[Python入門]Pythonの演算子まとめ:Python入門(1/2 ページ)
代入演算子/算術演算子/比較演算子/ブール演算子など、Pythonで各種の演算を行うための記号類をまとめる。
* 本稿は2019年7月23日、2022年7月15日に公開/改訂された記事を、Python 3.12.0で動作確認したものです(確認日:2023年11月10日)。
前回は、Pythonのオブジェクトの同一性と、比較の方法、それからオブジェクトの文字列表現について見た。今回は、本連載でこれまでに取り上げたものも含めて、Pythonの演算子をざっくりとまとめていく。
演算子の種類
本連載ではこれまでに幾つもの演算子を使ってきた。まずは、それらの種類について大まかにまとめておこう。以下の表で「単項」と書いてある演算子(単項+、単項-、単項~)と三項演算子以外は全て二項演算子である。
| 種類 | 説明 | 演算子 |
|---|---|---|
| 代入演算子 | 代入を行う | = |
| 累算代入演算子 | 左辺と右辺の値を演算して得られる結果を左辺に代入する | +=、-=、*=、/=、//=、%=、>>=、<<=、&=、^=、|=、単項+、単項- |
| 算術演算子 | 加減乗除などを行う演算子 | +、-、*、/、//、%、** |
| 比較演算子 | 値が等しいかやそれらの大小を比較したり、複数要素を格納するオブジェクトに対して、要素の存在確認をしたりする演算子 | ==、!=、>、>=、<、<=、is、is not、in、not in |
| ブール演算子 | 真偽値のブール演算を行う | or、and、単項not |
| ビット演算子 | ビット演算(数値の2進数表現のビットごとの演算)を行う演算子 | &、^、|、単項~ |
| シフト演算子 | ビットシフト(数値の2進数表現を左右にずらす)を行う演算子 | <<、>> |
| 三項演算子 | ある条件が成否に応じて演算結果を決定する演算子(if文とは異なり、これは演算子なので、式中にそのまま記述できる)。条件式とも呼ぶ | x if 条件 else y (条件が真ならx、偽ならy) |
| 代入式(セイウチ演算子) | Python 3.8で追加された、式しか記述できない場所で変数に何らかの値を代入できるようにする仕組み。「:=」がセイウチの目(:)と牙(=)のように見えることからセイウチ演算子などと呼ばれることもある | := |
| 演算子の種類 | ||
以下では、これまでに見てきたものも含めて、上記の演算子について簡単にまとめていこう。
代入演算子/累算代入演算子
前々回も述べたが、変数への値の代入は、その変数の「名前」と代入される「オブジェクト」とを「束縛」することだ。Pythonではこの処理は「代入文」として規定されており、「代入先 = 式」のように表現される。ここで使われている「=」をここでは代入演算子と呼ぶ。
代入演算子「=」の右側に書かれた式(右辺)の値が計算された後に、代入演算子の左側に書かれた代入先(左辺、代入先、代入の「ターゲット」)と、その値が束縛される。このとき、左辺にはカンマ「,」で区切ってターゲットを複数置くこともできる。その場合には、右辺には左辺のターゲットに代入するのに必要なだけの式をカンマ「,」で区切って並べる必要がある。
以下に例を示す(実行結果は省略)。
x = 1 # 単純な代入
y = 'py' * 2 # 右辺の式「'py' * 2」を計算した結果である「'pypy'」が代入される
a, b = 2, 3 # 複数のターゲットへの代入
c, d, e, *f = [3, 4, 5] # 変数fの値はどうなる?
