プライバシー保護データマイニング(PPDM)手法の種類、特徴を理解する:匿名化技術とPPDM(2)(3/3 ページ)
秘密計算
続いて、秘密計算について見てみましょう。秘密計算は、複数の参加者がいるときに、お互いの情報を秘匿したまま演算結果のみを出力する技術の総称で、「Multi Party Computation」や「Secure Multi-party Computation」などと呼ばれています。このような秘密計算を用いることで、他人に知られたくないパーソナルデータを秘匿した状態で、統計値や解析結果のみを取得することができます。
秘密計算には大きく分けて三つの手法に分類されます。それぞれ、秘匿回路計算を用いる手法、秘密分散を用いる手法、準同型暗号を用いる手法です。
秘匿回路計算を用いる手法
秘匿回路計算を用いる手法は、Andrew C. Yao氏(注6)によって提案された手法で、2者がいるときに、一方が暗号化された秘匿回路を構築し、両者がおのおののデータを暗号化した上で回路に入力すると、回路上で演算処理が行われ、もう一方が演算結果を受け取るというものです(図4)。
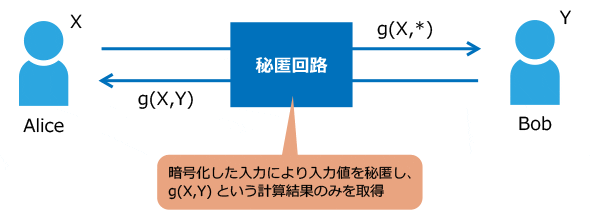 図4 秘匿回路計算のイメージ
図4 秘匿回路計算のイメージこうすることで、計算を通じて両者の情報がお互いに公開されることがないようにしています。
注6:Andrew C. Yao, Protocols for Secure Computations (extended abstract) Proceedings of the 21st Annual IEEE Symposium on the Foundations of Computer Science, pp 160-164, 1982.
秘密分散を用いる手法
「秘密分散」(注7)を用いる手法は、Odded Goldreich氏ら(注8)によって提案されたもので、2者がいるときに、それぞれが自身のデータを分割して断片の一つを他方に預け、乱数を加えた断片をやり取りすることで、元のデータを復元しないまま演算する手法です(図5)。
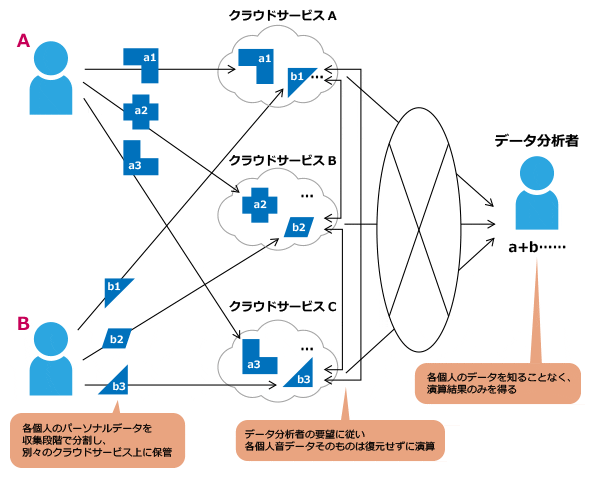 図5 秘密分散を用いた秘密計算のイメージ
図5 秘密分散を用いた秘密計算のイメージこの手法では、一定数以上の断片が集まることがない限りにおいて、元のデータに復元できないようになっています。
注7:秘密分散 暗号化データを複数に分割分散し、あるしきい値以上分散したデータを集めなければ復号できない仕組みのことを指します。
注8:Oded Goldreich, Silvio Micali, Avi Wigderson, How to play any mental game or a completeness theorem for protocols with honest majority, in Proceedings of the 19th ACM Symposium on the Theory of Computing, pp. 218-229, 1987.
準同型暗号を用いる手法
Ronald Cramer氏ら(注9)が提示した秘密計算の手法は、「準同型性を持つ暗号」を用いるもので、暗号化することで個々の情報は秘匿されるものの、秘匿された情報のまま計算を行うことができるようになっています(図6)。
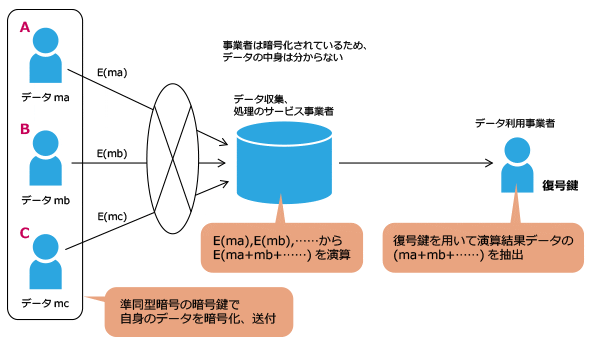 図6 準同型暗号を用いた秘密計算のイメージ
図6 準同型暗号を用いた秘密計算のイメージそして、計算結果のみを復号することで、複数の組織が、保有する情報を公開し合うことなく、計算結果のみを活用することが可能になります。
注9:Ronald Cramer, Ivan Damg?rd, Jesper B. Nielsen, Multiparty computation from threshold homomorphic encryption. 2000.「準同型性を持つ暗号」については、ここでは公開鍵暗号に似たものと考えると分かりやすいでしょう。
なお、準同型暗号を用いた秘密計算は、Craig Gentry氏ら(注10)が「完全準同型暗号」(注11)を示してから研究が盛んに行われており、さまざまな用途への展開が期待されています。しかし、現時点では計算量が膨大であり、実用化にはまだまだ時間が要すると考えられています。
注10:Craig Gentry, Fully Homomorphic Encryption Using Ideal Lattice, STOC 2009, ACM Press, pp.169-178, 2009.
