第4回 知ってる!? TensorFlow 2.0最新の書き方入門(初中級者向け):TensorFlow 2+Keras(tf.keras)入門(1/2 ページ)
TensorFlow 2.x(2.0以降)では、モデルの書き方が整理されたものの、それでも3種類のAPIで、6通りの書き方ができる。今回は初心者〜初中級者にお勧めの、SequentialモデルとFunctional APIの書き方、全3通りについて説明する。
この記事は会員限定です。会員登録(無料)すると全てご覧いただけます。
前回までの全3回では、ニューラルネットワークの仕組みや挙動を図解で示しながら、TensorFlow(tf.keras)による基本的な実装方法を説明した。しかし実際には、TensorFlowの書き方はこれだけではない。
TensorFlowにおける、3種類/6通りのモデルの書き方
3種類のAPI
大きく分けて、下記の3種類があることを第2回で説明済みである。
- Sequential(積層型)モデル: コンパクトで簡単な書き方
- Functional(関数型)API: 複雑なモデルも定義できる柔軟な書き方
- Subclassing(サブクラス化)モデル: 難易度は少し上がるが、フルカスタマイズが可能
ちなみに、SequentialモデルとFunctional APIは「宣言型」を意味するためSymbolic APIとも呼ばれ、Subclassingモデルは「命令型」を意味するためImperative APIとも呼ばれる。宣言型とは、モデルのレイヤーを宣言的に定義すること(いわゆる“Define-and-Run”)を指し、命令型とはフォワードプロパゲーション(順伝播)の実行フォワードパスを命令的に記述すること(いわゆる“Define-by-Run”)を指す(※バックプロパゲーションのバックワードパスは自動生成される)。
6通りのモデルの書き方
今、述べた3種類の方法は大まかに分けた場合だ。TensorFlow 2.x(2.0以降)における最新の書き方は、さらに細かく分けると、下記の6種類がある(と筆者は認識している)。
【Sequentialモデル】(今回)
(1)tf.keras.models.Sequentialクラスのコンストラクター利用: コンパクトで簡単な書き方。ニューラルネットワークを学びたい初心者には最もお勧めできる。例:連載第2回
(2)tf.keras.models.Sequentialオブジェクトのaddメソッドで追加: シンプルだが、より柔軟性のある書き方。初心者向き。上記のコンストラクターでは対応できない場合に使用
【Functional API】(今回)
(3)tf.keras.Modelクラスのコンストラクター利用: 柔軟に記述できるが、コード量は増える。次のサブクラス化の方が、コードが見やすい。初中級者向き。柔軟性を高めつつ、利便性も確保したいときに使用
【Subclassingモデル】(次回と次々回)
(4)tf.keras.Modelクラスのサブクラス化: 数値計算ライブラリ「NumPy」を使って記述するような感覚で記述できる方法で、柔軟性や拡張性に優れる。ライブラリ「PyTorch」にかなり近い記述が可能なので、両方のライブラリを使いこなしたい人や、TensorFlowを日常的に使いこなしたい初中級者以上には最もお勧めできる。次回、重点的に解説する
(5)TensorFlow低水準APIでカスタム実装: 上記のサブクラス化のレイヤーや活性化関数/損失関数/評価関数などを独自のコードで書く方法。Kerasの基本機能だけでは足りない上級者向け。次々回で解説する
【作成済みEstimators】(次々回)
(6)tf.estimator.Estimatorが提供する作成済みモデル(Pre-made Estimators)の利用: 目的ごとに用意されたDNNRegressor(回帰)/DNNClassifier(分類)クラスなどを使ってモデルを定義できるが、融通が利かないのに、コードが長くなる場合がある。互換性のために残されている(=将来的に廃止される可能性も高い)ので非推奨
ちなみにTensorFlow 2.0以降では、Keras(tf.keras)が「標準の高水準API」となっている。作成済みEstimatorsも高水準APIではあるが、上記の通り、新たなモデル作成では公式に「非推奨」となっているので、tf.kerasがTensorFlowで唯一の高水準APIである。また、(5)の「カスタム実装」も、活性化関数/損失関数/評価関数などTensorFlowの低水準APIを使って記述するが、そのモデルやレイヤーは(基本的に)tf.kerasのものをサブクラス化して使うことになる(※サブクラス化しないで実装することも不可能ではないが、手間を考えるとお勧めできない)。つまり、TensorFlow 2.0の書き方は全て、tf.kerasをどこかしらで活用するということになる。
