機械学習の作業がはかどる新ツール「Workbench」とは? TensorFlowやAWSも使える。Microsoft Tech Summit 2017:イベントから学ぶ最新技術情報
マイクロソフトが提供する機械学習向け新サービス&ツール。Azure、AWS、GCP、オンプレスミスなどに対応。TensorFlow、Chainerなどのディープラーニングフレームワークに、PyCharmやVisual Studio Codeなどのコードエディターも使える。
ご注意:本記事は、@IT/Deep Insider編集部(デジタルアドバンテージ社)が「deepinsider.jp」というサイトから、内容を改変することなく、そのまま「@IT」へと転載したものです。このため用字用語の統一ルールなどは@ITのそれとは一致しません。あらかじめご了承ください。
日本マイクロソフトが11月8日〜9日に開催したインフラエンジニア&アーキテクト向けイベント「Microsoft Tech Summit 2017」の基調講演では、デジタルトランスフォーメーションに対するマイクロソフトのビジョンが紹介され、それを実現するための技術や事例が紹介された。基調講演の中盤に登場した日本マイクロソフト株式会社 代表取締役社長の平野 拓也 氏は、デジタルフォーメーションを加速するためのマイクロソフト最新テクノロジとして、下記の3つの主要分野を提示した(図1)。
- Mixed Reality(MR)
- Artificial Intelligence(AI)
- Quantum Computing(量子コンピューティング)

本稿では、このうち「AI(人工知能)」にフォーカスし、その発表内容をいくつかピックアップする。
マイクロソフトは、AIに対する投資を加速させてきており、これまでに蓄積されているAIの技術と人材を1つにまとめてきているとのこと。
一つ目に、昨年10月にAI&Research Groupが設立され、7500人以上の開発者が日々、AIテクノロジを開発している。
二つ目に、AIが自分のものとしてもっと使いやすくなるよう、下記のようなマイクロソフトにとって未知の分野において投資や開発を推進しているとのことだ。
- AIプラットフォーム: Cognitive ServicesなどのAIサービス、ディープラーニングのためのハードウェアやプラットフォームなど
- 製品へのAIの組み込み: AIのパワーをマイクロソフトの製品やサービスに組み込んでいくことに関する研究と投資
- AIビジネスソリューション: 顧客のビジネスやサービスに展開できるAIソリューションの開発
このようなAI戦略に関する現状と方向性の説明の後、日本マイクロソフト株式会社 執行役員 最高技術責任者(CTO)の榊原 彰 氏が登壇し、「Workbench」という新ツールについて一通りの概要を説明した。筆者にとってそのツールが興味深かったので、本稿では基調講演で語られたそのツールに関する説明を書き起こして、読みやすいように独自にまとめ直した。
なお、以下の一部の内容は、自分で試してみた経験や「MAI003: 新生 Azure Machine Learning services 徹底解説」(日本マイクロソフト株式会社 藤本 浩介 氏)のセッションで得た知識で説明を補っている箇所があり、基調講演では出なかった話も少し書き足してあるのであらかじめご了承いただきたい。ここからは、スピーカーによる説明をそのまま書き起こしたスタイルで記事化していく。
Azure Machine Learning Workbenchとは?
マイクロソフトは3年ほど前からAzure Machine Learning(Azure ML)というサービスを提供しています。このサービスでは、「Azure Machine Learning Studio」という、GUI操作ができるツールがAzure上で使用できました。このツールは、すでに数十万モデルが作成された実績のあるサービスとなっています。
これとは別に、先日の9月25日〜29日に米国で開催されたMicrosoft Ignite 2017において、「Azure Machine Learningサービス」という新サービスが発表されました。その中心的な作業環境となるのが「Azure Machine Learning Workbench(ワークベンチ)」というツールです(図2)。

