第232回 Intelの10nmプロセスの不思議、「10nm」はどこにある?:頭脳放談
Intelが10nmプロセスによる量産製造を開始した。一方、AMDはすでにTSMCによる7nmプロセスで製造を行っている。「Intelは遅れているのではないか?」とも言われているが、実際のところはどうなのだろうか? プロセスの数字の秘密を解説する。
「一言で」とか、「1個の数字で」とか、何かを簡潔に説明するのが多くの人の好みに合っているようだ。実際、「分かった」気になる。
「一言で言う」ならば、それを記憶するのは容易だ。1個の数字は他と比較して、「増えた」「減った」「同じ」「達成した」「未達成だった」といった事柄を容易に判断できる。どちらも納得感は半端ない。
逆に数字がごちゃごちゃとたくさんあると、「何だか分からん」ということになる。ただ、1つ指摘しておくならば、世の中、何でもそのように単純化できるものならば、AI(人工知能)など不要だ。いや、それだからこそ、「AIに1個の数字に単純化してもらっている」ともいえる。なぜその数字になるのかは、説明が付かない場合も多いのだが……。
Intelの10nmプロセスは遅れているの?
さて本題は、半導体プロセスに冠する「x nm(ナノメートル)」といった数字「x」である。現状、TSMCで製造されている最新鋭のAMDのZenプロセッサが7nmプロセスといった時のあれだ。筆者も頼っている一人だ。
Intelは、最近10nmプロセスによる本格的な量産をようやく始める(頭脳放談「第231回 Intelの新プロセッサ『第10世代Coreプロセッサ』3つの特徴をざっくり検証」参照)。それで、Intelはまだ10nmプロセスで、「TSMCの7nmプロセスからずいぶんと遅れているじゃないか」「いや実はそうじゃない」といった説明を多く見かける。
思うにこのx nmというような数字は、まさに先に述べたような、1個の数字に語らせる症候群の1つの症例だと思う。数字を聞く側からすれば「分かりやすい」からという一般化もできる。
1個の数字はロードマップのため?
しかし半導体業界には、1個の数字でなければならない独特の背景というべきものが存在する。それははるか半世紀も前、まだ小さかった半導体業界の中にも確実に存在していた。それが現在まで連綿と続いているのだ。
どこの業界にもあるのかもしれないが、こと半導体業界においては製品を計画するにも、販売するにも「ロードマップ」というものが金科玉条のごとくに扱われてきた。「ロードマップ」によれば「x年後の新製品のスペックはこうでなければならない」と。
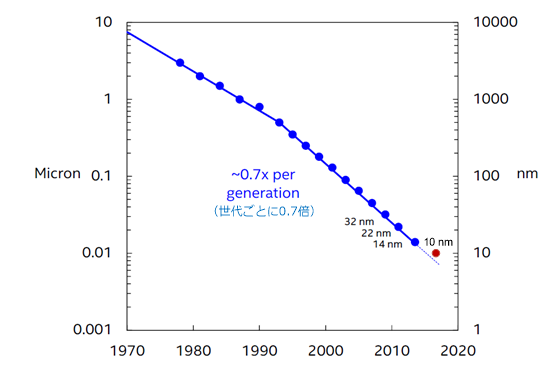
そのロードマップというものは、未来年表やガントチャートのような形式もあるが、それらの背景に必ず片対数グラフが存在している。あるいは、片対数グラフそのものをロードマップと呼ぶこともある。通常、横軸には年の単位の時間をとり、縦軸には注目している指標をとる。そして、グラフは着目指標にもよるが傾きの正負は別にして常に直線である。つまり何かの指標が年単位の時間に対して指数関数で表せることを示している。そして、このグラフの最も有名にして根本的なものが「ムーアの法則」だ。「経験則」といわれているが、それが成り立ってきたのには、物理的、人為的な背景も関係している。
 Intelの製造プロセス
Intelの製造プロセスここで昔話を少し書かせていただく。はるかな昔、筆者が設計者の端くれとして業界に入ったころ、配属先は最小線幅「4μm」の設計ルールで設計作業をしていた。しかし、その設計に基づいて製造された製品は、最先端「2.5μm」の製品であったのだ。別に何もうそをついているわけでもない。
過去の4μmの設計データを持っていたので、それに修正を加える形で設計を行って「設計図」を作りあげていたが、それを使って製造用のマスク(金型に当たるもの)を作る際に、0.64倍していたからなのだ。
単純に「4」に「0.64」を乗算しただけでは、ぴったりと「2.5」にはならない。また途中に何段も処理が入る。「細かいこと(nmで記したらビックリの差だが)」にはブツブツ言わないのだ。
データ上の2.5μmと、それに対応するマスク上の長さと、そこから製造されるポリシリコンゲートの物理的長さと、半導体としてのゲートの実効長とは、みんな違う。それどころか製造バラツキも考えれば変動さえする。そういう細かい話を抜きにして、1つの数字に集約した「2.5μm」プロセスであった。
ただ4μmで設計されたチップを、2.5μmで製造すると面積は約半分になるということを記憶しておいていただきたい。単純計算ではもっと小さくなるはずだが、ボンディング(接合)のためのパッドなど、周辺部分にはそのまま縮小できない部分が存在するので、単純計算ほど小さくならないからだ。
ここで出てきた0.64倍といった数字には意味がある。新たなプロセスは前のプロセスに対して、0.8倍とか、0.8倍を2回かけて0.64倍とかで開発されることが常であったからだ。これは半導体製造装置の新機種を開発するときの性能目標であったはずだし、当然、マスクの製造側、設計関係のソフトウェア開発に至るまで常に意識されていた数字だ。
 Intelの製造プロセスとダイサイズの関係
Intelの製造プロセスとダイサイズの関係製造プロセスが1世代進むと、面積は約半分になっている。14nm以降、さらに面積が小さくなっている(「10 nm TECHNOLOGY LEADERSHIP[PDF]」より)。