6通りも書き方があると、覚えることも増えて、混乱が生じやすいだろう。筆者としては、初心者は(1)を、ニューラルネットワークを理解した初中級者には(4)をお勧めしたい。ただし、(4)にするとトレードオフでデメリットも生じる。具体的には、
- コードがどうしても長くなってしまうこと
- モデルの内容確認(model.summary()メソッドなど)ができなくなること
モデルの保存/ロード(model.save()/tf.keras.models.load_model()メソッドなど)ができなくなること(※代わりにmodel.save_weights()/model.load_weights()メソッドを使う)→ TensorFlow 2.1以降では、SavedModel形式(=TensorFlowの標準出力フォーマット)であればモデルの保存/ロードが行えるように改善された(※2020/03/30修正)
といったことがある点に注意が必要だ。それでも将来性を考えると(4)がお勧めである。
今回と次回について
本稿では上記の6通りを、次のように分け、
「第4回 知ってる!? TensorFlow 2.0最新の書き方入門(初中級者向け)」……(1)〜(3)
「第5回 お勧めの、TensorFlow 2.0最新の書き方入門(エキスパート向け)」……(4)
「第6回 カスタマイズするための、TensorFlow 2.0最新の書き方入門」……(5)〜(6)
の全3回で説明する。
TensorFlowのエコシステム/機能構成図
参考までに、TensorFlow全体の機能構成図を示しておこう。この全体は「TensorFlowのエコシステム」とも呼ばれている。

コードの書き方を実行するための準備
前提条件
本連載では、Python(バージョン3.6)と、ディープラーニングのライブラリ「TensorFlow」の最新版2.1を利用する。また、開発環境にGoogle Colaboratory(以下、Colab)を用いる。


TensorFlowの最新バージョンは、リスト0-1のコマンドでインストールできる。
# Google Colabで最新の2.xを使う場合(Colab専用)
%tensorflow_version 2.x
# 最新バージョンにアップグレードする場合
!pip install --upgrade tensorflow
# バージョンを明示してアップグレードする場合
!pip install --upgrade tensorflow===2.1.0
# 最新バージョンをインストールする場合
!pip install tensorflow
# バージョンを明示してインストールする場合
!pip install tensorflow===2.1.0
前提条件の通りにGoogle Colabを使う場合は、「%tensorflow_version 2.x」というマジックコマンドを使用してほしい(※pipコマンドを用いたインストールだとTPUが動作しない、という報告があったため)。このマジックコマンドを実行して「TensorFlow 2.x selected.」と表示されればOKだ。もし「TensorFlow is already loaded. Please restart the runtime to change versions.」と表示される場合は、メニューバーから[ランタイム]−[ランタイムを再起動]を実行した上で、再度、マジックコマンドの実行結果を確かめてほしい。
データについて
今回の入力データには、座標点(X座標、Y座標)のデータを使う。座標点の結果が青色(1.0)かオレンジ色(-1.0)かを学習して、予測判定できるようにする。第1回で使ったデータと同じであるため、データの取得コードの説明は割愛する。
ディープニューラルネットワークのモデル設計
今回はいずれの書き方でも、次のようなディープニューラルネットワークのモデルを設計することとする。
- 入力の数(INPUT_FEATURES)は、Χ1とΧ2で2つ
- 隠れ層のレイヤー数は、2つ
隠れ層にある1つ目のニューロンの数(LAYER1_NEURONS)は、3つ
隠れ層にある2つ目のニューロンの数(LAYER2_NEURONS)は、3つ - 出力層にあるニューロンの数(OUTPUT_RESULTS)は、1つ
これらを定数として、リスト0-2のように定義するとしよう。
# ライブラリ「TensorFlow」のtensorflowパッケージを「tf」という別名でインポート
import tensorflow as tf
