
XMLデータベース開発方法論(1) Page 3/4
序章、データ処理技法の地政学
川俣 晶
株式会社ピーデー
2005/6/28
筆者が使い捨てのデータ処理に開眼したのは、1989年にトッパンより出版された名著『プログラミング言語AWK』(A.V.エイホ/B.W.カーニハン/P.J.ワインバーガー著、足立高徳訳)によってである。この当時、日本でもごく一部でAWKブームが起こっていて、マニアックなパソコン通信ホストとして知られた日経MIXなどで盛り上がっていた。
AWKは、プログラミング言語とは呼ばれるものの、むしろスクリプト言語と呼ぶにふさわしい軽さを持っている。AWKは、わずかなコードを記述することで、テキスト形式で入力されたデータにさまざまな処理を行うことができる。ここでいう「わずかなコード」とは、1行から意味のあるデータ処理を記述できることを意味する。この当時、鮮烈な印象を持って覚えた言葉に、「1行野郎(One Liner)」というものがあるが、これは何らかの意味のある処理を、たった1行で記述したものを示す。
このようなデータ処理のやり方があるということを知らない読者も多いと思われることから、実例を以下に示そう。ご存じの方は、あまりに当たり前の話しか語らないので、読み飛ばしていただきたい。
例えば、試験の点数を書き込んだ以下のようなファイルがあるとする。本当は、手動で処理するのが嫌になるぐらい長いファイルがよいのだが、ここでは把握しやすいサンプルということで、短いものを示す。各行は、それぞれ、名前、国語の点数、算数の点数、理科の点数、社会の点数を記入しているものとする。
たろう 67 99 41 55 |
| リスト1 成績表データ |
さて、あるときに、突発的に国語の成績がずば抜けて良いのに社会の成績が振るわない生徒を抜き出すニーズが発生したとしよう。偉い人の気まぐれ、1回限りのデータ処理ということになる。たかが1回限りのこのような処理のために、いちいちRDBを持ち出し、テーブルを設計し、このファイルの内容をインポートし、クエリのSQL文を書くのは面倒でありすぎるだろう。
AWKを使うと、コマンドラインから以下の1行を入力するだけで結果を得られる。これは、GNU AWKによってWindows上で実行する例である。この1行は、国語の点数が90点を超え、社会の点数が50点に満たない生徒を抜き出し、その生徒の名前、国語の点数、社会の点数の3つを出力する。
gawk "$2 > 90 && $5 < 50 { print
$1, $2, $5 }" sample001.txt |
| リスト2 成績表データを処理するAWKプログラム |
念のためにいえば、上記の1行は、コマンドラインに入力する1行のコマンドであって、AWKソースコードはその中の一部にすぎない。つまり、実行に必要な文字のすべてが、この1行に収まっているわけである。
これを実行すると以下のようになる。
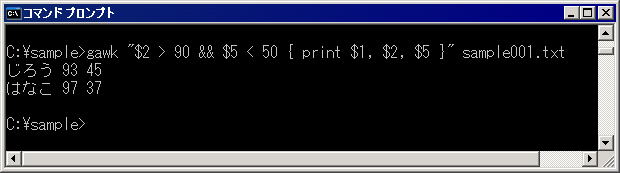 |
| 図1 リスト1の出力結果 (画面をクリックすると拡大します) |
つまり、この条件に該当するのは「じろう」君と、「はなこ」ちゃんであり、それぞれの国語と社会の点数が出力されているわけである。
不定形の処理にもAWKは強い。その一例を見ていただこう。書式が一定しない簡単なデータの一例を以下に示す。とある財布にお金が入るときには、「入金」の文字と数字が1つ。しかし、この財布のお金で何かを購入するときには、単価と個数の2つの数字が書かれている。このようなデータは、RDBで扱えないとはいわないものの、RDBのテーブルとは相性が良くない。
入金 1000 |
| リスト3 入出金データ |
このファイルを入力とし、最終的な残金を計算するAWKプログラムは以下のようになる。
$1 == "入金" { sum += $2 } |