注11:完全準同型暗号 「加法準同型性」と「情報準同型性」の双方の性質を有する暗号。二つの性質を兼ね備えることで理論的に複号することなく任意の演算処理を行うことができる暗号を指します。
秘密計算の手法を利用できるソフトウエア
秘密計算については、ソフトウエアとして実装している事例がいくつか出てきています。イスラエルで開発された「Fairplay」は、秘匿回路計算を実装しています。2004年のThe USENIX Security Symposiumで発表されました。その後、2008年には、秘密分散を用いた秘密計算のアルゴリズムを実装し、三つ以上の組織間のデータを互いに秘匿したまま演算を行うことができるFairplayMPを、ACM Computer and Communications Security Conferenceで発表しています。
エストニアのCYBERNETICA社は秘密分散に基づく秘密計算を行う「SHAREMIND」というソフトウエアを開発しました。このソフトウエアは非常に高速な処理が可能なことが特徴です。実データを用いた実証実験も行われており、複数の企業の財務状況をお互いにSHAREMINDをインストールしたサーバーに登録することで、お互いにデータを公開し合うことなくベンチマーキングができることが示されました。
日本においては、NTTが秘密分散を用いた秘密計算を実用化している他、日立製作所において準同型暗号を用いた秘密計算が開発されています。また、独立行政法人産業技術研究所は、筑波大学、東京大学と共同で、準同型暗号を用いた秘密計算による化合物データベースの検索技術を開発しています。化合物データベースでは、ユーザーはサンプルの情報を、サーバー側はデータベースの情報をお互いに開示することなく、サンプルと類似した化合物がデータベースにあるかどうか検索した結果だけを得ることができるようになっています。
出力データプライバシー保護技術
解析結果においてもプライバシー侵害のリスクが残る場合があります。例えば、「市町村」「年代」「性別」「購買履歴」を記録したデータベースから解析結果のみ表示するサービスを想定してみましょう。データの絞り込みにおいて、人口が少ない地域でかつ、年齢層が少ない年代を指定した場合に、対象が一人になって、結果として特定の個人の購買履歴が表示される可能性があります。
k-匿名性などの高度な匿名化処理をしていればこのような事態は回避できますが、それでも、逐次で解析結果を開示することで特定のデータが明らかになるリスクがあります。例えば、病院Aである日までの患者をk-匿名化したデータの中に40代・男性で「がん」を罹患(りかん)している患者が40人いたとします。さらに次の日までの患者をk-匿名化した場合、40代・男性の「がん」を罹患している患者が41人である場合、それぞれのデータはk-匿名性を満たしているものの、その差分から次の日の患者の40代・男性が「がん」であったことが分かってしまう危険性があります。このような解析結果によるプライバシー侵害のリスクを低減するため、出力結果に制限をかける、あるいは出力結果にノイズを加えるという技術が用いられます。
これらの技術は「クエリ推論制御(Query Inference Control)」と呼ばれ、一定の数値以下の出力を行わない、あるいは出力結果に±5といったあいまい性を持たせる情報(ノイズ)を加えるなど加工が行われます。また、解析結果の差分からデータが特定されることを防ぐため、特定の利用者から異なるクエリが連続して送られてきた場合に、これを拒否するような「クエリ監査(Query Auditing)」という技術も存在します。
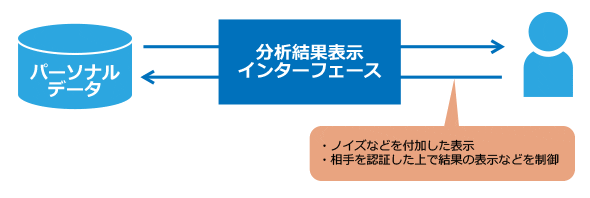 図7 出力データプライバシー保護とクエリ推論制御のイメージ
図7 出力データプライバシー保護とクエリ推論制御のイメージクエリ推論制御、クエリ監査技術を実装したシステム
現時点では、課題対処的な技術実装が一部で行われています。例えば、ハーバード大学医学大学院では、「SHRINE(The Shared Health Research Information Network)」という分散したデータベースから解析結果のみを抽出する技術の実証を進めており、この中でクエリ推論制御やクエリ監査の技術が用いられています。
クエリ推論制御については、これまで定量的な評価指標を用いずに課題対処的に取り組まれてきた側面がありましたが、Cynthia Dwork氏(注12)が、データベースに対するクエリの応答からプライバシーが開示されるリスクについて、「応答が似ている別のデータベースからの応答と区別できなければ安全である」とする「差分プライバシー(Differential Privacy)」という指標を提案しており、現在これに依拠した研究が進められています。
注12:Cynthia Dwork, Differential Privacy, 33rd International Colloquium Automata, Languages and Programming (ICALP 2006) Proceedings Part II, pp.1-12, 2006.
まとめ
本稿で見てきたように、現在PPDMの手法としては大きく三つに分類され、それぞれが一部で実用化されていますが、この分野全体としては発展途上の段階にあるといえるでしょう。
第一回でも紹介した通り、一つの手法が万全ということはなく、複数の手法を組み合わせたり、あるいは運用や制度などと合わせて適用したりすることで、プライバシー侵害のリスクを低減し、データの有効な活用が可能になります。今後は、今まで以上に多くの人たちがさまざまなデータに触れ、活用していくと考えられます。その際、データを安全に解放する側にあるデータ管理者や情報システム技術者は、本稿にあるような手法や議論も理解しておくことが重要でしょう。
Copyright © ITmedia, Inc. All Rights Reserved.




![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。