
第1回 並列処理を体感してみよう
株式会社フィックスターズ
浅原 明広
2009/7/8
CPUの周波数の高速化競争が頭打ちになり、1コアにおける処理能力は限界となった。CPUの進化がマルチコア化に向かった結果、並列コンピューティングの門戸が開かれた(編集部)
いまだからこそ“Think Parallel”
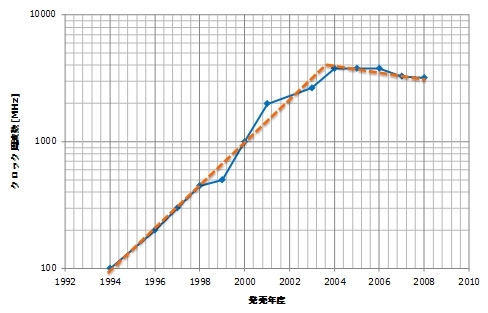
CPUの動作周波数が毎年のように改善され、ソフトウェアが放っておいても速くなったのは、古き良き時代の話。
Intel CPUの周波数が4GHzに近づいた2004年ごろからは、消費電力や発熱量の増加が、いわゆる“Power Wall”という深刻な問題として立ちふさがり、CPUの動作周波数は頭打ちとなりました。
変わってCPUの進化は、演算コアの増加という形で現れるようになってきています。つまり、CPUコアの動作周波数はまったく変わらないか、むしろ若干遅くなる傾向にあるため、1コアで動作するシーケンシャル(Sequential:逐次処理)なコードは、最新のCPUを使っても、ほとんど速くならないのです。
PC1台では時間がかかり過ぎて解けない問題に対して、複数の計算機を高速なネットワークにつないで分散処理させるという方法があります。大規模シミュレーションなどのいわゆるHPC(High Performance Computing)と呼ばれる分野では、昔からこのような分散処理の手法がとられてきました。
分散処理を行うためには、対象としている問題のデータ構造や処理の依存関係を分析し、複数の計算機で並列に処理できるようにアルゴリズムを書き換え、フレームワークとしてMPI(Message Passing Interface)と呼ばれる関数群を駆使する必要がありました。これらの技術は、ある意味で一部のエンジニアの特殊技能といってもよかったと思います。
マルチコアプロセッサの時代とは、このような分散処理技術が1チップのCPUに降りてきたようなものです。複数個の演算コアを1チップに収めた、いわゆるマルチコアプロセッサ(Multi Core Processor)の登場、さらにはCell Broadband EngineやGPUに代表されるような、多数の演算コアが1チップになったメニーコアプロセッサ(Many Core Processor)の台頭により、すべてのソフトウェア開発者が、データや処理の分割を考慮すべき時代になったといえるでしょう。

並列処理手法とは何か
まず、ソフトウェアにおける並列処理とは何でしょうか。Wikipediaの「並列コンピューティング」によれば、
とあります。簡単な例として、以下のコードを見てください。
001: /*
002: * Array のインクリメント
003: */
004:
005: #include<stdio.h>
006: #define N 100000
007:
008: int main (int argc, char *argv[])
009: {
010: int i;
011: int *rootBuf;
012:
013: rootBuf = (int *)malloc(N * sizeof(int));
014:
015: /* Initialize */
016: for(i=0;i<N;i++){
017: rootBuf[i] = i;
018: }
019:
020: /* Incriment */
021: for (i = 0; i < N; i++) {
022: rootBuf[i] = rootBuf[i] + 1;
023: }
024:
025: free(rootBuf);
026:
027: return;
028: }rootBufという配列の各要素を1インクリメントするという非常に単純なコードですが、配列の要素数が10000と大きいのが特徴です。
Intel Core 2 QuadのCPUを使っているとして、並列処理の視点に立ってこのコードを見た場合、1つのコアで10000回演算するよりも、2500ループずつ4つのタスクに分割して、4コアを使って演算すれば4倍速くなるのではないか、と思うわけです。
実際には、リスト1のように演算量が少なく、データのLoad/Storeの方に時間がかかるコードでは、思うように速度が上がらず、下手をすると1コアで素直に演算した方が早い場合もあります(そこが並列処理の難しいところになるのですが……)。後ほど、実際にリスト1を並列化して、処理速度を実測してみましょう。
実際に“複数のプロセッサで1つのタスクを動作させる”ためのハードウェアアーキテクチャはさまざまですが、ハードウェアのメモリ構成に注目すると、共有メモリ型並列処理システムと分散メモリ型並列処理システムに大きく分類することができます。

共有メモリ型とは、システムを構成する各CPUが共通のメモリ空間にアクセス可能な構成であり、分散メモリ型とは、各CPUがそれぞれ異なるメモリ空間を持つという構成です。このようなメモリ構成の違いは、そのままデータのやりとりの手段の違いに現れます。
例えば、上図のシステムにおいて各CPUで1つのプロセスが走っている場合、共有メモリ型であれば、プロセス間でのデータのやり取りは単に共通のメモリ空間のRead/Writeになりますが、分散メモリ型では、明示的にデータの送受信を行う必要があります。以下ではそれぞれの型における並列化手法について詳しくみてみましょう。
1/3 |
| Index | |
| 並列処理を体感してみよう | |
| Page1 いまだからこそ“Think Parallel” 並列処理手法とは何か |
|
| Page2 分散メモリ型並列処理システムにおける並列化 Message Passing Interface |
|
| Page3 共有メモリ型並列処理システムにおける並列化 OpenMP |
|
| Think Parallelで行こう! |
- プログラムの実行はどのようにして行われるのか、Linuxカーネルのコードから探る (2017/7/20)
C言語の「Hello World!」プログラムで使われる、「printf()」「main()」関数の中身を、デバッガによる解析と逆アセンブル、ソースコード読解などのさまざまな側面から探る連載。最終回は、Linuxカーネルの中では、プログラムの起動時にはどのような処理が行われているのかを探る - エンジニアならC言語プログラムの終わりに呼び出されるexit()の中身分かってますよね? (2017/7/13)
C言語の「Hello World!」プログラムで使われる、「printf()」「main()」関数の中身を、デバッガによる解析と逆アセンブル、ソースコード読解などのさまざまな側面から探る連載。今回は、プログラムの終わりに呼び出されるexit()の中身を探る - VBAにおけるFileDialog操作の基本&ドライブの空き容量、ファイルのサイズやタイムスタンプの取得方法 (2017/7/10)
指定したドライブの空き容量、ファイルのタイムスタンプや属性を取得する方法、FileDialog/エクスプローラー操作の基本を紹介します - さらば残業! 面倒くさいエクセル業務を楽にする「Excel VBA」とは (2017/7/6)
日頃発生する“面倒くさい業務”。簡単なプログラミングで効率化できる可能性がある。本稿では、業務で使うことが多い「Microsoft Excel」で使えるVBAを紹介する。※ショートカットキー、アクセスキーの解説あり
|
|
注目のテーマ