| リスト4 入出金データを処理するAWKプログラム |
これを実行すると以下のようになる。
 |
| 図2 リスト4の出力結果 |
条件が異なる場合の処理を分けて記述するために行数が増え、コマンドラインに含めることはできなくなってしまった。しかし、依然として使い捨てにしても問題ないぐらいに短く、簡単なソースコードである。
さて、私はAWKが大好きである。なぜかといえば、私が扱うデータ処理は、突発的、小規模、不定形であるものが多いからだ。このようなデータをRDBで扱うことは、効率がよくない。AWKであれば、1行から意味のあるデータ処理が実現でき、1回限りのデータ処理のために使い捨ての処理を書くことも苦にならない。
もちろん、一般のパソコン利用者がAWKを使うのはハードルが高すぎ、現実的ではない。しかし、プログラマではなくても、AWKを利用できるユーザー層は存在する。システムの知識に精通したハイエンドのユーザー(パワーユーザー)は、本格的なプログラムは組めなくとも、しばしばAWKの水準(大ざっぱにいえばPerl、Python、Rubyなどと同程度かそれより低い水準)に乗り出してきて、有益に活用することがある。それが可能であるのは、AWKの言語仕様が小さく、また前置きとなる宣言のたぐいを可能な限り省いた言語仕様に負うところが大きい。
そして、AWKによるデータ処理は、RDBによるデータ処理の対極に存在するといってよいだろう。RDBによるデータ処理は、専門家によって構築され、大量の定型化された情報を効率よく処理し、日常業務の中で数え切れないほど繰り返し長期にわたって使うことができる。しかし、AWKによるデータ処理は、ユーザー自身が記述し、少量の不定形の情報を効率は悪くとも必要十分な時間で処理し、使い捨てられる。
Perlをご存じの方のために1つだけ補足しておく。現在、Perlの歴史を語るときに、その祖先としてAWKの名前が出ることがある。しかし、AWKをPerlに似た言語と考えることは適切ではない。PerlはAWKのように使うこともできるが、本格的なプログラム言語として使うこともできる。RDBすら手足のごとく使いこなすPerlは、AWKとは異なる存在であると思う方がよいだろう。
次は、まったく対照的ともいえるRDBとAWKの関係をまとめてみよう。
世の中には、RDBとAWKのほかにも多数の技術があるが、誌面の都合で対照的なこの2つに絞って話を進めよう。
RDBとAWKは、どちらも実際に役立つデータ処理手法といえる。そのことに、おそらく議論する価値はない。どちらも、これまでの長い年月の間、実際に役立ってきたという歴史があるからである。まず、RDBに多くの実績があることは、いまさら説明する必要もないだろう。ではAWKはどうだろうか。標準的な業務システムの開発でAWKが使われる機会はほとんどないと思うので、そのような開発に従事してきた方々はAWKの名前も聞いたことがないかもしれない。しかし、それは単にそのようなシステムにAWKは向かないから使われていないというだけの話である。AWKが活用されるのは、また別の世界である。しかも、AWKは使い捨ての処理に使われることが多いので、AWKで処理された結果としてのデータが公開されたとしても、AWKを使ったという事実は表に出にくい。AWKはそのような意味でも、目に付きにくい存在といえるだろう。
さて、RDBとAWKがどちらも役立つとしても、RDBをAWKに置き換えてうまくいくわけではない。すでに見たように、世の中にはRDBに向いた対象と、AWKに向いた対象がある。つまり、この2つは世界の中で立っている場所が違うのである。ここでは仮に、RDBが立っている場所を「定型」処理、AWKが立っている場所を「不定型」処理と考えてみよう。
 |
| 図3 異なる場所に立つ技術 (注:雰囲気を把握するために単純化した説明図であって、内容は厳密に正確ではない) |
