日本IBMがソフトバンクとIBM Watson日本語版を提供開始、6種のAPIとは:どんな用途に使われていくか
日本IBMとソフトバンクが2016年2月18日に発表したIBM Watson日本語版。その用途と、日本語版で提供される6種のAPIについて取り上げる。
日本IBMとソフトバンクは2016年2月18日、IBM Watson日本語版を正式提供開始したと発表した。両社は2015年2月にWatsonの共同展開を発表。日本国内における事業展開の準備を進める一方、営業活動を始めていた。発表時点で両社は十数社の顧客を獲得、さらに約150社からの引き合いがあるという。
WatsonはIBM Bluemix上で提供されているコグニティブコンピューティングAPI。現在、約30のAPIが提供されている(「一般提供」「ベータ」「実験的」と、APIのステージには違いがある)。日本語版では当初、このうち6種のAPIが提供される。

二社は企業におけるWatsonの利用を、適用業務領域の検討や効果の試算、Watsonのトレーニングを含む開発などの形で支援するサービスを展開する。システムインテグレーター、開発者、コンサルタント、スタートアップ企業などの「エコシステムパートナー」を通じ、事業を拡大していきたいという。
米IBM Watson開発担当シニアバイスプレジデントのマイク・ローディン(Michael Rhodin)氏は、既存企業における産業・業種特化型の適用を推進していく一方、スタートアップ企業にもWatsonを活用して独創的なサービスを開発してもらいたいと話した。

同時にWatsonを活用したサービスが提供開始
発表の場には、Watsonの利用を開始している企業、利用を検討している企業5社が登場。それぞれの用途について話した。
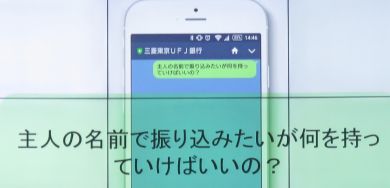 三菱東京UFJ銀行のLINEサービスでは、例えば「主人」という言葉を「自分以外」と認識、適切な答えを自動的に用意する
三菱東京UFJ銀行のLINEサービスでは、例えば「主人」という言葉を「自分以外」と認識、適切な答えを自動的に用意する三菱東京UFJ銀行は、同社が LINE公式アカウントで提供している「Q&A サービス」で、発表当日にWatson日本語APIを利用開始したと説明した。質問にあいまいな言葉が使われていた場合にも、意図を理解することで、適切な回答ができるようにしていくという。
製薬会社の第一三共は、医薬品研究テーマ選定や研究管理プロセス支援にWatsonを活用し、典型的には発売まで10年、1000億かかる創薬R&Dの効率化を進めていきたいという。また、医師からの緊急な医薬品情報リクエストへの対応や、副作用情報のリアルタイム分析による当局への迅速な報告といった用途への適用も検討する。
利用者の感性に合ったファッションを提案する「ファッション人工知能アプリSENSY」を提供しているスタートアップ企業のカラフル・ボードは、Watson APIを利用して、ユーザーインタフェースの拡張を進めるという。現在のSENSYは、アプリが提示したファッションに対する「好き」「嫌い」で自分の好みを伝え、アプリをトレーニングするようになっている。Watsonを利用すれば、より自然な対話スタイルで、「今年の夏はどんなファッションを買えばいい?」「春物」「もう少し明るめ」などのあいまいな表現に応えられるアプリに進化できるという。
健康関連サービスのFiNCは、利用者の健康情報に基づくネット経由の食事指導で、アドバイスを行う専門家を支援、回答候補を提示する仕組みを構築するという。また、将来は画像による食事指導の自動化などにも生かしていきたいとしている。
人材紹介のフォーラムエンジニアリングは、Watsonを活用した、エンジニアと求人企業との人材マッチングシステム 「InsightMatching」を4月1日に提供開始するという。同システムでは人に依存してきたマッチングを、産業トレンドや技術動向に関するデータの蓄積・分析で支援し、効率化と顧客の満足度向上を目指すという。
Watson日本語版で提供開始された6つのAPIとは
既述の通り、Watson日本語版では、発表時点で6種のAPIが提供される。音声関連で「音声認識」「音声合成」、自然言語処理関連で「自然言語分類」「検索およびランク付け」「文書変換」「対話」だ。
「音声認識」は音声をテキストに変換、「音声合成」はテキストを音声に変換するもの。「文書変換」はWordやPDFなど各種の文書フォーマットを、検索などWatsonの他の機能が利用できるように変換するものだ。
「対話」はユーザーとのテキストによる対話を事前にスクリプト化しておき、実行する機能。ある質問を投げかけ、これに対するユーザーの入力した回答によって条件分岐させ、次の質問に移る形で、ユーザーの望んでいることを引き出していくなどができる。これを「音声合成」「音声認識」と組み合わせれば、音声による対話のアプリケーションを構築できる。
「自然言語分類」は、機械学習の適用によって、短いテキストの背後にある意図やテーマを分類する仕組みを準備しておき、これを使って新たなテキストを識別し、最適と思われるカテゴリを返すもの。「意味を理解」するわけではないが、「分類」という手法を適用することで、上記の三菱東京 UFJ 銀行の例にもあったように、あいまいな表現にも対応しやすくなる。「対話」と組み合わせれば、ユーザーの入力に基づいて、対話型で適切な商品・サービスの担当者や情報へのナビゲーションもできる。機械学習に関する知識は不要という。
「検索およびランク付け」はオープンソース分散サーチエンジンのApache Solrに機械学習を組み合わせた機能。検索結果とそのランク付けに対するトレーニングを重ねることで、検索精度を高めていくことができる。
今回の日本語版に含まれていない既存APIには、次のものがある。
一般提供中:「AlchemyLanguage」(感情などを含む高度なテキスト分析)、「Concept Insights」(Wikipediaを活用したコンセプトグラフに、テキストをマッピング)、「Language Translation」(機械翻訳)、「Personality Insights」(テキストから人の性格などを分析し、属性情報として提示)、「AlchemyVision」(画像からオブジェクトを識別)、「AlchemyData News」(過去60日間のニュースやブログコンテンツのデータベース検索)、「Tradeoff Analytics」(パレート最適化に基づく判断支援)
ベータ:「Concept Expansion」(婉曲な表現やくだけた表現を一般的な表現に変換)、「Relationship Extraction」(テキスト内容の関連性を提示)、「Tone Analyzer」(テキストのトーンを分析して提示)、「Visual Recognition」(画像に含まれたオブジェクトや内容を識別し、分類)
実験的:「Visual Insights」画像分析に基づくユーザーターゲティング)
Copyright © ITmedia, Inc. All Rights Reserved.




![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。