校正担当者必見!? 地味な誤字脱字で泣かないためのRecurrent Neural Networkのスゴイ生かし方:Deep Learningで始める文書解析入門(2)(2/2 ページ)
予測フェーズ(次に来る単語の確率をRNNで算出する)
正しい文章を大量に学習したモデルを作成した後は、そのモデルを用いて誤字脱字の検知を行っていきます。前回の記事で紹介したRNNの利用例としてレコメンドがありました。それは大量の閲覧、購入ログを利用して、「アイテムA→アイテムB→アイテムC」を閲覧した後には「アイテムD」を見る確率が高いのでレコメンドしようというものでした。
ここで注意したいのは、「アイテムA→アイテムC→アイテムB」を閲覧した場合の次に来るアイテムと「アイテムA→アイテムB→アイテムC」の次に来るアイテムは必ずしも一致はしないということです。
これを「私は野球が好きです。」という文書データで考えてみると、「"私"→"は"→"野球"」と来た場合の次に来る単語を予測する問題として考えられます(図2)。
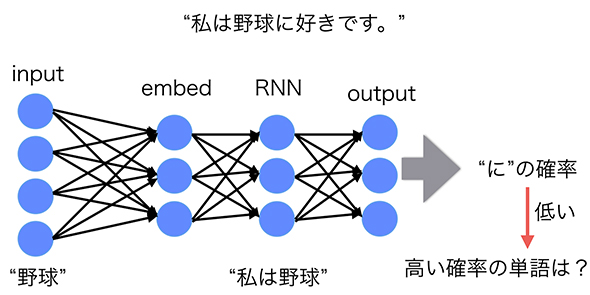 図2 予測フェーズ
図2 予測フェーズただし、今回は正しい文章を学習したモデルを用いて誤字脱字を検知したいので、「私→は→野球」の後に来る単語として「が」という単語がどのぐらい適当か?」(出現する確率はいくらぐらいなのか?)というように考え、組み合わせとしてあり得ない、つまり、出現する確率が低いものであれば、誤字脱字として検知を行います。
「私は野球が好きです。」という文章は文法的に正しいですが、「私は野球に好きです。」といった文章を入力として与えられた場合には、「私は野球」までをモデルに入れたところで、次に来る「に」という単語に対して低い確率を出力するため、誤字脱字として検知ができるわけです。
問題点と2つの解決方法
しかし、ここで疑問を持つ方がいると思います。
先ほどの「私は野球に好きです。」という文章を例に考えてみましょう。前から順番にモデルに入れていき、「私は野球」の後の「に」で確率が低くなり誤字脱字として検知をすると述べましたが、この場合「に」以降の文字列を完全に無視していることになります。
実はその後ろが「好きです。」ではなく「夢中です。」だとしたらどうでしょう?「私は野球に夢中です。」となり、誤字脱字として検知すべき文章ではないことが分かります。このような問題に対応する方法として、次の2つの方法が考えられます。
1つ目は「文章を後ろ向きに学習させたモデルを作成し、逆方向からも予測を行う」方法です。そうすると、「私は野球に夢中です。」という文章に対しては、「。→です→夢中」と入力され、その次(文章的にはその前)の単語である「に」に対して確率を算出します。
この方法の短所としては、順方向と逆方向の2つのモデルを学習させなければいけない点と2つのモデルに対して予測を行い、結果を統合するため、応答速度が遅くなります。
2つ目の方法としては、「一度誤字脱字として検知した後に、文章全体に対してその文章の生成確率を算出し、その確率が高ければ誤字脱字の検知をやめる」というものが考えられます。この方法の場合は、モデルは1つでよく、単純に文章の生成確率を求めるだけなので、それほど応答速度に影響はありません。
ただし、文章の長さが非常に長い場合などは、精度が高くならない可能性もあります。
文章全体の生成確率を求めて、誤字脱字の検知をするかどうか判断する方法の例
今回のタスクでは、計算リソースや応答速度の面から、筆者は2つ目の方法を選択しました。
実際に、この時に誤字脱字を検知した文章の例を図3に記します。「Suggestions」となっているところは、誤字脱字として検知した単語に代わって入れるべき単語の候補を挙げています。単純に、誤字脱字として検知した単語までの系列(文字列)を入力したときに、次に来る単語として確率が高いものの上位を挙げています。