では、この2つの場所だけ踏まえていればすべてのデータ処理を理解できるのだろうか。そうではない。この2つの場所の中間にも世界は広がっている。例えば、「定型」なのだが、部分的に「不定型」が入り込んでいるデータ処理もあり得るだろう。つまり、ここで筆者が扱いたい領域は、2つの点ではなく、2つの点を結ぶ直線なのである。直線上には無数の点があり、それぞれが独自のデータ処理方法を主張している。
 |
| 図4 定型・不定型直線 (注:雰囲気を把握するために単純化した説明図であって、内容は厳密に正確ではない) |
適材適所でデータ処理方法を選択するということは、抱え込んだニーズが世界の中のどの位置にあるかを把握し、そこに最も近い点を選択することを示す。
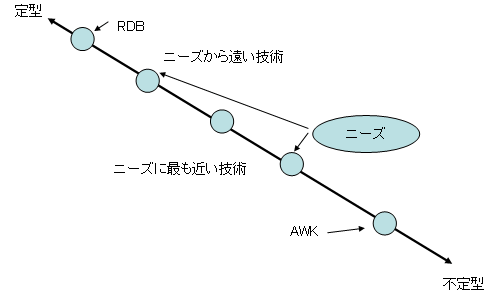 |
| 図5 最適な技術はニーズに最も近い (注:雰囲気を把握するために単純化した説明図であって、内容は厳密に正確ではない) |
あらためて念を押そう。本連載において、最善のデータ処理方法は1つに限定されない。最善のデータ処理方法とは、ここで述べた直線上にあって、ニーズの在りかに最も近い方法を示す。つまり、ニーズが変われば最善も変わる。RDBは常に最善ではないし、AWKも常に最善ではない。XMLデータベースを扱う連載でありながらこのような主張は奇異に思われるかもしれないが、XMLデータベースも常に最善の選択とは限らない。
次に、筆者の大好きなXMLがやっと登場する。(次ページへ続く)
| 3/4 |
| Index | |
| XMLデータベース開発方法論(1) 序章、データ処理技法の地政学 |
|
| Page
1 ・本連載の目的 ・本連載の価値観「すべきである」対「せざるを得ない」 ・本連載のお約束 ・筆者の立場と議論の進め方 ・XMLデータベースの定義 |
|
| Page
2 ・ここがスタートライン、データ処理技法の個人史 ・対照的な2つのデータ表現方法 ・例外的処理こそが重要である |
|
| Page
3 ・AWK、使い捨てデータ処理の切り札 ・問題を認識する領域 |
|
| Page
4 ・RDBとAWKの中間ポイントに位置するXML ・さまざまな技術たち ・挫折、XMLはAWKの不満を解消し得なかった ・結末、そしてXMLデータベースへ ・次回予告 |
|
| XMLデータベース開発論 |
- Oracleライセンス「SE2」検証 CPUスレッド数制限はどんな仕組みで制御されるのか (2017/7/26)
データベース管理システムの運用でトラブルが発生したらどうするか。DBサポートスペシャリストが現場目線の解決Tipsをお届けします。今回は、Oracle SE2の「CPUスレッド数制限」がどんな仕組みで行われるのかを検証します - ドメイン参加後、SQL Serverが起動しなくなった (2017/7/24)
本連載では、「SQL Server」で発生するトラブルを「どんな方法で」「どのように」解決していくか、正しい対処のためのノウハウを紹介します。今回は、「ドメイン参加後にSQL Serverが起動しなくなった場合の対処方法」を解説します - さらに高度なSQL実行計画の取得」のために理解しておくべきこと (2017/7/21)
日本オラクルのデータベーススペシャリストが「DBAがすぐ実践できる即効テクニック」を紹介する本連載。今回は「より高度なSQL実行計画を取得するために、理解しておいてほしいこと」を解説します - データベースセキュリティが「各種ガイドライン」に記載され始めている事実 (2017/7/20)
本連載では、「データベースセキュリティに必要な対策」を学び、DBMSでの「具体的な実装方法」や「Tips」などを紹介していきます。今回は、「各種ガイドラインが示すコンプライアンス要件に、データベースのセキュリティはどのように記載されているのか」を解説します
|
|