これを支えていたものこそ、比例縮小則といわれるMOSトランジスタの原則であった。詳しいことは他に当たっていただくとして、トランジスタの各部分の物理的な寸法を比例縮小すれば(本当は電源電圧もだが、それは難しい)、トランジスタの性能を維持したまま、サイズを縮小(面積は長さの二乗で効く)できるというものである。これは物理的な法則のある局所に対する適用を工学的に表現したものといえるので、人の好き勝手にできるものでもない。
しかし、0.64倍にするための装置や製造プロセスを「関係者の努力」によって、約18カ月ごとに新製品としてリリースできたらどうだろうか。特定の1社1チームの話でなく、業界全体としてである。1社1チームには過ぎたる負荷だが何チームも並行して働いていると考えれば無理な話ではない。そこから片対数グラフが見えてこないだろうか。
そうして、プロセスの集積度に関して片対数グラフ上に一本の直線が引かれたわけである。x年先にはxμm(現在では単位が変わりnmになっている)というロードマップの完成である。
プロセスをこの2次元のグラフ上にプロットし、直線より上にあれば「進んでいる」、直線より下にあれば「遅れている」と判断できるようになったわけだ。後れを取るわけにはいかないから、各社ともこのグラフの直線上にプロットできることを目指した。結果、このグラフはさらに補強され絶対性を増していくことになる。
もはや1つの数字で半導体プロセスは説明できない
今にしてみれば、複雑な半導体プロセスを1個の数字で表すということには無理があったと言わざるを得ない。昔話のころであれば、トランジスタの性能を表すゲート長とポリシリコンゲートの物理的な長さはマスク上の最小線幅と「だいたい」対応できていた。だが、いまや露光のための波長に対してマスク(今ではマスクとは言わないが)パターンが小さくなりすぎて、干渉だか回析だか光学的な計算の極致を尽くして人間には不可解なパターン(どこが最小線幅なのか分からない)となった。
ポリシリコンゲートは昔に戻ってメタルゲートになるなどもしたし、チャネルを取り囲むフィントランジスタにも変化が起きて3次元的な構造が普通になった。3次元的な構造の違いを1個の数字で表すのは理不尽というものだろう。
また、トランジスタのゲート長よりも、配線のメタルピッチ(配線の幅と配線間の隙間1つを足した長さ)の方が実際の集積度を左右するから、そちらをプロセスの集積度にとるべきだ、という考え方もあった。それはそれでリーズナブルなのだが、これまた次元の呪い(本来の意味とはちょっと違うが勘弁)だ。
配線層が例えば1層同士であればメタルピッチで絶対的に密度を比較・判定できる。だが、いまや配線層数は2桁だ。層の数が多ければそれだけ配線密度が上がる。すると、配線層数とメタルピッチの両方を考えなければならないが、メタルピッチは層によってみんな違うのだ。最小線幅層のメタルピッチは技術力の証明にはなるが、集積度を単独で決定できるパラメータではない。
結局、トランジスタのゲート長も、メタルピッチもある時期から別々の片対数グラフにプロットする方が適切、ということになってしまった。いまや集積度は1個の数値パラメータで表せるものでもなく、複雑化した膨大なパラメータの関数だといえる。
| 製造プロセス | 22nm | 14nm | 10nm |
|---|---|---|---|
| フィンの間隔(フィンピッチ) | 60nm | 42nm | 34nm |
| ゲートの間隔(ゲートピッチ) | 90nm | 70nm | 54nm |
| インターコネクトピッチ(メタルピッチ) | 80nm | 52nm | 36nm |
| Intelの製造プロセスと各ピッチのサイズ | |||
しかし、業界の黎明(れいめい)期から存在する「x nm(x μm)対年」というグラフが消えたわけではない。あまりに根付いてしまった習慣である。1個の数字に集約する、それも、ほぼ直線上、なるべく上になるような数字に、というモチベーションのままに運用され続けている。
本当は、同じ回路を別プロセス(ただし同環境)で作って比較するようなことができれば公正だが、現実的ではないし、実用上は無意味だ(同環境などありえない)。結局のところ、諸般を勘案した「集積度」を代表する数字、ただし、それを算出する統一された公式のようなものはない、ということだろう。もちろん、用途は片対数グラフのどこにそのプロセスを位置付けるか、ということにつきる。ちょっと本末転倒ぎみ。サイズは昔話の1000分の1ほどになったが、ぶっちゃけ方は増している。「細けーことはいいんだよ、コマケーことは」
筆者紹介
Massa POP Izumida
日本では数少ないx86プロセッサのアーキテクト。某米国半導体メーカーで8bitと16bitの、日本のベンチャー企業でx86互換プロセッサの設計に従事する。その後、出版社の半導体事業部などを経て、現在は某半導体メーカーでヘテロジニアス マルチコアプロセッサを中心とした開発を行っている。
「頭脳放談」
Copyright© Digital Advantage Corp. All Rights Reserved.




![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。