24時間途切れないサービスで有効なImmutable Infrastructureの運用方法:大規模プッシュ通知基盤大解剖(終)(2/2 ページ)
Pusna-RSの運用ツール
Pusna-RSの運用では以下のツールを活用しています。
- アラート検知:CloudWatch
- リソース監視:GrowthForecast
- リアルタイムモニタリング:Kibana
アラート検知
システムの異常を検知する仕組みとしては、CloudWatchを使用しています。主な監視項目は以下の通りです。
- デバイス登録/配信キューが一定数以上たまっていないか
- アプリケーションのエラーログ
- プロセスの死活監視
- CPU、メモリなどのリソース状況
検知した内容をAmazon SNS経由でメールを送信し、初動をいかに早められるかを念頭に運用しています。
リソース監視
CloudWatchでは、インスタンス単位に情報を保持できる期間が2週間になっているため、リソース監視についてはCloudWatchではなくGrowthForecastを使用しています。Pusna-RSでは、リリースのたびにインスタンスを作り直しているため、GrowthForecast内でサーバー名単位で情報を表示させるようにカスタマイズしています。
リアルタイムモニタリング
運用する上で欠かすことのできないログ収集については、fluentd+Elasticsearch+Kibanaを利用しています。ただし、過去の情報全てをリアルタイムでモニタリングする必要はないため、Elasticsearchに永続化している情報は2週間分としています。全てのログは別途Amazon S3へ転送することで保存しています。
ログ収集の構成は下記の通りです。

具体的なKibanaの活用方法は以下の通りです。
- 定時モニタリング
- 特定のアプリから大量のデバイス登録アクセスが来ていないか
- DynamoDBのスループットエラーが大量に発生していないか
- プッシュの配信がどの程度行われているか
- アラート検知時
- 発生しているエラー内容の確認
上記のユースケースごとにあらかじめKibana上にクエリを保存し、瞬時に確認できるようにしています。
運用を通じて顕在化した課題と打ち手
上記で紹介したような運用、ツールを整えたものの、1年3カ月ほどの実運用の中で課題がいくつか顕在化しました。それらの課題について、対応内容と共に紹介させていただきます。
1アプリのアクセス集中が全アプリの処理遅延につながる
Pusna-RSではアプリのデバイス情報を保存しています。

上記図の通りアプリからデバイス登録リクエストを「登録API」が受け取り、デバイス登録キュー(SQS)にデータを投入します。続いて「登録Worker」がデバイス登録キューからデータを取り出し、DynamoDB、Elasticsearchに永続化します。
リリース当初はこの一連の流れを一つのデバイス登録キューで実施するアーキテクチャになっており、登録Workerは一つのキューからシーケンシャルに処理を行っていました。しかし、このアーキテクチャでは一つのアプリから大量のアクセスが来た場合、他のアプリの登録処理も遅延してしまう課題がありました。
そして、この課題をさらに促進する要因としてDynamoDBのスループットエラーがありました。Pusna-RSではデバイスのデータをアプリごとにテーブルを分けており、それぞれにスループットの上限を設定しています。
しかし、一つのアプリからスループットの上限を上回るアクセスが発生した場合、DynamoDBではスループットエラーが発生します。その際に登録Workerでは対象テーブルへの書き込みを制限するため、一定間隔を空けた後、同一データを再度SQSに投入しています。これにより、一つのアプリから大量アクセスが発生するとリトライ処理が重なり合った結果、他のアプリの登録処理を大幅に遅延させるという事象が実際に発生しました。
この課題を解決するために下記図の通りアプリごとにデバイス登録キューを分割する対応を行いました。また、登録Workerが同時に一つのキューからデータを抽出する速度を一定に保つ作りとしました。

