Recurrent Neural Networkとは何か、他のニューラルネットワークと何が違うのか:Deep Learningで始める文書解析入門(1)(1/2 ページ)
本連載では、Deep Learningの中でも、時系列データを扱うRecurrent Neural Networkについて解説。加えて、その応用方法として原稿校正(誤字脱字の検知)の自動化について解説します。
この記事は会員限定です。会員登録(無料)すると全てご覧いただけます。
Deep Learningで原稿校正(誤字脱字の検知)の自動化は可能なのか
筆者が所属するリクルートテクノロジーズでは機械学習をはじめとしたデータ解析を用いた社内向けソリューションをAPIで提供するプロジェクト「A3RT(Analytics And Artificial Intelligence API via Recruit Technologies)」が2016年に発足し、自然言語処理や画像解析、レコメンドなどの分野において研究開発と実践への導入が盛んに行われています。
A3RTにおいて、筆者が取り組んでいる課題の1つとして「校正」があります。
リクルートはもともと紙を媒体とする情報誌を発行している会社で、ネット化が進んだ現在でも大量の求人票や記事を日々作成しています。作成される原稿はカスタマーとクライアントをつなぐ重要な媒体であり、そこに間違いがあると大きな機会損失となります。そのため、現状では人手でその原稿を校正するため膨大なコストと時間がかかっています。この課題に対し、機械学習などの技術を使って効率化や工数の削減ができないかという相談を受けたのが始まりです。
本連載では、Deep Learningの中でも、時系列データを扱うRecurrent Neural Network(以下RNN)について解説します。加えて、その応用方法として筆者が取り組んでいる原稿校正(誤字脱字の検知)の自動化について解説していきます。
第1回ではRNNの概要と一般的な使い方について、第2回では原稿校正の自動化(誤字脱字の検知)という課題に対してRNNをどのように活用しているのかについて解説し、第3回では精度を上げるためのチューニングやアルゴリズムについて解説する予定です。
内容としては、機械学習についての知識や経験があることを前提として話を進めていきます。
「Deep Learning」と「ニューラルネットワーク」の基礎知識
ここ数年で「Deep Learning」という言葉がアカデミックな場やITに強い企業のみならず、一般の企業やテレビなどでも広く使われるようになってきました。読者の中にも、Deep Learningという言葉は聞いたことはあるが、どういうものかは分からない、もしくはとんでもなく精度の高い予測や分類のできる魔法のような機械学習法と思われている方もいるかもしれません。
Deep Learningとは、ひと言でいうと、「ニューラルネットワークを多層構造につなげた機械学習手法」の総称です。
ニューラルネットワークの発展
ニューラルネットワーク自体の歴史は古く1950年代にフランク・ローゼンブラット氏が「パーセプトロン」という人間の脳にあるシナプスの情報伝達を模した識別モデルを提案したのが始まりといわれています。
ニューラルネットワークを多層につなげるという発想自体は1970年代に出ていましたが、莫大な計算量を処理できる基盤がないことや精度の問題もあり、しばらく日の目を浴びることはありませんでした。
しかし、その間にも研究は続けられており、2012年の「ILSVRC(ImageNet Large Scale Visual Recognition Challenge)」という物体認識の精度を競うコンペにおいて、ジェフリー・ヒントン氏率いるトロント大学のチームがDeep Learningを用いて、2位以下に10%もの差を付けて優勝しました。これを皮切りに、グーグルやフェイスブックといった大企業がDeep Learningを用いた研究成果を発表するなど、再びニューラルネットワークへの関心が高まっていきました。
最近ではニューラルネットワーク開発企業であるGoogle DeepMindによって開発された「AlphaGO」が囲碁5番勝負で韓国のプロ棋士を破るなど、日々研究開発が進んでいます。
Deep Learningは「教師あり学習」
今日では計算基盤の発展やライブラリの充実により、誰でも手軽にDeep Learningを試せるようになりました。しかし、Deep Learningの多くは大量のラベル付きデータや正解データを必要とする「教師あり学習」であり、精度を求める際にはこの教師データを集めるというフェーズが大きなハードルになると思います。
中にはこのような課題を克服するために、教師データが少ない場合でも、精度を担保するモデルも考案されています(参考PDF)。
Deep Learningの代表的なモデル――画像解析、音声認識、文書解析
前述した通り、Deep Learningは特定の機械学習手法ではなく、ニューラルネットワークを多層につなげたモデルの総称です。代表的なモデルとしては、主に画像解析に用いられる「Convolutional Neural Network(CNN)」や音声認識に用いられる「Time-Delay Neural Network」などがあります。その中でも今回の連載では、主に文書解析に用いられるRecurrent Neural Network(RNN)について述べていきます。
「校正」(誤字脱字の検知)における課題