Workbenchは、「もっと速いマシンを使いたい」「より高度にディープラーニングを実践したい」「Azureのサービス以外でも機械学習のツールを使いたい」というニーズから生まれたツールで、各自のPCにインストールして使います(デスクトップアプリケーションとコマンドラインインターフェースが含まれています)*1。すでに現在、このツールのプレビュー版がダウンロード可能です(Windows版:AmlWorkbenchSetup.msi/macOS版:AmlWorkbench.dmg)。
*1 Workbenchは、ローカル環境でディープラーニングなどの機械学習の作業に使用できる。ただし使用するには、Azure上にAzure Machine Learning Experimentation(※日本リージョンにはまだ提供なし。DEVTESTという無料枠あり)という実験アカウント(と同時にモデル管理アカウント)を作成する必要がある点に注意が必要だ。詳しくは「公式サイト: Azure Machine Learning サービスのインストールに関するクイックスタート」を参照してほしい。
ちなみにWorkbench以外にも、このAzure Machine Learningサービスには、機械学習モデルの作成実験を実施するためのExperimentation Service(実験サービス)や、 クラウド/オンプレスミス/IoTエッジデバイス環境にデプロイした学習済みモデルを管理するためのModel Management Service(モデル管理サービス)といったサービス群が含まれており、Workbenchは機械学習のライフサイクル全体の中でそれらのサービス群と組み合わせて使用することになります。
機械学習は、基本的に以下のようなステップで進められます(※カッコ内は、各ステップで使用するメインのツール)。
- データの準備(Workbench)
- モデルの開発と、学習履歴の管理(Workbench + Experimentation Service)
- さまざまな環境への学習済みモデルのデプロイ(Model Management Service)
実際の機械学習のワークフローでWorkbenchがどのように使えるのか、大手EMS(電子機器受託製造サービス)ベンダーであるJabil(ジェイビル)のデータを使ったデモを見ながら、より具体的に見ていきましょう。
前提として、JabilはEMSですから、さまざまな企業から電子機器の生産を請け負い、完成品を納品するのがビジネスです。そういうわけで、製造品質はJabilのビジネスにとって非常に重要です。品質をより高めるために、「製造工程で出てくるさまざまな欠品・欠陥を、画像認識技術によってできるだけ完ぺきに検出したい」というニーズがありました。そこで過去の「合格」/「欠陥」データを使った機械学習を推し進めて、図3にあるように、電子回路基板の配線が正常かを画像認識で判断する仕組みを開発しています。

このデモを理解するために、まずはこの電気回路がどういうものかのイメージをつかんでいただきましょう。
図3を見ると、回路基板には3つの基点があるのが分かります。その3つ全ての上に回路がマウントされて、それぞれがきちんとくっついている状態であれば、それはちゃんと電気が通るはずです。このような場合は、図3に示す緑色の「合格」データになります。逆に、正常にマウントされていなければ、電気が通らないはずです。このような場合は、図4に示す赤色の「欠陥」データになります。

では、このようなデータを機械学習させて、デモにマッチする学習済みモデルを作成していきます。Workbenchをどのように使うかを、前述のステップごとに見ていきましょう。
1. データの準備 ― Workbenchでデータを簡単に整理する ―
最初のステップでWorkbenchを使って何をやるのかと言うと、「データの整理」です。現場で使う実データは、複数の人の手によって作成されたりしているので、人によって命名規則がバラバラだったりして、データが正規化されていないケースが多々あります。よってデータの整理が必要となるのです。
ちなみに、データサイエンティストは「データの整理」のことをデータラングリング(Data Wrangling)」と言います。ラングリングというのはカウボーイが牛や馬を飼いならす作業を意味します。それほど、データ整理は大変ということです。玉石混交の多数のデータをきちんと整理して、機械学習にインプットできる形にそろえる作業は非常に大変なのです。「機械学習でかかる工数の8割はデータ整理」という説もあるぐらいです。
Workbenchには、データを整理するための便利な機能がそろっています。
まず基本的なところでは、各種データソースをデータ準備エディター上に表形式で一覧表示したり、編集したりできます(図5)。
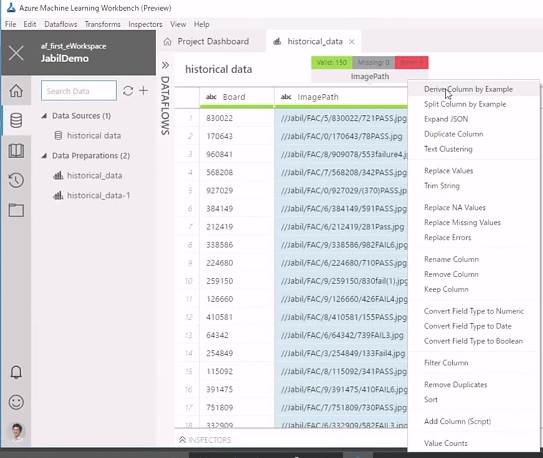 図5 データ準備エディターでは表形式でさまざまなデータ操作が行える
図5 データ準備エディターでは表形式でさまざまなデータ操作が行える また、データのタグ付けをする際に役立つインテリジェントな機能(PROSEと呼ばれている)も提供しています。具体的にはタグのパターンを自動認識してくれ、大量のデータに対して素早くタグ付けが行えるようになっています。例えば次の図6は、もともと全セルがnullになっていた右端列の各セルにpassやfailureというテキストを入力しているところです。このような形で3つほど入力すると、表内のデータパターンから、どの行がpassでfailureなのかを自動的に認識し、全行のセルを自動的に正しく埋めてくれます。これにより作業の手間が大幅に軽減できます。
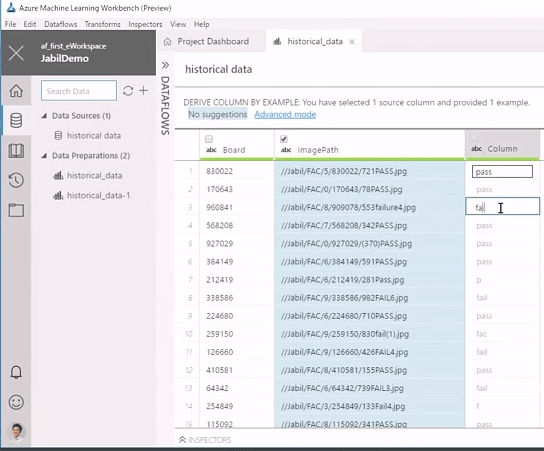 図6 PROSE機能によるデータパターンからのセル値の自動埋め
図6 PROSE機能によるデータパターンからのセル値の自動埋め 2. モデルの開発と、学習履歴の管理 ― Workbenchで学習履歴を管理する ―
上記のようにしてデータの整理が終わったら、次にモデルの開発を行います。
モデルの開発
Workbenchには、Pythonを使っているデータサイエンティストにはおなじみのJupyter Notebookが取り込まれており、Workbench内から直接利用できます(図7)。Jupyter Notebookを使えば、コードの入力と実行 ⇒ 結果の確認を1つずつインタラクティブに進めていくことができるので、より容易に機械学習モデルを開発できます。
![図7 Workbench内からJupyter Notebookを直接利用しているところ(各行のセルにPythonコードを入力=[In]すると、その下に結果が出力=[Out]される)](https://image.itmedia.co.jp/l/im/ait/articles/1711/16/l_di-07.gif)
Jupyter Notebookだけでなく、Visual Studio CodeやPyCharmといった使い慣れたコードエディターを使うことも可能です。つまりWorkbenchでは、コードファーストでPythonやR言語のコードをゴリゴリと書いて、機械学習のモデルを開発していくことができるわけです。
さらに、以下のようなディープラーニング関連フレームワークをサポートしており、必要に応じてそれぞれのエコシステムや資産を活用することもできます。
- TensorFlow
- Keras
- Chainer
- Cognitive Toolkit
- Caffe2
- Theano
- MxNet
- Torch
- scikit-learn
- Spark ML
学習履歴の管理
モデルの開発が終わったら、いよいよモデルに学習(トレーニング)させて結果を評価します。
Workbenchでは、機械学習した際のログをAzure上のロガーに送って、実行履歴データとして保管します。これによって、学習の回ごとにどういうデータだったかを調べたり、複数回の実行を通じてキャプチャされた統計情報を確認したりできます。結果は、次の図8のようにWorkbench上でグラフや一覧形式で分かりやすく表示されます。