この例で説明が必要なのは、最後の「c, d, e, *f = [3, 4, 5]」くらいだろう。Pythonのドキュメント「代入文」には「"星付き"のターゲットと呼ばれる、頭にアスタリスクが一つ付いたターゲットがターゲットリストに一つだけ含まれている場合: オブジェクトはイテラブルで、少なくともターゲットリストのターゲットの数よりも一つ少ない要素を持たなければなりません」とある。この説明に合わせた例がこのコードだ。
左辺のターゲット(複数のターゲットをまとめて「ターゲットリスト」と呼ぶ)は4つある。そして、最後の変数fの前にはアスタリスク「*」が付加されている。一方、左辺は反復可能オブジェクトであり、そこには3つの要素が含まれている。このとき、変数c、d、eには3つの要素が1つずつ代入されていく。残った変数fには「空のリスト」が代入される。これは関数の「可変長位置引数」と似た動作だと考えればよいだろう。なお、変数fが「星付き」でない場合には、左辺のターゲットの数と、右辺の式が返す値の数は同じでなければならない(例えば、3つの値をタプルとして返す関数を呼び出した場合、それを受け取る側は1つの変数で1つのタプルを受け取るか、3つの変数でタプルの各要素を受け取るようにする)。
今見たように、代入演算子「=」は右辺の値を左辺のターゲットと束縛する。一方、累算代入演算子はその左辺に置かれたターゲットの値を得た上で、その値と右辺に置かれた式の値を計算したものを使用して、その累算代入演算子に関連付けられている演算(加算など)を行い、その結果を左辺に置かれた変数に代入するという処理を行う。なお、累算代入についてもPythonでは「累算代入文」として規定され、その構文要素として以下の演算子が定められている。
累算代入演算子には次のものがある(一部)。
| 演算子 | 演算 | 例 |
|---|---|---|
| +=、-=、*=、/=、//=、%=、**= | 加減乗除および整数除算、剰余演算、累乗演算を行った結果を代入する | a *= 2→変数aの値を2倍したものを変数aに代入する |
| >>=、<<= | 左辺の値を、右辺の値で与えられたビット数だけ右シフトあるいは左シフトした値を代入する。左辺の値は整数である必要がある | a <<= 2→変数aの値を2ビットだけ左にシフトした値を変数aに代入する(変数aの4倍を計算するのと同じ) |
| 累算代入演算子(一部抜粋) | ||
以下に例を示す(実行結果は省略)。
a = 100
a /= 10 # 「100 / 10」=「10.0」が代入される
mylist = [1, 2]
print(id(mylist))
mylist += [1, 2] # 「[1, 2] + [1, 2]」=「[1, 2, 1, 2]」が代入される
print(id(mylist))
mylist = mylist + [1, 2] # 上と同じことだが
print(id(mylist)) # mylistのアイデンティティーが変わる
累算代入演算子は、その演算子が表す演算と代入を一度に行う。例えば「a += 1」なら「a = a + 1」と同じ結果が得られる。ただし、両者が完全に同じとは限らない。Pythonのドキュメント「累算代入文」には「可能ならば インプレース (in-place) 演算が実行されます」とある。これは、元のターゲット(変数など)がリストのように「変更可能」なオブジェクトを参照していたときには、元のオブジェクトを変更して、新たな値とするということだ。
例えば、上のコード例の「mylist += [1, 2]」では、累算代入演算子「+=」により、変数mylistが参照しているリストそのものが変更されて「[1, 2, 1, 2]」という値になる。そのため、前後にある「print(id(mylist))」ではオブジェクトのアイデンティティーが変化しない。これに対して、「mylist = mylist + [1, 2]」では加算演算子「+」によってリストの「結合」が行われ、新しいリストオブジェクトが作成された後に、それが変数mylistに代入される。そのため、それまでとはオブジェクトのアイデンティティーが異なるものになる。
なお、文字列や数値など、変更不可能なオブジェクトを対象とした場合には、常に新しいオブジェクトが作成される。
算術演算子
算術演算子は、基本的には数値同士の演算を行う。ただし、「+」「*」「%」は数値以外の値を被演算子として取ることもある。
以下の表に算術演算子とその使用例を示す。
| 演算子 | 説明 | 例 |
|---|---|---|
| + | 加算 | 1 + 1.0→2.0(整数と浮動小数点数の和を求める。結果は浮動小数点数となる) 'py' + 'thon'→'python'(2つの文字列を結合して新しい文字列を作成する) |
