第8回 分類問題をディープラーニング(基本のDNN)で解こう:TensorFlow 2+Keras(tf.keras)入門(2/3 ページ)
―――【多クラス分類編】―――
それでは準備が整ったとして、(1)から順に話を進めていこう。
(1)データの準備
前述の通り、多クラス分類問題では「Fashion-MNIST」データセットを用いる。このデータセットは、TensorFlowやtf.kerasで簡単に導入できるので、特別な準備は必要ない。Fashion-MNISTデータセットの内容は、図5に示すようなファッション商品の小さな写真であり、教師データとなるラベルには、分類カテゴリーごとに(商品カテゴリー名ではなく)0〜9のクラスインデックスが指定されているので、カテゴリー変数エンコーディングの作業も不要である。

実際にtf.kerasを使ってtf.keras.datasets.fashion_mnist.load_data()というコードで、Fashion-MNISTデータセットを取得しているのがリスト1-1である(※重要箇所は太字にした)。
# TensorFlowライブラリのtensorflowパッケージを「tf」という別名でインポート
import tensorflow as tf
import matplotlib.pyplot as plt # グラフ描画ライブラリ(データ画像の表示に使用)
import numpy as np # 数値計算ライブラリ(データのシャッフルに使用)
# Fashion-MNISTデータ(※NumPyの多次元配列型)を取得する
(X_train, y_train), (X_test, y_test) = tf.keras.datasets.fashion_mnist.load_data()
# データ分割は自動で、訓練用が6万枚、テスト用が1万枚(ホールドアウト法)。
# さらにそれぞれを「入力データ(X:行列)」と「ラベル(y:ベクトル)」に分ける
# ※訓練データは、学習時のfit関数で訓練用と精度検証用に分割する。
# そのため、あらかじめ訓練データをシャッフルしておく
p = np.random.permutation(len(X_train)) # ランダムなインデックス順の取得
X_train, y_train = X_train[p], y_train[p] # その順で全行を抽出する(=シャッフル)
# [内容確認]データのうち、最初の10枚だけを表示
classes_name = ['T-shirt/top [0]', 'Trouser [1]', 'Pullover [2]',
'Dress [3]', 'Coat [4]', 'Sandal [5]', 'Shirt [6]',
'Sneaker [7]', 'Bag [8]', 'Ankle boot [9]']
plt.figure(figsize=(10,4)) # 横:10インチ、縦:4インチの図
for i in range(10):
plt.subplot(2,5,i+1) # 図内にある(sub)2行5列の描画領域(plot)の何番目かを指定
plt.xticks([]) # X軸の目盛りを表示しない
plt.yticks([]) # y軸の目盛りを表示しない
plt.grid(False) # グリッド線を表示しない
plt.imshow( # 画像を表示する
X_train[i], # 1つの訓練用入力データ(28行×28列)
cmap=plt.cm.binary) # 白黒(2値:バイナリ)の配色
plt.xlabel(classes_name[y_train[i]]) # X軸のラベルに分類名を表示
plt.show()
このコードを実行すると、データセットの最初の10枚の画像を2行5列で表示する(※写真自体は図5で示したので、実行結果の掲載は省略した)。
リスト1-1を見ると、今回は、データセットとして、
- 訓練データ: 入力データとなる特徴量X_trainと、正解となるラベルy_train
- テストデータ: 特徴量X_testと、ラベルy_test
