「Gensim」による機械学習を使った自然言語分析の基本――「NLTK」「潜在的ディリクレ配分法(LDA)」「Word2vec」とは:Pythonで始める機械学習入門(9)(2/2 ページ)
LDAによるトピックモデルの計算
LDAとは
LDAとは、「トピックモデル」と呼ばれる手法の一種です。トピックモデルとは、文書のトピック(主題)を推定するモデルで、文書の分類や検索などに利用される手法です。LDAでは、各文書について「どのトピックに属するか」ということを「確率分布」で予測します。
例えば、あるニュースサイトで、それぞれの記事が「政治」「経済」「スポーツ」という3つのトピックの要素を持つとしましょう。そのとき、各文書が、その3つのうちどれであるかをずばりと当てるのではなく、それらの重み付けによって表そうというのがLDAです。特に合計が「1」になるように正規化すると、それらの3つのトピックについての確率分布だと思うことができます。
下図は計算結果の例です。例えば文書1はスポーツの要素が強いが政治、経済の要素も少し含むというような計算結果を得ることになります。

LDAでは、ここでいう「政治」「経済」「スポーツ」などのような具体的なトピックを指定するわけではなく、外側からはトピックの数だけを指定します。すると、自動的に「どのようなトピックがあるか」を学習し、各文書のトピック分布を計算できるようになります。
LDAを使って学習させる
それではLDAを使って学習させてみます。
ここで1行目の「dictionary[0]」は関数「dictionary.id2token」が使えるようにするための手順で、おまじないのようなものだと思ってください。2行目で、モデルを作って学習させています。引数「num_topics」はトピックの数です。引数「id2word」は、数値と単語の変換関数を与えています。後で可視化するときに必要になります。「random_state」は乱数の種であり、複数回実行したときの結果の再現性を高めるためのものです。
ここでトピックの構成を見てみます。

各トピックについて、単語とそのウエートが、ウエートが高い順に表示されています。例えば0番のトピックは「bank」や「mln」(「million」の略)などのウエートが高く、銀行関連のトピックだと見ることができます。3番のトピックは「company」「dlrs」(「dollars」の略)、「share」などのウエートが高く、企業の株価に関するトピックだと見ることができます。
トピックを推定する
次に、各文書についてのトピックを推定します。ここでは学習のときに使ったデータと同じデータについて推定させてみます。

1行目で予測値を計算しています。結果の値を合計が1になるように正規化しているのが2行目です。
次に最初の5文書について、そのトピック分布を棒グラフで可視化してみます。

ここでインデクス0番(最初)の文書で一番強く出ているトピックを確認してみます。

13番のトピックを上記のトピック構成単語の一覧から探してみると、「trade」「agreement」などのウエートが高いことが分かります。これは国際的な貿易協定に関わるものかと類推されます。その文書を見てみます(長くなる尾で最初の300文字だけ表示します)。

これは日米の貿易摩擦に関するニュースでした。LDAによる判定はそれなりに妥当であることが分かります。
Word2vecによる単語埋め込み
Quoraデータセットのダウンロードと前準備
ここではQuoraデータセットを使います。
まずは、データ「quora_duplicate_questions.tsv」をダウンロードしてディレクトリ「data」に入れてください。このデータはtsv(タブ分割テキスト)形式になっていますが、その中でも特に「question1」というカラムだけを利用します。英語の質問文を約40万個集めたものです。データを読み込んで、単語に分解し、最初の10文だけ中身を表示してみます。

