[Python入門]文字列の基本:Python入門(1/2 ページ)
シングルクオート/ダブルクオート/トリプルクオート/raw文字列/f文字列/文字列と数値の変換など、Pythonで「文字列」を扱うための基本事項を紹介。
* 本稿は2019年4月16日、2022年5月11日に公開/改訂された記事を、Python 3.11.5で動作確認したものです(確認日:2023年9月11日)。
前回は、Pythonの変数について見た。今回からはPythonの文字列について、3回に分けて見ていこう。
今回はPythonの文字列の基本をまとめる。次回は、文字列の要素の取り出しや、文字列の変更など、文字列を操作する方法を見る。次々回は、Pythonの文字列で書式指定と呼ばれる操作について見ていく。
文字列とは
第2回の「一番簡単なHello Worldプログラム」でも見たが、「文字列」とは「文字が連なったもの」のことだ。ただし、「0文字の文字列」や「1文字だけの文字列」(文字が連なっていない文字列)も存在する。特に前者のことを「空文字列」(「から」文字列)などと呼ぶ。整数値がint型のオブジェクト、浮動小数点値がfloat型のオブジェクトであったのと同じように、Pythonでは文字列は「str」型のオブジェクトである。

コンピュータは基本的に数値しか扱えない。そこで、コンピュータで文字を扱うために、文字には1つ1つ番号が割り当て、「このデータは文字だよ」という部分にはそれらの番号が格納される。例えば、「A」という文字には多くの場合「65」という番号が割り当てられている。そこで、「これを文字(列)として表示して」とPythonのprint関数に「65」を渡すと、Pythonは「65」を文字「A」と解釈し、その結果「A」が表示される。この「文字(列)として」というのを表すために、Pythonではシングルクオート(あるいはダブルクオート)で文字列を囲むようになっている。
シングルクオートやダブルクオートで囲まれた文字列の中身は、その文字列を構成する文字に割り当てられた番号の連なりとなっている。どれだけの文字を扱えるか、個々の文字をどのような形式(番号そのものやその番号の表記方法)で指定するかを定めたものを「文字コード」などと呼ぶ。代表的な文字コードとしては、いわゆる半角文字として表現されるアルファベットや記号類を集めたASCII、アルファベットや漢字など多数の文字を統一的に扱えるUnicodeなどがある(詳細については本連載では取り上げない)。Python 3では文字コードとしてUnicodeがデフォルトで使われ、個々の文字に振られた番号のことを「コードポイント」と呼んでいる。
例えば、Unicodeでは文字「H」のコードポイントは「72」、「e」は「101」、「l」は「108」、「o」は「111」となっている。よって、上の画像の文字列'Hello'は今述べたコードポイントが連続して並んだものとなる。
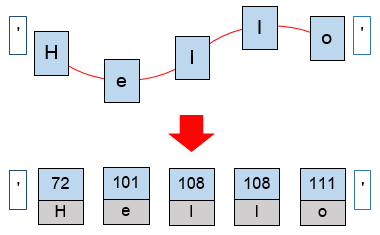 文字には番号(コードポイント)が振られていて、それらの数値が並んだものが文字列となる
文字には番号(コードポイント)が振られていて、それらの数値が並んだものが文字列となるここで、第2回の「一番簡単なHello Worldプログラム」でも見たHello Worldプログラムを見ておこう。print関数に渡している「'Hello World'」というのが文字列(文字列リテラル)だった。
print('Hello World')
既に分かっているだろうが、実行結果も示しておこう。

シングルクオートとダブルクオートによる文字列の記述
今見たように、Pythonでは文字列はシングルクオート「'」で囲んで示すが、冒頭の図に示したようにダブルクオート「"」を使ってもよい。この他にも「トリプルクオート」と呼ばれる文字列記述の方式もあるが、これについては後述する。
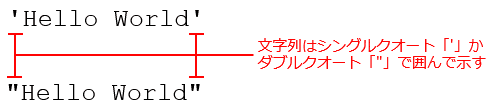 文字列はシングルクオート「'」またはダブルクオート「"」で囲んで表現する
文字列はシングルクオート「'」またはダブルクオート「"」で囲んで表現するどうして、2種類の記号が使えるかというと、「'」を含んだ文字列や、その反対に「"」を含んだ文字列を表現するのに、2種類の記号を使えると便利だからだ。例えば、以下のように「It's easy to learn Python」と画面に表示したいとしよう。このときには、文字列を「"」記号で囲めばよい。
print("It's easy to learn Python")
逆に、ダブルクオートで強調したい部分を含んだ文字列であれば、シングルクオートを使うと簡単に文字列を表現できる。以下に例を示す。

