データセット、多次元配列、多クラス分類:作って試そう! ディープラーニング工作室(1/2 ページ)
前回のコードを基に、データセットと多次元配列、データセットを分割する意味、出力層に3つのノードを持たせた場合のあやめの分類などについて取り上げます。
前回はあやめの品種を推測するニューラルネットワークを作りながら、その手順を駆け足で眺めました。今回からは数回にわたって、そのコードを少し詳しく見たり、コードに手を入れたりしながら、ニューラルネットワークなどについての理解を深めていきましょう。まずデータセットに関連する事柄を取り上げます。
データセットと多次元配列
前回に見たあやめのデータセットは、scikit-learnが提供するものでした。以下では、このデータセットを少し詳しく見ながら、データセットとその扱いについて取り上げます。
あやめのデータセットは次のコードで読み込みました。
from sklearn.datasets import load_iris
iris = load_iris()
前回も述べましたが、データセットには一定の形式で複数のデータが格納されています。このうちの、data属性は「4つの浮動小数点数値を要素とする配列」を要素とする配列(配列の配列)でした。

最もシンプルな配列は、その要素が一方向に並べられたものです。
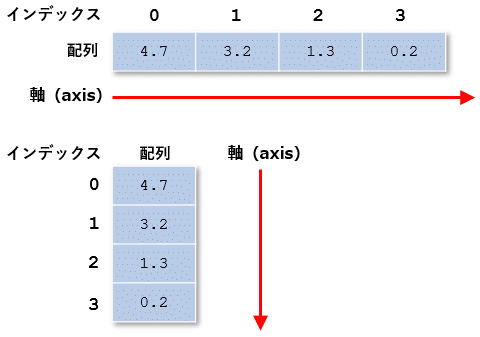 最もシンプルな1次元の配列
最もシンプルな1次元の配列その要素にはインデックス(配列内での特定の要素がどこにあるかを示す値)を1つ指定することでアクセスできます。このとき、配列が並んでいる方向のことを「軸」(axis)と呼ぶことがあります。また、軸の数を「次元数」「階数」などと呼びます。最もシンプルな配列は、軸が1つで、次元数も1です。
これに対して、配列の配列は、1次元の配列がもう1つの軸に沿って並べられているものと考えられます。すなわち、配列の配列は軸が2つある(次元数が2の)データ構造です。このことから、今述べたような「4つの浮動小数点数値を要素とする配列」を要素とする配列は、よく「2次元配列」と呼ばれます。数学用語を使って「行列」とも呼ばれます。