このようにWorkbenchを使えば、複数の学習イテレーションを回しながら、後から一番精度の高かった最良の学習結果を手軽に探し、それを学習済みモデル*2として採用できます。
*2 学習済みモデルは、例えばPythonオブジェクトのシリアル化パッケージであるpickle(.pkl)ファイルなどの形式で出力して使用できる。
3. さまざまな環境への学習済みモデルのデプロイ
使用する学習済みモデルを決めたら、それを動かしたい場所にデプロイします。
Workbench(厳密にはAzure Machine Learningサービス)では、基本的に学習済みのモデルをDockerコンテナーにパックしてデプロイします。コマンドラインインターフェースなどを通じて、学習済みモデルを乗せたDockerコンテナーを、AWS/GCP/Azureなどのクラウドだけでなく、オンプレスミスや、Raspberry PiなどのIoTエッジデバイスと、あらゆる場所に配置できます(図9)。作業環境であるWorkbench自体はAzure+Windows/macOSに依存していますが、AIとなる学習済みモデルはどこにでも自由にデプロイできるというのが、Workbenchの特長です。

以上がWorkbenchを使った機械学習のライフサイクルとなります。まずはぜひWorkbench(執筆時点でプレビュー版)をダウンロードしてインストールしてみてください。
基調講演の動画がすでに公開されているので、本稿の内容についてより詳しくは以下も参照してほしい。マイクロソフトのAIプラットフォームに関する公式情報は「azure.com/ai」にある。
※お知らせ: 11月17日より、オンライン上でもMicrosoft Tech Summit 2017が開催される予定だ。本稿をここまで読んでWorkbenchが気になった方は、前述した「MAI003: 新生 Azure Machine Learning services 徹底解説」(日本マイクロソフト株式会社 藤本 浩介 氏)のセッションを一通りご試聴されることをお勧めする。
【動画】デジタルフォーメーションを加速するためのマイクロソフトの最新テクノロジ(平野氏) from 「【Microsoft Tech Summit 2017】 KEY001 変化のとき、進化のとき ITイノベーションがもたらす価値 - YouTube」(1分8秒)
【動画】マイクロソフトが加速させてきているAIに対する投資(平野氏) from 「【Microsoft Tech Summit 2017】 KEY001 変化のとき、進化のとき ITイノベーションがもたらす価値 - YouTube」(2分43秒)
【動画】Azure Machine Learning Workbenchとは?(榊原氏) from 「【Microsoft Tech Summit 2017】 KEY001 変化のとき、進化のとき ITイノベーションがもたらす価値 - YouTube」(11分7秒)
Copyright© Digital Advantage Corp. All Rights Reserved.




![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。