この対応により一つのアプリから大量アクセスが来たとしても他のアプリへの影響を出さない作りとしました。
利用サービスへの考慮不足
プッシュ通知を利用するサービス側への影響を考慮していないが故に発生した課題もありました。高速配信で大量ユーザーに瞬時にプッシュ通知が届くということは、大量のユーザーが短時間の間に一斉にアプリを起動させるという行動につながります。
例えば50万人に対してプッシュを行うとします。その場合、約35秒でプッシュ通知が完了します。そのうちの10%のユーザーがアプリを起動したとすると、その35秒の間で5万アクセスが発生することになります。多くのアプリがアプリ起動時にサービス側のAPIに対して通信を行うため、サービス側のAPIサーバーにも35秒の間に5万回のアクセスが発生します。
上記は例ですが、このような瞬間的なアクセスはサービス側が考慮していない場合もあり、サービス側がシステム負荷増により不安定になる事象が発生しました。
そこで対策としてサービス利用者が配信速度を指定できる機能を追加しました。処理としては下図のように、配信時にデータソース(DynamoDB、Elasticsearch)へアクセスする間隔を指定された速度に基づいて行う作りとなっています。
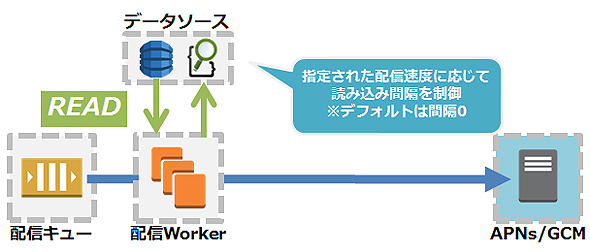 速度制限
速度制限サービス急成長への対応
スマートデバイスの急速な普及に伴い、リリースからの1年間でシステム開発当初の見立ての2倍近い速度でデバイス数が増加しました。Pusna-RSではスケーラビリティを考慮したアーキテクチャとなっており、デバイス数が増加したとしてもシステムに影響を出さないように設計しています。
しかし、設計当初よりデバイスの増加により、どうしても影響が出てしまうと分かっていた箇所があります。それがElasticsearchのシャード数です。
・Elasticsearchのシャード
Elasticsearchでは一つのインデックスをシャードという単位で分割することができ、シャード単位に分散して検索を行います。そのため、インデックスサイズが大きくなる場合はシャード数を増やすことで検索速度を上げることができます。
ただし、シャード数を増やし過ぎると検索結果をマージする処理に時間がかかってしまうためドキュメント数に応じたシャード数を設定することが重要になります。しかし、Elasticsearchの仕様上シャード数はインデックス作成時にしか設定することができません。
そのため、デバイス数が一定件数を超えた場合、シャード数を増やすためにインデックスを再作成するという作業が必要になります。
1シャード数当たりのドキュメントの上限数については、ドキュメントのサイズやフィールド数に依存するため一概には決められないのですが、開発時に事前に検証を行い上限値を見立てていました。
・シャード数の拡張
上記については認識していたのですが、想定以上のスピードでデバイス数が増加したためデバイス数の上限に近づいていることに気付く前に検索速度が低下し、プッシュ通知の配信速度に影響を及ぼす事態が発生してしまいました。
これを受けて、1シャード当たりの保持ドキュメント数を減らすべく、急きょシャード数を増やす対応を実施しました。
デバイス登録処理については前述の通り、SQSを経由して非同期で処理しているため、一時的に登録Workerを停止しElasticsearchへの更新処理を停止することができます。
しかし、配信についてはサービス影響があるため停止することはできません。
そのため、事前にElasticsearchのaliasを活用することで検索には影響が出ないような構成にしています。aliasはインデックスに対して別名でアクセスできるようにする機能で、これを活用することで配信処理に必要な検索を止めることなくインデックスの再作成を実施しました。
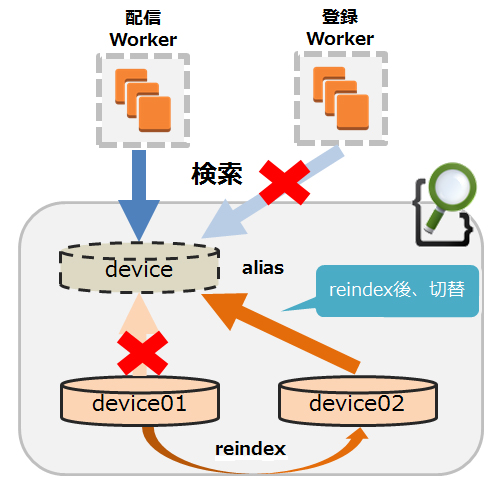 インデックスの再作成
インデックスの再作成最後に
4回にわたって連載をしてきましたが、いかがだったでしょうか? リクルートグループのスマートデバイスプッシュを支える基盤のアーキテクチャや運用、活用した周辺技術について紹介させていただきました。
今回紹介したPusna-RS以外にもスマートデバイスに対して、クラッシュログの収集、バージョンアップ促進、ABテスト実施などを行うための別の基盤も運用しています。リクルートテクノロジーズでは、リクルートグループのビジネスを技術をもって加速させるために日々、開発やチャレンジを行っています。
関連記事
 いまさら聞けない「クラウドの基礎」〜クラウドファースト時代の常識・非常識〜
いまさら聞けない「クラウドの基礎」〜クラウドファースト時代の常識・非常識〜
クラウドの可能性や適用領域を評価する時代は過ぎ去り、クラウド利用を前提に考える「クラウドファースト」時代に突入している。本連載ではクラウドを使ったSIに豊富な知見を持つ、TISのITアーキテクト 松井暢之氏が、クラウド時代のシステムインテグレーションの在り方を基礎から分かりやすく解説する。 徹底比較! 運用監視を自動化するオープンソースソフトウェア10製品の特徴、メリット・デメリットをひとまとめ
徹底比較! 運用監視を自動化するオープンソースソフトウェア10製品の特徴、メリット・デメリットをひとまとめ
運用自動化のポイントを深掘りする本特集。今回は「個々の作業項目の自動化」に焦点を当て、「Zabbix」「JobScheduler」「Sensu」など、運用・監視系の主要OSS、10種類の特徴、使い方などを徹底解説する。 fluentdと定番プラグインのインストール
fluentdと定番プラグインのインストール
第2回ではfluentd本体のインストール方法に加え、代表的なプラグインの機能とインストール方法、マッチングルールについて解説します
Copyright © ITmedia, Inc. All Rights Reserved.




![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。