上の図に示したように、2次元配列では縦軸(軸0)に沿って行の要素が並べられ、横軸(軸1)に沿って列の要素が並べられます。2次元の配列で特定の要素にアクセスするには、インデックスを1つ、または2つ指定します。
1つ指定したときには、配列を要素としている(軸0に沿って並んでいる外側)配列(行)のインデックスが指定されたものとして扱われます。つまり、これにより外側の要素の配列となっている配列(今回の例なら、個々のあやめのデータにアクセスすることになります)。
インデックスを2つ指定すると、それは配列の要素となっている配列の特定の要素にアクセスすることになります(今回の例であれば、個々のあやめのデータを構成するがく片の長さ/幅、花弁の長さ/幅のいずれかの要素にアクセスすることになります)。
あやめのデータセットでは、そのがく片の長さと幅、花弁の長さと幅の4つの数値をひとまとめにした配列を要素とする配列を扱うだけなので、2次元の配列で十分でしたが、画像のようにもともとが2次元の構造を持つデータを大量に含むデータセットでは3次元の配列が出てくることもあるでしょう(ただし、こうしたデータは画像という2次元のデータを1次元のデータに変換して使用することもよくあります)。
機械学習やニューラルネットワークの世界では、重みやバイアス、入力されるデータ、計算結果の出力など、さまざまな場面で変数を大量に使用します。また、実際の計算処理では、行列の操作や演算も頻繁に登場します。そのため、多数の変数を一括して、高速に処理できる科学計算ライブラリであるNumPyや、それを基に発展したさまざまなフレームワークが使われるのは前回にもお話しした通りです。
また、PyTorchなどのフレームワークでは、配列などのデータ構造のことを「テンソル」と総称することも前回に紹介した通りです。また、こうしたデータ構造の中でも1次元配列は「ベクトル」とか「ベクター」と、2次元配列のことは「行列」などと呼ぶこともよくあります。3次元配列など、次元(階数)が3を超えるものについては特別な名称はなく、「テンソル」と呼ぶのが一般的です。これらの用語にも徐々に慣れていく必要があるでしょう。
用語に慣れるのと同時に、テンソルの扱いにも慣れていく必要もあります。そこで、PyTorchのテンソルの扱いを少しだけ見ておきましょう。詳しくは「PyTorchのテンソル&データ型のチートシート」を参照してください。
import torch
X = torch.tensor(iris.data) # 入力データをPyTorchのテンソルに変換
# Xのサイズを調べる
print(X.size())
print(X.shape) # NumPyと同様な書き方
print(len(X)) # 外側の配列の要素数(行数)
print(X.dim()) # テンソルの次元数
print(X.ndim) # NumPyと同様な書き方
# テンソルの要素のデータ型を調べる
print(X.dtype)
# テンソルの要素へのアクセス
print(X[0]) # 先頭行
print(X[0][0]) # 先頭行の先頭要素
print(X[1:3]) # 第1行と第2行
print(X[1:3, 1:3]) # 第1行と第2行の1列目と2列目の要素
print(X[1:3][1:3]) # この書き方は意味が異なる点に注意
上のコードを実行した結果は次の通りです。
 実行結果
実行結果気を付けてほしいのは、最後の2行の出力です。どちらも行列のスライスを取得するコードですが、取り出され方が異なります。「X_train[1:3, 1:3]」は行列の第1行と第2行から第1列と第2列の要素を取り出すものです。一方、「X_train[1:3][1:3]」は行列の第1行と第2行からなる配列を取り出した上で、その第1行と第2行を取得するものです(インデックスはゼロ始まりなので、実際には第1行だけが得られます)。その上にある出力と比較すると、どのようにデータが取り出されているかが分かるでしょう。
今回は、こうした操作が出てくることはあまりありませんが、後続の回で、必要に応じて紹介していくことにします。
データセットの分割について
前回は、読み込んだデータセットを学習と評価(テスト)に使用する目的で2つに分割しました。
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target)
上のコードではデータセットを2つに分割しています。これは前回も見たように、ニューラルネットワークでモデルの学習を行い、その評価(検証/テスト)を行うためです。しかし、実際に自分でニューラルネットワークを作成していると分かりますが、学習を行う際には試行錯誤がつきものです。例えば、ニューラルネットワークのノードの数を変更したり、層を増やしたり減らしたり、活性化関数を変更したりということが発生します(こうした要素を「ハイパーパラメーター」と呼びます)。
このような調整を行う前には、ある時点で作成した(完成前の)ニューラルネットワークモデルがどの程度の精度を持っているかを調べる必要があります。精度を調べて、ハイパーパラメーターを調整して、また学習をやり直して、その精度を評価して……という過程を経ながら、最適なハイパーパラメーターを決定する場合もありますし、あるいは異なるハイパーパラメーターを使って学習させたニューラルネットワークモデルを幾つか用意して選ぶといった場合もあるでしょう。このように、試行錯誤の段階では、訓練データと、暫定的に作成したモデルの精度を検証するデータの2つのデータが必要になります(前回は単純にscikit-learnが提供するtrain_test_split関数を用いて分割していましたが、実際には訓練データと評価データを分割するにはさまざまな手法があります)。
学習と評価を繰り返して完成したモデルは学習データと評価データに対してはよい精度で結果を算出できるようになっています。一方、それが本当に汎用的に使えるかどうか(すなわち、未知のデータについてもよい精度で結果を算出できるかどうか)をテストするためには、今述べた2つのデータとは独立したデータ(テストデータ)が必要です。
こうしたことから、データセットを次の3つに分割するというのが最近では一般的になっています。
- 訓練データ:ニューラルネットワークでの学習(モデル内の重みやバイアスの更新)に使われる
- 評価データ:学習後のモデルの性能を検証するために使われる
- テストデータ:最終的に完成したモデルが汎用的に使えるかどうかをテストするのに使われる
前回は学習時のさまざまなパラメーターは決め打ちとして、試行錯誤することなく、ニューラルネットワークのモデルに学習をさせ、一度の学習でモデルを完成させたので、2つに分割すれば十分でした。
2つ(あるいは3つ)に分割したデータセットは、学習やその後の評価、テストで使われます。データセットのデータをそのまま素直に扱えれば問題はないでしょうが、前回も見たようにフレームワークに合わせたデータ型の変換が必要になることもあるでしょうし、作成するモデルにうまく適合するようにデータを変換しなければならないこともあります。そこで、次ページでは、前回に見たニューラルネットワークモデルを少し変更して、データセットに含まれるデータやモデルの計算結果の扱いや解釈がどう変わるかを見てみます。
変数名について
上のコード例では、データセットを分割して、「X_train」「y_test」などの変数に代入していました。ここでこれらの変数名について少しだけ話をしておきます。
数学の世界では、関数とその値をよく「y=f(x)」と表します。これは「f」という関数(function)に「x」という変数が持つ値を与えると、その結果が「y」になることを意味します。ここで、これから作成するモデルを関数として考えると、「入力→関数(モデル)→出力」のようにも書き表せます。このとき入力するデータ(あやめの特徴を示す4つの値)は前述の「x」に、出力(モデルにより算出されたあやめの種類)は「y」に相当することはお分かりでしょう。
このことに合わせて、ここでは学習やテストのときにモデルに入力する値は「X」で、その出力と比較する正解ラベルは「y」で始まるような名前としています。「X」が小文字ではなく大文字になっているのは、入力するものがデータセット、つまり『「1個以上の値で構成される配列」を要素とする配列』=「行列」であり、数学では、行列は大文字で表現することからこのような命名方法になっています。
その後に続く「train」「test」というのは、読んで字のごとく、それが学習(訓練、train)で使われるか、できたモデルの評価(テスト、test)で使われるかを意味します。これら2つの要素をアンダースコア「_」でつなげたものをここでは変数名として使っています。
もちろん、これ以外の命名法もあるでしょう。例えば、「X_train」ではなく「train_data」としたり、「y_train」ではなく「train_label」としたりすることが考えられます。こちらの方法でも、変数の値が訓練データであること、訓練に使用する正解ラベルであることが分かります。いずれにせよ、その変数が何のためのデータを参照するものかが分かる名前にすることが大事です。
Copyright© Digital Advantage Corp. All Rights Reserved.




![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。