from tensorflow.keras import layers # 「レイヤーズ」モジュールのインポート
# 定数(モデル定義時に必要となる数値)
INPUT_FEATURES = 2 # 入力(特徴)の数: 2
LAYER1_NEURONS = 3 # ニューロンの数: 3
LAYER2_NEURONS = 3 # ニューロンの数: 3
OUTPUT_RESULTS = 1 # 出力結果の数: 1
tf.kerasでモデルを設計する際に、レイヤー用のtf.keras.layers名前空間はよく使うのでここでインポートしておくこととする。
さらに、評価関数としてdef tanh_accuracy(y_true, y_pred)という関数を定義しておくこととするが、第3回の「リスト5-5 正解率(精度)のカスタム指標」で解説済みなので説明を割愛する。
それでは準備が整ったので、まずは書き方(1)から順に、今回は書き方(3)までを説明しよう。
(1)Sequentialクラスのコンストラクター利用[tf.keras - Sequential API]
この方法は、第2回の「リスト4-1 ニューロンのモデル設計」と「リスト4-2 ニューラルネットワークのモデル設計」で既に説明済みである。全く同じコードだと面白くないと思うので、数行ほどコードを追加した。
model = tf.keras.models.Sequential([ # モデルの生成
# 隠れ層:1つ目のレイヤー
layers.Dense( # 全結合層
input_shape=(INPUT_FEATURES,), # 入力の形状(=入力層)
name='layer1', # 表示用に名前付け
kernel_initializer='glorot_uniform', # 重さの初期化(一様分布のランダム値)
bias_initializer='zeros', # バイアスの初期化(0)
units=LAYER1_NEURONS, # ユニットの数
activation='tanh'), # 活性化関数
# 隠れ層:2つ目のレイヤー
layers.Dense( # 全結合層
name='layer2', # 表示用に名前付け
kernel_initializer='glorot_uniform', # 重さの初期化
bias_initializer='zeros', # バイアスの初期化
units=LAYER2_NEURONS, # ユニットの数
activation='tanh'), # 活性化関数
# 出力層
layers.Dense( # 全結合層
name='layer_out', # 表示用に名前付け
kernel_initializer='glorot_uniform', # 重さの初期化
bias_initializer='zeros', # バイアスの初期化
units=OUTPUT_RESULTS, # ユニットの数
activation='tanh'), # 活性化関数
], name='sequential_constructor' # モデルにも名前付け
)
# 以上でモデル設計は完了
model.summary() # モデルの内容を出力
前回までは重みやバイアスといったパラメーターの初期化はKerasに任せていた。その場合(つまりデフォルトでは)、重みは「glorot_uniform」(Xavier Glorotの一様分布におけるランダム値: 最小〜最大の範囲を入力ユニット数と出力ユニット数から自動算出)に、バイアスは「zero」(0)になる。
今回は、tf.keras.layers.Denseクラスのコンストラクター(厳密には__init__()メソッド)の引数kernel_initializerに'glorot_uniform'という重みを、引数bias_initializerに'zeros'というバイアスを文字列で指定している(※なお以降のサンプルでは、短くするため、kernel_initializer/bias_initializer引数の記載は省略する)。パラメーターの初期化を行うイニシャライザー(initializer)としては、以下のものが文字列で指定できる。
- glorot_uniform(Xavier Glorotの一様分布におけるランダム値)
- glorot_normal(Xavier Glorotの正規分布におけるランダム値)
- he_uniform(Heの一様分布におけるランダム値)
- he_normal(Heの正規分布におけるランダム値)
- lecun_uniform(LeCunの一様分布におけるランダム値)
- lecun_normal(LeCunの正規分布におけるランダム値)