シングルクオートで囲んで表記する文字列内にシングルクオートを(あるいは、ダブルクオートで囲んで表記する文字列内にダブルクオートを)含めるには「エスケープシーケンス」と呼ばれる表記方法も使える。
エスケープシーケンス
「エスケープシーケンス」とは、通常の記述方法では表せない文字を2文字以上の文字を組み合わせて表現する方法のことだ。例えば、「シングルクオートで囲んだ文字列内でシングルクオートを表現」する方法を考えてみよう。ここでは「it's」を例に取る。単に「'it's'」と書くと、2つ目の「'」で文字列が終了し、Pythonは残る「s'」を正しく解釈できない(もちろん、上で見たようにダブルクオートで囲めばよいが)。以下の画像でも、Pythonが「s'」を指して、「文字列リテラルが終わっていない」(unterminated string literal)と指摘している(Pythonのバージョンによっては「文法に違反している」(invalid syntax)と表示されるかもしれない)。

この場合、2つ目の「'」が「通常の記述方法では表せない文字」となる。このような事態を回避して、特定の文字を表現するための文字の並びのことを「エスケープシーケンス」と呼ぶ。一般的には、エスケープシーケンスはバックスラッシュ「\」(Windowsでは円記号)で始まり、その後に1文字以上の文字を続ける。シングルクオートをエスケープシーケンスで表現すると「\'」となる。同様にダブルクオートをエスケープシーケンスで表現すると「\"」となる。

今見たような引用符(シングルクオート、ダブルクオート)だけではなく、通常の文字列に含めるのが難しい文字を表現するのにもエスケープシーケンスは使われる。その代表的なものが「改行」だ。複数行のメッセージをPythonのprint関数で表示したいとしよう。最初にダメな例を示す。
print('1行目
2行目')
これをセルに入力して実行すると、次のようになる。

御覧の通り、エラーとなる(エラーメッセージの内容はおおよそ「文字列が終わっていない」となる。Pythonのバージョンによっては「EOL while scanning string literal」=「文字列リテラル内を読んでいる途中でEOLが発生した」と表示される)。つまり、シングルクオートやダブルクオートで囲んだ文字列内では改行を含めることができないということだ。このような場合には改行を意味するエスケープシーケンス「\n」が使える。
print('1行目\n2行目')
文字列内で改行をする必要はなく、その位置に「\n」と書くだけでよい。これをセルに入力して、実行すると次のようになる。

今度は改行を含んだメッセージが表示された。このようなエスケープシーケンスとして認識される代表的な文字の並びを以下に示す。
| エスケープシーケンス | 説明 |
|---|---|
| \' | シングルクオート |
| \" | ダブルクオート |
| \n | 改行 |
| \t | タブ文字 |
| \\ | バックスラッシュ(円マーク) |
| \ooo | 8進数値「xxx」を文字コードとして持つ文字 |
| \xhh | 16進数値「hh」を文字コードとして持つ文字 |
| 代表的なエスケープシーケンス | |
最初に示した3つは既に見た通りだ。「\t」は「タブ文字」と呼ばれ、「8文字ごと」「4文字ごと」などに設定されたタブ位置まで表示位置を移動させるもの。そして、「\\」は「\」という文字そのものを表すためのエスケープシーケンスだ。
最後の2つは、8進数値「ooo」または16進数値「hh」を文字コードとして持つ文字を表す。8進数値の場合「ooo」には「0」〜「7」の数字を、16進数値の場合「hh」には「0」〜「9」「A」(10)〜「F」(15)の各文字を記述する。例えば、「a」という文字をこれら2つのエスケープシーケンスで表示してみよう。
文字「a」のコードポイントは、Pythonのord関数で調べられる。また、そのコードポイントを8進数値にするにはoct関数を、16進数値にするにはhex関数が使える。そこで、次のコードをセルに入力してみよう。
code_point = ord('a')
oct_code = oct(code_point)
hex_code = hex(code_point)
print(oct_code)
print(hex_code)
実行結果を以下に示す。

これで、文字「a」に(この環境において)割り当てられている文字コードの8進数表記と16進数表記が分かった。では、これらを利用して、文字「a」を表示してみよう。
print('\141')
print('\x61')
8進数表記を用いるときには「\」にそのまま8進数値を書き、16進数表記では「\x」に続けて16進数値を書くことに注意しよう。実行結果を以下に示す。

なお、ord関数は「引数に渡した文字のコードポイントを得る」ものだったが、逆に「引数に渡したコードポイントに対応する文字を得る」関数もある。それがchr関数だ。使用例を以下に示す。興味のある方は実行してみよう。
code_point = ord('a')
a_char = chr(code_point)
print(a_char)
Copyright© Digital Advantage Corp. All Rights Reserved.




![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。