Apache Mahoutの使い方:テキスト分類のアルゴリズムを活用する:Mahoutによる機械学習の実際(2/3 ページ)
Mahoutで「文書分類」に挑戦してみよう
データのベクタ化
Mahoutのナイーブ・ベイズで計算処理ができるよう、前ページでMeCabを使って生成したテキストファイルを、さらにベクタ形式に変換します。
はじめに、分かち書きしたファイルをHadoop内に格納し、シーケンスファイル形式に変換します。Hadoopにおけるシーケンスファイルとは、Hadoop内での高速な処理を目的としたキーバリュー型のデータ格納バイナリファイルです。下記のように、nb/というディレクトリを作成し、青空文庫のデータをシーケンスファイルとして格納します。
hadoop fs -mkdir nb hadoop fs -put aozora nb/ $MAHOUT_HOME/bin/mahout seqdirectory -i nb/aozora -o nb/aozora_seq
シーケンスファイル形式に変換したファイルの内容を確認すると、次のようになっています。「seqdumper」は、シーケンスファイルをテキストに変換して可視化するMahoutのツールです。seqdumperのコマンドを使って確認してみましょう。
$MAHOUT_HOME/bin/mahout seqdumper -i nb/aozora_seq -n 3 -b 30 Key: /0_総記/「焚書時代」の出現.txt.wakati: Value: 立法 部門 が 自分 で 立法 機関 を もつ という Key: /0_総記/ノウアスフィアの開墾.txt.wakati: Value: 1 そもそも の 矛盾 インターネット の Key: /0_総記/ハッカー倫理と情報公開・プライバシー.txt.wakati: Value: 1 はじめ に クリントン 政権 が 情報 スーパ
Keyにディレクトリパスを含むファイル名、Valueにテキスト文書の全文が入ったファイルができています。この後のMahoutナイーブ・ベイズの処理において、Keyに書かれた1つ目のディレクトリ名(「0_総記」など)が分類されたカテゴリとして扱われることになります。
次にシーケンスファイルを「seq2sparse」を使用してベクタ化します。
$MAHOUT_HOME/bin/mahout seq2sparse \ -i nb/aozora_seq \ -o nb/aozora_vectors \ -a org.apache.lucene.analysis.core.WhitespaceAnalyzer \ -ow
ベクタ化する際にオプションでさまざまな設定ができます。ナイーブ・ベイズの計算処理の説明で述べた重み付け方式や各種正規化、言葉の抽出に関する設定など、実際の分析作業では分析処理を一度実行した後、チューニングによる分析精度向上のために度々ここに戻って来ることになります。ここでは分かち書きされたテキスト文章からの単語の抽出を「WhitespaceAnalyzer」を用いて行い、他は設定なし(つまりデフォルトの設定)で実行しています。
交差検定のためのデータ分割
本稿では「交差検定」の考え方を用いてデータの分割を行います。一般に、交差検定とは分析するデータ数が少ない場合に用いられる手法で、データ全体の一部を学習データとして解析に使用し、残りのデータを試験データとして解析内容をテストすることで、解析内容の妥当性を検証します。
全体の流れは下図の通りです。データの分割から分類実行までを繰り返し(ループ)、少ないデータでモデル評価自体の精度を高めることが交差検定の狙いです。本稿では、この1ループ目のみを扱います。
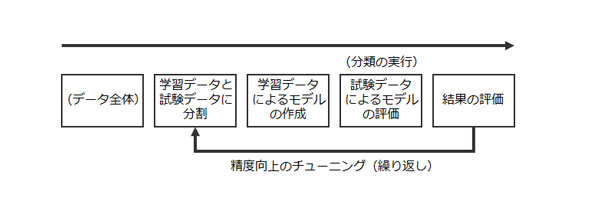
先ほどのベクタ化したファイルを「split」により学習データと試験データに分割します。
ここではランダムに分割する割合(rs(randomSelectionPct))を20%として、学習データ(aozora_train_vectors)を80%、試験データ(aozora_test_vectors)を20%として分割します。
$MAHOUT_HOME/bin/mahout split \ -i nb/aozora_vectors/tfidf-vectors \ -tr nb/aozora_train_vectors \ -te nb/aozora_test_vectors \ -rs 20 \ --sequenceFiles \ -xm sequential -ow
モデルの作成/分類の実行
ナイーブ・ベイズの学習実装「trainnb」を用いて、学習データを入力としてモデル(aozora_model)を構築します。
trainnbのオプションで、入力する学習データファイル(i)、出力するモデルファイル(o)、出力するカテゴリのラベルファイル(li)、カテゴリラベルの出力(el)、出力ファイルの上書き(ow)を指定しています。他に「-c」で補完型ナイーブ・ベイズ(Complementary NaiveBayes)での実行も指定できます。
また、testnbのオプションで、入力するデータファイル(i)、入力するモデルファイル(m)、入力するカテゴリのラベルファイル(li)、出力する実行結果ファイル(o)、出力ファイルの上書き(ow)を指定しています。trainnbと同様に「-c」も使用できます。
$MAHOUT_HOME/bin/mahout trainnb \ -i nb/aozora_train_vectors \ -o nb/aozora_model \ -li nb/aozora_labelindex \ -el -ow
続いて試験実装「testnb」により、構築したモデルを使用して試験データの分類を実行します。
$MAHOUT_HOME/bin/mahout testnb \ -i nb/aozora_test_vectors \ -m nb/aozora_model \ -l nb/aozora_labelindex \ -o nb/aozora_test \ -ow
分類の実行結果/モデルの評価
分類を実行すると、標準出力として分類結果の概要が出力されます。
======================================== Summary ---------------------------------------- Correctly Classified Instances : 80 66.1157% Incorrectly Classified Instances : 41 33.8843% Total Classified Instances : 121 ======================================== Confusion Matrix ---------------------------------------- a b c d e f g h i j <--Classified as 5 0 0 4 0 1 1 2 0 1 | 14 a = 0_総記 0 5 0 3 0 0 1 0 0 4 | 13 b = 1_哲学 1 0 6 2 0 0 0 0 0 0 | 9 c = 2_歴史 0 0 0 7 0 0 0 1 0 2 | 10 d = 3_社会科学 1 0 1 0 3 0 0 0 0 0 | 5 e = 4_自然科学 0 0 1 0 1 20 0 0 0 1 | 23 f = 5_技術・工業 0 0 0 0 0 0 5 0 0 0 | 5 g = 6_産業 0 0 1 2 0 0 0 7 0 1 | 11 h = 7_芸術・美術 0 0 1 0 0 0 0 0 5 4 | 10 i = 8_言語 0 0 0 1 0 0 0 1 2 17 | 21 j = 9_文学 ======================================== Statistics ---------------------------------------- Kappa 0.4739 Accuracy 66.1157% Reliability 59.308% Reliability (standard deviation) 0.277
分類結果を見ると、Summaryとして、試験データ121個に対し、正しく分類されたデータが80個、間違って分類されたデータが41個であり、正解率が66.1%であったことが出力されています。
続いて、その内訳として、混同行列(Confusion Matrix)が、それぞれ本来の(データとして登録している)カテゴリは「行」、分類実行した結果のカテゴリは「列」として出力されています。左上から右下への対角線上の値が正解の数、それ以外の値が不正解の数です。
最後に統計情報として信頼区間に関する情報が出力されています。信頼区間とは、母数がどのような範囲にあるかを確率的に示すものです。
次ページでは、実行結果の追跡方法、分析精度を向上させる例を見ていきます。
Copyright © ITmedia, Inc. All Rights Reserved.




![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。