次に、ストップワードの除去を行い、同じように最初の10文の情報を表示してみます。

ここでWord2vecが計算します。
「Word2vec」とは
Word2vecは、指定された次元の空間に単語を埋め込むためのアルゴリズムであり、空間内における単語の距離の近さが単語の意味の近さになります。注目している単語とその前後周辺に出てくる単語の関連を学習していく仕組みになっています。
Word2vecを使って学習させる
まずは、学習させます。ここでは、LDAのときと違って、corpus形式のデータを用意せず、単語のリストのリストを与えるだけで十分です。
ここで指定している「size」は埋め込む空間の次元で、「window」は幾つの単語のつながりをまとめてみるかという数です。
Word2vecを使った推定
では、学習済みモデル対して、「sick」という単語と「actor」という単語に近い単語を見てみます。
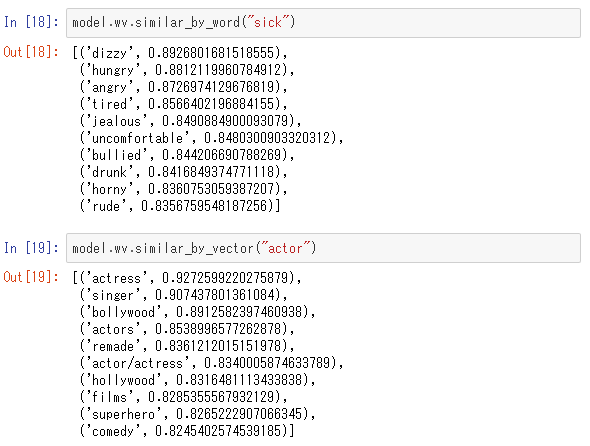
それぞれ近い順に上から順に単語が並んでいます。それなりに妥当な結果になったことが確認できるかと思います。
まとめ
Gensimの典型的な使い方として、LDAとWord2vecの実行例を示しました。これらを使って、扱っているトピックが近い文書や、意味の近い単語を識別することは、例えば文書検索のような技術に応用できます。
ここでは英語データの処理の例を示しましたが、日本語の場合も単語への分割ができれば同じように実行できます。ただし日本語文の場合、英文と異なりスペースにより単語が分割されていないので、単語分割するためには「形態素解析器」という特別なツールを使うことになります。よく使われる有名な形態素解析機には「MeCab」「Juman」「Sudachi」などがあります。
連載の終わりに
本連載は今回で終了です。本連載では、機械学習で使われるさまざまなライブラリを広く浅く扱ってきました。ここで紹介したライブラリの選択については、筆者の経験によるもので、他にも便利で有用なものがたくさんあると思います。とはいえ、機械学習の初心者が触ってみて広い分野をそれなりに理解できるようなラインアップをそろえたつもりではあります。深く理解するには、さらに解説書や公式ドキュメントを読む必要がありますが、本連載がPythonの機械学習ライブラリ群を概観するの役立てればと思っています。
関連記事
 Intel、Xeon上での「TensorFlow」使用時向けにDNNモデルコンパイラ「nGraph」の性能を強化
Intel、Xeon上での「TensorFlow」使用時向けにDNNモデルコンパイラ「nGraph」の性能を強化
Intelは、「Intel Xeonスケーラブルプロセッサー」上で「TensorFlow」を使用するデータサイエンティスト向けに、フレームワーク非依存のディープニューラルネットワークモデルコンパイラ「nGraph Compiler」のパフォーマンスを高めるブリッジコードを提供開始した。 NVIDIAとGoogle、「TensorRT」と「TensorFlow 1.7」を統合
NVIDIAとGoogle、「TensorRT」と「TensorFlow 1.7」を統合
「NVIDIA TensorRT」とオープンソースソフトウェアの機械学習ライブラリの最新版「TensorFlow 1.7」が統合され、ディープラーニングの推論アプリケーションがGPUで実行しやすくなった。 ITエンジニアがデータサイエンティストを目指すには?
ITエンジニアがデータサイエンティストを目指すには?
それぞれの専門分野を生かした「データサイエンスチーム」を結成すればデータ活用への道は短縮できる。そのとき、ITエンジニアはどんな知識があればいい? データサイエンティストとして活動する筆者が必須スキル「だけ」に絞って伝授します。
Copyright © ITmedia, Inc. All Rights Reserved.




![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。