハウスです。超高速並列処理(MPP)により高パフォーマンスを実現し、Hyper-V仮想化によるノード集約でコスト削減も狙います。
加えて構造化、非構造化データを一元的に処理できるのも大きな特徴です。RDBMSにある従来型の構造化データだけではなく、Hadoopにある非構造化データも処理できるということです。非構造化データにはTwitterなどソーシャルサイトにあるデータ、センサーデータなどが含まれるため、デモでは売上の推移とTwitterの反応を見比べ、傾向や相関関係を分析する様子が示されました。
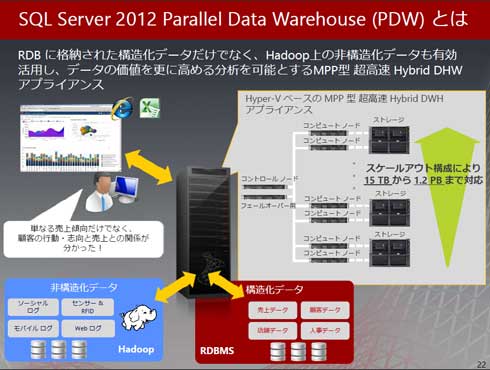
これまではソーシャルサイトにあるデータなど、Hadoopにあるデータも分析するとなるとHadoopからRDBへのデータ転送がネックとなっていました。そこでPDWではHadoopのデータを取り込まなくても処理できるようにしています。斎藤氏は「(Hadoopは)そのままでいいですよ」と、転送不要であることを強調していました。
ではどうするか。まず1つに、一気にまとめてRDBに転送(これだとボトルネックが発生)するのではなく、それぞれのHadoopデータノードとそれぞれのPDWのコンピュートノードの間を並列で転送するという方法です。小分けに多数の並列処理するため、高いパフォーマンスが狙えます。もう1つ、PDWではHDFS(Hadoop)上のデータを仮想的な表として定義できるため、クライアントからは非構造化データも構造化データも操作できます。PDWのクエリエンジンがうまく交通整理してくれるということのようです。
マイクロソフトの強みは、なんといってもユーザーインターフェイスの親しみやすさです。WebブラウザやExcelからデータにアクセスできるので、「全社員 データサイエンティスト化」には現実味があります。
4月23日には日本HPと日本マイクロソフトが共同で記者会見を行い、HP AppSystem for SQL Server 2012 Parallel Data Warehouseの販売を開始しました。日本HP大島本社にHP AppSystem Labを新設し、日本マイクロソフトのエンジニアが常駐するなどして検証や保守を円滑にするための体制を整えています。
近々デルからもPDWの提供が行われる見込みですが、その先もあります。HadoopクラスタをWindows Azureにデプロイできる「HDInsight Service」(リンク)は第3四半期から提供開始予定(現在は評価版提供中)で、これをWindows Serverで稼働させる「HDInsight Server」は第4四半期から提供開始予定となっています。
さらにその先にはSQL Serverの次期版が控えています。時期はまだ先になりますが、やはりこの流れでビッグデータ分析機能を強化する方向に進むのは間違いがないようです。どんな画期的な機能が出てくるでしょうか。

Copyright © ITmedia, Inc. All Rights Reserved.




![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。