Hadoop→Redshift→その先は?――IoT/ハイブリッド時代の最新トレンドを整理する:“仕事で本当に使える”クラウドデータベースの要件 (1/2 ページ)
人間や機械の活動をデータとして取り込むIoTの出現で、クラウド上の「データベースサービス」をエンタープライズでも利用する場面が増えてきた。データベースとクラウドの関係、データ活用のリアルを、ITジャーナリスト 谷川耕一氏の視点でひも解く。
「クラウドデータベース」「ビッグデータ」は使えないバズワードだったのか
システム開発・運用の別を問わず、「クラウドファースト」という言葉が定着しつつある。
とはいうものの、まだクラウド化が積極的に行われていないのがデータベースの領域だろう。データベースに求められるのはパフォーマンスやデータの厳密な管理、信頼性の確保である。一方、多くの場合でクラウドに求められるのは、仮想化や統合・集約、システムおよびプロセスの標準化やリソース最適化などだ。それ故、データベースとクラウド環境とでは、いまひとつ折り合いが付かないことも少なくなかった。
しかしながらここ最近は、数多くのクラウド上のデータベースサービスが出てきている。どういった要求があるときに「どんなサービスを選択すればいいのか」「クラウドとオンプレミスをどう使い分けたらいいのか」はかなり迷うところだ。
使えそうで使えなかったHadoopと「ビッグデータ」
ところで、「ビッグデータ」という言葉が日本で使われ始めたのは2010〜11年ごろだろうか。既にクラウドはあったが、ビッグデータ処理をクラウドで行うことは現実的ではなかった。なぜなら、当時、ビッグデータソリューションの発想は、かつてのデータウエアハウスの延長線上にあるものだったからだ。
とにかくデータ量が桁違いに増える。そして、その増えるデータにはさまざまな非構造化データも入ってくる。結果、大容量ストレージや高性能サーバー、高速処理ができるデータベースが必要になる。これらビッグデータ処理に必要な構成をクラウド環境で実現するのは、当時はまだ少し難しかったのだ。
とはいえ、ビッグデータはストレージベンダーやデータベースベンダーが喜々として担ぎ上げ、瞬く間にIT業界のブームとなる。このとき新たに注目されたのが「Hadoop」だ。非構造化データを大量に取り込みたい。それは従来のリレーショナルデータベースでは難しく、HadoopとMap Reduceのような分散ファイルシステムとNoSQL型の分散処理エンジンが必要という話になった。
実際のところ、この流れでビッグデータブームは巻き起こったが、現実化したシステムはそれほど多くはなかっただろう*。増え続けるデータに合わせて、企業はそう簡単にストレージやサーバーを増やせるわけでもなく、ストレージやサーバーを増やせるわけでもなく、仮に大量にデータを溜めることができても、データ量が多ければ多いほど取り出して分析するのには手間もコストも掛かることが分かってくるのだ。
またHadoopは100ノード、1000ノードと分散化した構成を比較的安価に構築できたが、実際にそのような多ノード構成のシステムを運用できる体力、技術リソースを持った企業はそれほど多くはなかった。一部先端技術が好きでエンジニアが自ら手を下せるような企業を除き、Hadoopの利用は数ノードから数十ノード構成で分析前のデータクレンジング用などのバッチ処理程度にとどまっていることも多い。
* Hadoopの利用は、JavaやHDFS、分散アルゴリズムなどへの理解が必要であったため、一部の先進的なITエンジニアを持つ組織以外での普及は限定的であった。この問題については「Hadoopは「難しい・遅い・使えない」? 越えられない壁がある理由と打開策を整理する」(@IT)でも言及している。
Redshiftを機に近づいたエンタープライズITとデータベースクラウド
このように、クラウドとデータベースとの間には大きな隔たりがある状況が続いていたのだが、この状況を変化させるきっかけとなる出来事が起きた。2012年末にAmazon Web Services(AWS)が発表した「Amazon Redshift(Redshift)」だ。Redshiftは、大量データを投入しても高パフォーマンスを発揮するオープンソースのRDBMSである「PostgreSQL」と互換性があるデータベースサービスだ。クラウド上のRDBMSであればスケールアウトが容易であることから、Hadoopで無理に分散させなくてもAWSがクラウドで拡張性は確保してくれる。「取りあえずビッグデータを試したい」というユーザーには最適な環境が生まれたのだ。
Redshift登場以前は、クラウド上のデータベースサービスの多くが、テストや開発用途、あるいは小規模なWebサービスのリポジトリ的な利用だったのに対し、Redshiftなら企業のデータウエアハウスをクラウドに置き替えることができ、さらにパブリッククラウドのメリットで、それをかなり安価に実現できる。これはエポックメイキング的な出来事だったといえよう。
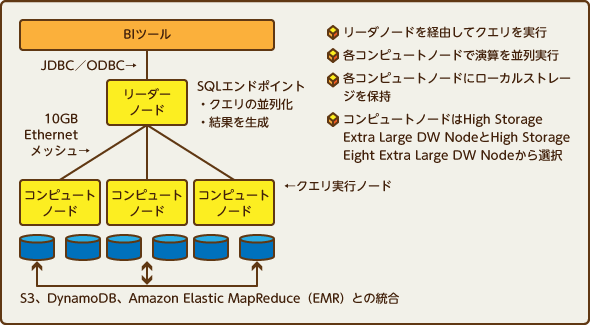 Amazon Redshiftのアーキテクチャ 「Redshiftがもたらすデータ分析環境の新時代(Database Watch 2013年1月版)」より。クラウド上でストレージやサーバーノードだけでなく、リレーショナル型のデータベースをサービスとして利用できるようになったことで、データウエアハウス的なビッグデータ活用をクラウドデータベースで実施しようという機運が高まった
Amazon Redshiftのアーキテクチャ 「Redshiftがもたらすデータ分析環境の新時代(Database Watch 2013年1月版)」より。クラウド上でストレージやサーバーノードだけでなく、リレーショナル型のデータベースをサービスとして利用できるようになったことで、データウエアハウス的なビッグデータ活用をクラウドデータベースで実施しようという機運が高まったこの時期から、エンタープライズ用途で利用できるクラウド上のデータベースサービスが登場し始める。例えば、マイクロソフトはIaaS(Infrastructure as a Service)上でのSQL Serverの利用だけでなく、PaaSの「Azure SQL Database」の制限を緩和し、エンタープライズ用途でも使いやすくしつつある。またAWSもRedshiftに続いて、MySQL互換で拡張性と高速性を両立する「Aurora」の提供を開始した。
IBMもSoftLayerを買収して以降、クラウドでの展開を一気に加速している。データベースのサービスについてもDB2 BLUの技術を活用する分析基盤「dashDB」の提供を開始し、買収により得たNoSQLの「Cloudant」もある。さらには、オラクルもパブリッククラウド上で「Database Cloud」のサービスを開始している。
Copyright © ITmedia, Inc. All Rights Reserved.




![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。