| - | 減算 | 1 - 1→0(整数同士の減算を行う。結果は整数となる) 1.0 - 1→0.0(浮動小数点数から整数を引く。結果は浮動小数点数となる) |
| * | 乗算 | 5 * 3.5→17.5(整数と浮動小数点数の乗算。結果は浮動小数点数となる) 'py' * 2→'pypy'(文字列の乗算。数値でない方の値を、もう一方の数だけ繰り返す。結果は文字列となる) 2 * [1, 2]→[1, 2, 1, 2](リストの乗算。文字列の乗算と同様) |
| / | 除算 | 1 / 5→0.2(整数同士の除算。結果は浮動小数点数となる) 1.0 / 5.0→0.2(浮動小数点数同士の除算。結果は浮動小数点数となる) |
| // | 整数除算(切り捨て除算) | 5 // 2→2(「5÷2」の商が求まる。結果は整数となる) 1.7 // 0.6→2.0(「1.7÷0.6」の商が求まる。「1.7=0.6×2.0+0.5」なので、その商である「2.0」が得られる。結果は浮動小数点数となる) 3.14 // 3→1.0(浮動小数点数と整数の切り捨て除算。結果は浮動小数点数となる) |
| % | 剰余または文字列の書式指定 | 5 % 2 →1(「5÷2」の剰余、余りが求まる。結果は整数となる) 1.7 % 0.6→0.5(浮動小数点数の剰余が求まる。結果は浮動小数点数となる) 1.7 % 1→0.7(浮動小数点数と整数との剰余演算。結果は浮動小数点数となる) 文字列の書式指定については第7回「文字列の書式指定」の「%演算子を使った文字列の書式指定」を参照 |
| ** | べき乗(累乗) | 2 ** 5→32 -1 ** 2→-1 2 ** -1→0.5(後述) |
| 単項+ | 被演算子の符号をそのままとする | +(-1)→-1 |
| 単項- | 被演算子の符号を反転する | -(-1)→1 |
| 算術演算子 | ||
加算演算子「+」と乗算演算子「*」、それから剰余演算子「%」については数値以外の値を被演算子に取る場合がある。それらの場合の演算結果についてまとめておこう。
- +:数値以外の値を被演算子とするときには、それらは同じ型のシーケンス(リストやタプルなど)である必要がある。演算結果はそれらのシーケンスを結合した新しいオブジェクトになる
- *:被演算子の一方は整数で、もう一方はシーケンスである必要がある。演算結果はシーケンスを、もう一方の値だけ繰り返したものになる
- %:被演算子はその左側に旧式の書式指定を含んだ文字列を、右側に埋め込む値をまとめたタプルや辞書を指定する。詳しくは第7回「文字列の書式指定」の「%演算子を使った文字列の書式指定」を参照のこと
数値同士の算術演算では、整数と浮動小数点数を対象とするときには、整数は同じ値の浮動小数点数に変換された後に、演算が行われる。そのため、演算結果は浮動小数点数になる。また、整数同士の算術演算では「/」による除算を除けばその結果は整数となる。
これらの演算子には優先順位があり、多くの場合、一般的な数式と同じような演算結果となる。例えば、「1 + 2 * 3」であれば、「1+2×3」と同様に、最初に乗算が行われ、次に加算が行われる。優先順位を変えるのであればかっこ「()」を使用する。先の式を「(1 + 2) * 3」とすれば加算が優先して行われる。
ただし、べき乗演算子「**」については注意が必要だ。これは高い優先順位を持っていて、左側の被演算子に符号を反転する単項演算子「-」があっても、それよりも優先される。そのため、上の表に示したように「-1 ** 2」は予想とは異なり「-12」=「1」ではなく、「-1」が演算結果となる。が、右側の被演算子に付加された単項演算子「-」よりは後に演算が行われる。そのため、「2 ** -1」は「2-1」と同じく「0.5」が得られる。
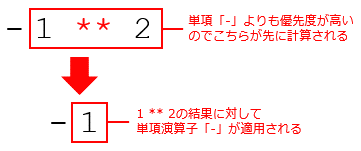 べき乗演算子「**」の動作
べき乗演算子「**」の動作最後に単項演算子「+」「-」についても述べておこう。単項演算子「+」は実質的には何もしない。被演算子の符号をそのままとするだけだ。対して、単項演算子「-」は被演算子の符号を反転する。これは被演算子の絶対値はそのままに、被演算子が正の値なら負の値に、負の値なら正の値とする。
比較演算子
比較演算子はその名の通り、オブジェクトの比較を行うものだ。その結果は真偽値、つまりTrueかFalseとなり、比較の条件が成り立ったか、成り立たなかったかを示す。以下の表に比較演算子とその使用例を示す。
| 演算子 | 説明 | 例 |
|---|---|---|
| == | 2つのオブジェクトの値が等しいかどうかを調べる | 1 == 0→False [1, 2] = [1, 2]→True |