「校正」(誤字脱字の検知)といってもいろいろなバリエーションがあります。求人票を例にして考えてみると、クライアントが面接などを開催する日付と曜日の対応が間違っていると大きな機会損失につながります。また、電話番号やURLが無効になっていると、同じく機会損失になります。これらのような校正項目に関しては、正規表現や辞書を用いてルールベースで拾うことができます。しかし、誤字脱字に関してはルールベースだけで修正箇所を全て拾い上げるには、難しい面があります。
例えば「私は妄奏する。」というように「妄奏」という辞書に存在しないワードがある場合は辞書と突き合わせれば検知ができます。では、「税金を収める。」という文章はどうでしょうか?「収める」はこの文脈では「納める」が正解ですが、「収める」も辞書には存在するためルールでの検知は難しそうです。もちろん、n-gramを利用する古典的言語モデルを利用すれば検知はできそうです。しかし、実際に適用する際には非常に長い文章が存在する可能性もあるため、n-gramモデルでは不十分な精度になります。
そこで、長期的な系列状態を使用し、かつ可変長の入力にも対応できるRNNを利用して、現在この問題に取り組んでいます。
「Recurent Neural Network」とは
RNNとは、音声や映像、言語といった「時系列の流れに意味を持つデータ」の予測や分類に用いられるモデルです。
時系列の流れを持つことで何ができるのでしょうか。まずは、通常のNeural Network(FeedForward Neural Network)について説明します。
通常のNeural Network(FeedForward Neural Network)の場合
Neural Networkは下記のように3ユニットの階層型のネットワークで表すことができます。ユニットは、左から入力層(インプット)、隠れ層(中間層)、出力層(アウトプット)です。
シンプルに説明するため、ここでは「ある単語の後に続く、次に来る単語を予測する」タスクを考えます。ある単語をインプットしたら、隠れ層において、アウトプットとして次に来る単語が何になるかの“重み”を調整します。この重みは、後ほど紹介するchainerなどのフレームワークでパラメーターを与えて調整します。
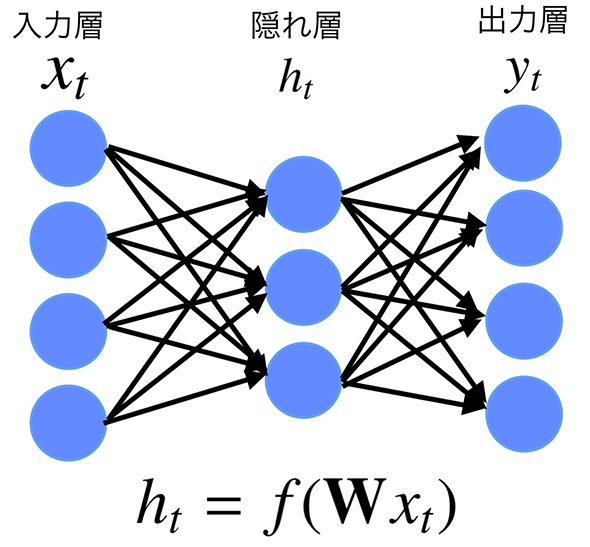 図1 Feedforward Neural Networkのモデル図
図1 Feedforward Neural Networkのモデル図例えば、入力の文として「私は野球が好きです。」という文章が与えられたとします。まず、この文章が単語で分かち書きされ、下記のような「単語の並び」に変換されます。
["私","は","野球","が","好き","です","。"]
では、"野球"という単語の後に続く単語を学習するとしましょう。インプットには"野球"を表すベクトルを入れ、アウトプットに"が"を表すベクトルと近くなるように各ユニットを結合する重みを調節します。
"野球"→"が"
通常のFeedForwardなNeural Networkでは、"野球"という単語がインプットとして与えられた際に、隠れ層で「次元縮約」(“特徴”をより低次のベクトルで表現すること)を行い、アウトプットが"が"になるように重みを調整します。その際、その前にインプットされた単語、つまり"私"や"は"の影響は考慮されません。
["野球","が","好き","です","。"]
一方で、直前が「私は」とは違う単語の場合(例えば「サッカーは嫌いだが」とか「サッカーも」の場合)は、"野球"の後が"は"や"も"になる可能性もあり得ます。
["野球","は","好き","です","。"]←直前が「サッカーは嫌いだが」の方が自然 ["野球","も","好き","です","。"]←直前が「サッカーも」の方が自然
しかし、通常のFeedForwardなNeural Networkでは、直前に来る単語を考慮せずに単に「"野球"の後に"が"が来る」ということしか学習していないのです(図2)。
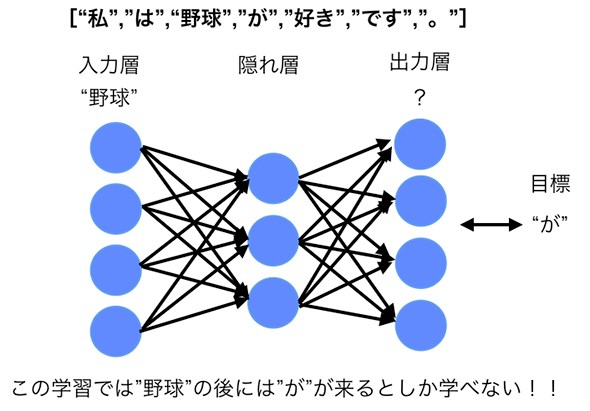 図2 Feedforward Neural Networkによる学習
図2 Feedforward Neural Networkによる学習関連記事
 「AI」「機械学習」「ディープラーニング」は、それぞれ何が違うのか
「AI」「機械学習」「ディープラーニング」は、それぞれ何が違うのか
「AI」「機械学習」「ディープラーニング」は、それぞれ何が違うのか。GPUコンピューティングを推進するNVIDIAが、これらの違いを背景および技術的要素で解説した。 AlpacaDBがDeep Learningを使った自動取引アプリを公開
AlpacaDBがDeep Learningを使った自動取引アプリを公開
米AlpacaDBは、為替市場での自動取引アルゴリズムを設計できるiPhone向けモバイルアプリ「Capitalico(キャピタリコ)」の提供を開始した。 2015年に大ブレイクした「Deep Learning」「ニューラルネットワーク」を開発現場視点で解説した無料の電子書籍
2015年に大ブレイクした「Deep Learning」「ニューラルネットワーク」を開発現場視点で解説した無料の電子書籍
人気連載を1冊にまとめてダウンロードできる@ITの電子書籍。第16弾は、「いまさら聞けないDeep Learning超入門」だ。
Copyright © ITmedia, Inc. All Rights Reserved.




![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。