あと、全体的に各name引数に名前を指定している。これにより、model.summary()メソッドの出力は図1-1のように、モデルやレイヤーの名前が分かりやすくなる。
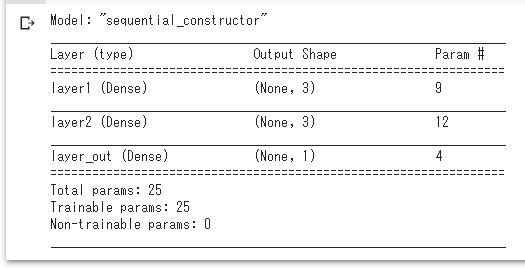 図1-1 モデルの内容を出力
図1-1 モデルの内容を出力また、リスト1-2のコード(※コード内容の説明は割愛)によりモデル構成図を表示すると、図1-2のように表示される。これにも指定した名前が表示されていることが分かるだろう。
tf.keras.utils.plot_model(model, show_shapes=True, show_layer_names=True, to_file='model.png')
from IPython.display import Image
Image(retina=False, filename='model.png')
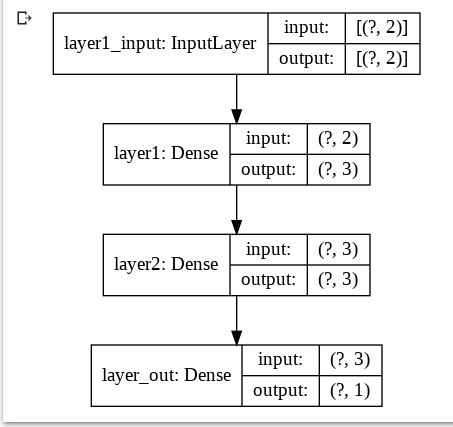 図1-2 モデルの構成図を表示
図1-2 モデルの構成図を表示重み/バイアスの初期化指定【応用】
先ほど、kernel_initializer/bias_initializerには文字列で指定したが、初期化をカスタマイズしたい場合もあるだろう。例えば'glorot_uniform'ではなく、自分で下限と上限を指定した一様分布でランダム値を取りたい場合は、tf.keras.RandomUniformクラスを使ってイニシャライザーを独自に作成すればよい(リスト1-3)。
random_init = tf.keras.initializers.RandomUniform(
minval=-1.0, maxval=1.0) # 下限と上限を指定した一様分布でランダム値
こうやって生成したイニシャライザーをkernel_initializer=random_initのように指定するだけである。
学習と推論: 書き方入門(初中級者向け)で共通
モデルを設計してインスタンス化した後は、第3回と同様に学習方法を設定し、学習し、推論(予測)すればよい(リスト1-4。※今回は以後も同じなので、コメントアウトした状態で、各「書き方」コードの最後に載せておく)。また、playground-dataライブラリからの訓練用データと精度検証用データ(以下のコードでは、X_train変数、y_train変数などに代入している)の取得については、冒頭で示したGoogle ColabまたはGitHubのコードを参照してほしい。
# 学習方法を設定し、学習し、推論(予測)する
model.compile(tf.keras.optimizers.SGD(learning_rate=0.03), 'mean_squared_error', [tanh_accuracy])
model.fit(X_train, y_train, validation_data=(X_valid, y_valid), batch_size=15, epochs=100, verbose=1)
model.predict([[0.1,-0.2]])
ちなみに、モデルの書き方だけでなく、学習に関するコードも、下記のように初中級者向けとエキスパート向けに分かれる。
- 初中級者向けの書き方: リスト1-4のようにcompile()&fit()メソッドを呼び出す、簡単で手軽な書き方
- エキスパート向けの書き方: 次回説明するが、tf.GradientTapeクラス(自動微分の記録機能)を使った柔軟で拡張性の高い書き方(PyTorchの書き方に近い)
作成済みモデルのリセット
先ほどはmodelという変数名でモデルを生成した。書き方を比較しやすいように、以降もmodelという変数名を使う。いったんモデルを削除してリセットしたい場合は、リスト1-5のコードを実行してほしい(※コード内に記載した「計算グラフ」とは、計算の過程(データフロー)を表現したグラフのことで、モデルを設計したことによりライブラリ内部で自動的に構築されている。TensorBoardというツールによってデータフローグラフを視覚的に確認できる)。
tf.keras.backend.clear_session() # 計算グラフを破棄する
del model # 変数を削除する
以上で、書き方(1)の説明を終わりとする。次のページでは、書き方(2)と(3)について説明する。
(2)Sequentialオブジェクトのaddメソッドで追加[tf.keras - Sequential API]
Copyright© Digital Advantage Corp. All Rights Reserved.




![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。