 図3 誤字脱字を検知した文章の例
図3 誤字脱字を検知した文章の例例えば、「昭和51年の操業以来」という文章(変換ミスを意識した文章)に対しては、「P=0.000002」で「Low Probability」(生成確立が低い)と判断したため、「操業」がおかしいと検知をしています。「Low Probability」ではない場合は、誤字脱字の検知を行わないということです。
誤字脱字の検知を行った上で、「操業」の代わりに来るべき確率が高い単語として「創業」(P=0.489958)や「設立」(P=0.247593)といった単語をサジェストしており、納得感がある結果となっています。
精度の壁
このようにRNNを応用して誤字脱字の検知に取り掛かったのですが、初めは思うように精度が出ませんでした(図4)。
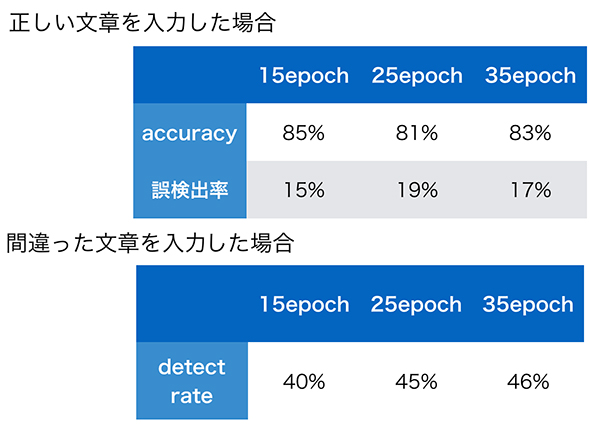 図4 RNNを応用した誤字脱字の検知の結果
図4 RNNを応用した誤字脱字の検知の結果正しい文章に対する文章全体の検出確率(正しい文章を正しいとする確率)は80%を超えていますが、間違った文章に対する文章全体の検出確率(間違っていることを指摘する確率)は50%を切っており、このままでは実用的ではありません。
例えば、「文章全体の生成確率がどのくらいまで低ければ、誤字脱字の検知するのか」といった閾値を変えることで、「間違った文章を入力したときに検知をする」精度を上げることはできます。しかし、それは「正しい文章を入力したときに誤検知をしない」精度とトレードオフになるため、根本的な解決にはなりません。システムとしては、確かに誤字脱字を検知してくれますが、正しい文章に対しても誤字脱字の検知が行われるようでは、信頼を得ることはできないのです。
そこで次回は、「どのようにして問題を解決し、精度を上げていったのか」を紹介します。
筆者紹介
高橋 諒(たかはし りょう)
リクルートテクノロジーズ ITソリューション統括部 ビッグデータ部所属
2015年入社。主にリクルートが抱えるサービスの行動ログ分析とエンハンス開発を行っている。その一方でR&Dとして、文書解析を用いた社内向けAPIサービスの開発推進を積極的に行っている。
関連記事
 「AI」「機械学習」「ディープラーニング」は、それぞれ何が違うのか
「AI」「機械学習」「ディープラーニング」は、それぞれ何が違うのか
「AI」「機械学習」「ディープラーニング」は、それぞれ何が違うのか。GPUコンピューティングを推進するNVIDIAが、これらの違いを背景および技術的要素で解説した。 AlpacaDBがDeep Learningを使った自動取引アプリを公開
AlpacaDBがDeep Learningを使った自動取引アプリを公開
米AlpacaDBは、為替市場での自動取引アルゴリズムを設計できるiPhone向けモバイルアプリ「Capitalico(キャピタリコ)」の提供を開始した。 2015年に大ブレイクした「Deep Learning」「ニューラルネットワーク」を開発現場視点で解説した無料の電子書籍
2015年に大ブレイクした「Deep Learning」「ニューラルネットワーク」を開発現場視点で解説した無料の電子書籍
人気連載を1冊にまとめてダウンロードできる@ITの電子書籍。第16弾は、「いまさら聞けないDeep Learning超入門」だ。
Copyright © ITmedia, Inc. All Rights Reserved.




![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。