| != | 2つのオブジェクトの値が等しくないかどうかを調べる | 1 != 0→True [1, 2] != [1, 2]→False |
| < | 左側の被演算子が右側の被演算子より大きいかどうかを調べる | 1 < 0→True 'abcd' < 'abc'→True |
| <= | 左側の被演算子が右側の被演算子以上かどうかを調べる | 0 <= 0→True [1, 2] <= [1, 2, 3]→False |
| < | 左側の被演算子が右側の被演算子よりも小さいかどうかを調べる | 0 < 1→True 'abcd' < 'abc'→False |
| <= | 左側の演算子が右側の被演算子以下かどうかを調べる | 0 <= 0→True [1, 2, 3] <= [1, 2]→False |
| is | 2つのオブジェクトが同一のオブジェクトかどうかを調べる | True is True→True |
| is not | 2つのオブジェクトが同一のオブジェクトでないかどうかを調べる | True is not False→True |
| in | 左側の被演算子が右側の被演算子に含まれているかどうかを調べる | 'yt' in 'Python'→True 'hoge' in ['foo', 'bar', 'baz']→False |
| not in | 左側の被演算子が右側の被演算子に含まれていないかどうかを調べる | 'py' not in 'Python'→True 'foo' not in ['foo', 'bar', 'baz']→False |
| 比較演算子 | ||
前回の「オブジェクトの比較」でも述べたが、「==」と「!=」の2つの演算子は「オブジェクトと等価性」つまり「2つのオブジェクトの値が等しいかどうか」(または等しくないかどうか)を調べる。一方、「is」「is not」の2つの演算子は「オブジェクトの同一性」つまり「2つのオブジェクトのアイデンティティーが等しいかどうか」(または等しくないかどうか)を調べる。
「==」「!=」「>」「>=」「<」「<=」による比較は、数値を対象とするときには、直感的な結果となる。だが、リストなどを比較する際には次のようにして大小が判定される。
- 型の異なるオブジェクトは等しくないと判断される
- 2つのオブジェクトが同じ型で、同じ要素数、対応する要素(インデックスやキーが同じ要素)の値が等しい場合には等しいと判断される
- リストなどでは、先頭から要素を比較していき、対応する要素が異なった時点で、小さい値を持つオブジェクトが小さいと判断される
- リストなどで、先頭から要素を比較していき、あるオブジェクトの全ての要素が他のオブジェクトと等しかったが、他のオブジェクトがさらに要素を持っているときには、最初のオブジェクトの方が小さいと判断される
- 文字列は、Unicodeのコードポイントを基準として辞書式順序で比較が行われる
- 集合は包含関係を基に比較が行われる。上位集合の方が下位集合よりも大きい。包含関係になければ、それらは等しくなく、どちらかの集合がもう一方の集合より大きい(または小さい)ということはない
以下に幾つか例を示す(実行結果は省略)。
mystr1 = 'abc'
mystr2 = 'abcd'
# 'abc'までは同じだが、mystr2には'd'もあるので、mystr2の方が大きい
print(mystr1 < mystr2) # True
mylist1 = [1, 2, 3]
mylist2 = [1, 2, 4]
# インデックス2で、mylist2の要素の値の方が大きい
print(mylist1 < mylist2) # True
mytuple1 = ('foo', 'baar', 'baz')
mytuple2 = ('foo', 'bar', 'baz')
# インデックス1で、'baar'と'bar'では'baar' < 'bar'となる(辞書式順序)
print(mytuple1 > mytuple2) # False
mydict1 = {'foo': 0, 'bar': 1}
mydict2 = {'bar': 1, 'foo': 0}
# 全てのキーと値が等しいので、別オブジェクトだが等価
print(mydict1 == mydict2) # True
myset1 = {1, 2, 3}
myset2 = {4, 5, 6}
# 集合の包含関係を満たさないので、大小比較はどちらもFalseとなる
print(myset1 > myset2)
print(myset2 > myset1)
Copyright© Digital Advantage Corp. All Rights Reserved.




![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。