個人と対話するボットの裏側――大衆化するITの出口とバックエンド:クラウド時代のサービス開発――「個人と対話する機械」を作るヒント(1)(2/3 ページ)
LINEビジネスコネクトが実現した「ユーザー」と「機械」の対話
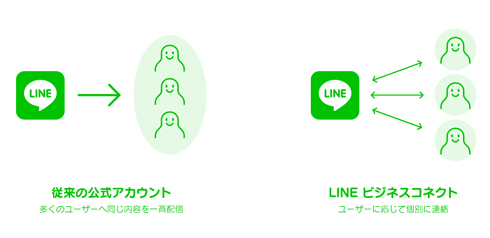
ここで、LINEビジネスコネクトがどのようなサービスかをあらためて整理しておこう。従来、LINEチャットでは「公式アカウント」として、企業などが共通メッセージを一斉配信する仕組みを持っていた。一方、LINEビジネスコネクトは、公式アカウントが一斉配信ではなく個別のユーザーと個別のやりとりを実現する。
 LINEビジネスコネクトの機能イメージ(LINEの公式Webページより抜粋)
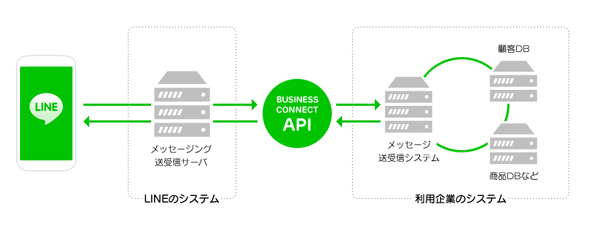
LINEビジネスコネクトの機能イメージ(LINEの公式Webページより抜粋)LINEビジネスコネクトの利用企業は、ユーザーの同意(利用開始時に取得)をもって、「ユーザーを識別する文字列」と「該当トークでのやりとりの内容」を取得することが可能になる。もちろん、ユーザーを識別する文字列はアカウント識別だけを目的としたものであり、それ以外の情報(LINE IDやアカウント名、登録電話番号など)はひも付かない。また、ユーザーが該当企業アカウントをブロックした場合は、全てのデータおよびログが削除されるようになっている。このようにして、各ユーザーの個人情報を秘匿した上で、公式アカウントと各個人ユーザーの対話を実現している。
 LINEビジネスコネクトの機能イメージ(LINEの公式Webページより抜粋)
LINEビジネスコネクトの機能イメージ(LINEの公式Webページより抜粋)個人と企業との対話プラットフォームとしては、例えばTwitterやFacebookといったコミュニケーションチャネルがある。他のソーシャルネットワークサービスでもプライベートメッセージ機能を持っているし、APIを介してメッセージをどのように処理し、応答するかは企業側の裁量にゆだねられている(ユーザーがコマンドを送り、応答を返す)。こうした点では、LINEビジネスコネクトは他の対話プラットフォームとそれほどの違いはないかもしれない。
LINEビジネスコネクトがこれらと異なる点は、個人同士がチャットを展開するのと同じプラットフォーム下で、ごく私的なメッセージを、各個人のアクションに応じてカスタマイズし、作り込める点にある。板澤氏らは、この点に面白さを見いだしたのだという。
始まりは「技術的に面白そうな要素」としての自然言語処理へのチャレンジ
ここで重要なのは、的確な情報が得られるかといった「会話の精度」はもちろんだが、思わずいろんな言葉を入力し、ごく私的な対話の中で「パン田一郎」の反応を楽しみにしてしまうような、利用者側の「楽しさ」をどう演出していくかだ。
LINEビジネスコネクトの仕組みを利用するには、前述のように、個人から送られてくるメッセージに対する応答の仕組みを各社が独自に作り込んでおく必要がある(完全な「人力」応答も不可能ではないか現実的ではないだろう)。個々人と対話をするとして、何をどう対話させるかは各社の腕の見せ所でもある。
そもそもの構想は「会話が成立する公式アカウントを作りたい」というものだ。利用者が投げ掛ける文字列を理解し、「自然言語処理をする、広く言えば人工知能をもったキャラクターと対話するような体験を作りたかった」と板澤氏は述べる。では「パン田一郎」はどのような仕組みになっているのだろうか。
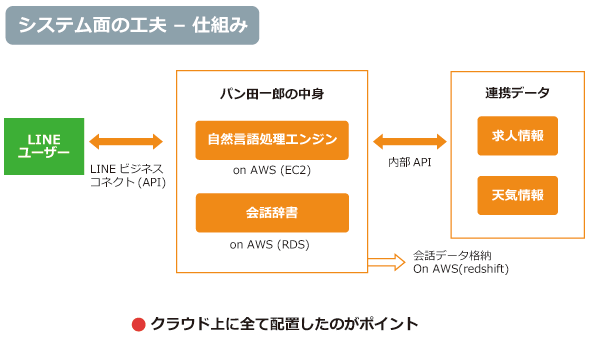
「パン田一郎」を構成する要素は、いわゆる形態素解析/自然言語処理のエンジン。技術的には実は「難しいことはしておらず、基本的には既存の技術を組み合わせ」(板澤氏)だ。