の2種類を用意しているのが分かる。ちなみにこのような分け方をホールドアウト法(Hold-out method)と呼ぶ。連載中に何度も言及しているが、テストデータ(ホールドアウトデータ、Hold-out setsとも呼ぶ)は最終的な性能テストに使うので、訓練時の精度検証には使わないように別枠で取っておかなければならい。
「あれ? 精度検証データは?」と思った人は鋭い。ホールドアウト法は、統計学/データサイエンスの重回帰分析をする場合などでは有効である。しかし、ニューラルネットワーク(ディープラーニング)では、過学習などが起こりやすいのでハイパーパラメーターのチューニングを行う必要があり、そのため、精度を検証(validation)するためのデータも必要となるのだ。
繰り返しになるが、この検証作業にテストデータを使ってはいけない。機械が何度もトレーニングすることによって訓練データへの過学習が生まれるように、人間が何度もチューニングすることによって精度検証データへの偏向が生まれている可能性がある。そのため、「そういった過学習や偏向が確実にない」と言える未知のテストデータに対しても(つまり汎用的に)、学習済みモデルが本当に使える性能を発揮するか(=汎化性能)を最終テストした方がよいからだ。
そういった理由で、訓練データの中から精度検証データを分離する必要があるのだ(※本連載では「精度検証」と呼んでいるが、正式には単に「検証」が正しい。ただし、「検証」と「テスト(検定)」の違いが「特に初学者には分かりづらい」と想定して、あえて「精度検証」と呼んでいる)。チュートリアルや書籍によっては、テストデータで検証しているが、これは「テストデータ」という名前の「精度検証データ」なのだ、と捉えてほしい。
で、なぜここで、前回までのように、
- 精度検証データ: 特徴量X_validと、ラベルy_valid
を作成しないかというと、tf.kerasのfit()メソッドにvalidation_split引数が用意されており、そこに任意の精度検証データの割合を指定できるからだ。割合として、例えば20%(=0.2)を指定すると、訓練データが「訓練データ80%」と「精度検証データ20%(=0.2)」に分割される(本当に便利な機能である)。
ちなみに、validation_split引数の指定は「訓練データの後ろから何%」という固定的な分割方法になる。そのため、リスト1-1で事前に訓練データをシャッフルして、データが固定的にならないようにしておいたのだ。このように検証を固定的にしない別のアプローチに、交差検証(Cross validation)というテクニックがある。交差検証の中でも特に有名なのがk分割交差検証(k-fold cross validation)で、具体的にはデータをK個(例えば5個)に分割して、その1つを検証データとして、訓練のたびに検証データの位置を(例えば、1個目、2個目、3個目、4個目、5個目、……と)ずらしながら繰り返し学習していく。特に訓練データ数が少ない場合には、k分割交差検証が効果的である。……と、このような説明だけでは伝わらないと思うが、交差検証だけで記事が1本書けるので、より詳しくは今後の連載に委ねることにする。
まとめると、最終的なデータ分割は図6のようになる。
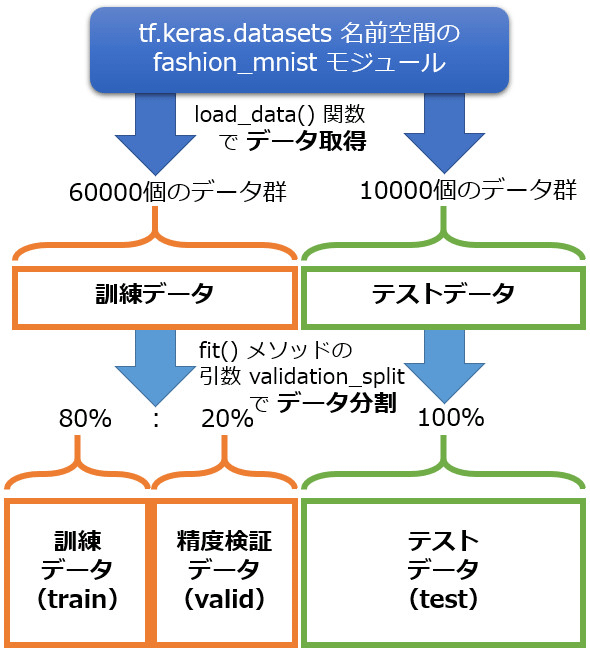 図6 今回のデータセット分割は「訓練/精度検証/テスト用」の3種類
図6 今回のデータセット分割は「訓練/精度検証/テスト用」の3種類また前回同様、ミニバッチ学習用のデータ分割は、fit()メソッドが自動的に行ってくれるため、今回もバッチデータ化は行わない。
MNIST系の画像データセットのフォーマットについて
これまでの連載では、座標点という非常にシンプルなデータを扱ってきたので、「画像データ」というのがどういうデータで、それがどのように入力されるのか、想像が付かないという人もいるだろう。そこで画像データセットのフォーマットについて簡単に説明しておく。
Copyright© Digital Advantage Corp. All Rights Reserved.




![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。