利用しているのは、全文検索エンジン「Apache Solr」と、パターンマッチングを行う「Apache UIMA」、それにインフラはIaaSの「Amazon Web Services」(以下、AWS)とリクルートグループの共通インフラである「rCloud」の組み合わせだ。

利用者が送信してくるメッセージを形態素解析で分解し、それらの言葉をスコアリングする。それを辞書に適用し、選定した上で返答を返すという仕組みは、基本的には他の人工知能会話機能と変わらないといってもいいだろう。しかし、詳細は次回解説するが、ここでも「パン田一郎」には、コンシューマー向けのチャットプラットフォームならではの仕掛けが仕込んである。仕掛けというのは、着想当初から「最低限の形態素解析とスコアリング+メッセージ辞書を使った応答で実装する」という方針のことだ。
プロジェクトのチームメンバーは約80人。そのほとんどは開発経験があり、デジタルマーケティングにも精通したメンバーだ。エンジニア的な発想とマーケティング的視点を重視した結果の方針だという。メッセージ辞書作成にはメンバーの多くが参加、外部のコピーライターも加えて整備したという。
人工知能というと、「受け取ったメッセージを解析し、複数の選択肢を動的に判断、送られてきたメッセージの情報を加味した上で、都度、応答を自動生成する」といった仕組みをイメージするかもしれない。しかし、日本語でこの機能を実現することの技術的なハードルが高いことはもちろんだが、機械的な返答を返してしまうことによるイメージ低下や機会損失を危惧したことも辞書を使う理由になったという。これは、同社が提供するアルバイト情報を必要とする比較的、若年層のLINEユーザーにおいては、そのコミュニケーションの在り方が企業イメージに対して大きなインパクトを持つことを考慮した結果だ。
メイン機能のログデータ、メッセージキューはAWSで対応
「パン田一郎」の企画自体は「1、2カ月程度で決まった」と板澤氏は振り返る。その後、開発には3カ月、ベータリリースには2カ月を要した。
「2014年7月9日にLINEビジネスコネクトのAPIがテストリリースされて、数社がサービスをリリースしたが、独自で応答の仕組みを作り込んでいたのはわれわれが最初です。リクルートグループの中でもこのプロジェクトの開発期間は短めでした」(板澤氏)
LINEプラットフォームを使った対話の中で親近感を持ってもらうことが第一ではあるが、「パン田一郎」の“本業”は、個々のユーザーとの対話の中で、どのような求人情報を求めているのかを把握、ユーザーごとの希望に添った求人情報をレコメンドし、自社が集積するアルバイト情報を参照、求人に応募してもらうことにある。このため、システムは「対話」だけでなく、ユーザーの返信内容の分析結果をベースにマッチングや適切な情報配信をコントロールする必要もあった。
これには、会話のログや個々のユーザーのステータスを把握できる必要がある。コンシューマー向けでは、ユーザーが増えても対応できる仕組みが必要となることから、ログやユーザーステータス情報の蓄積には「AWS RedShift」「Amazon RDS(Amazon Relational Database Service)」といったデータプラットフォームを採用。LINE APIとのメッセージ交換では、分散型キューサービスである「Amazon SQS(Simple Queue Service)」を利用している。
Copyright © ITmedia, Inc. All Rights Reserved.




![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。