アーキテクチャ・ジャーナル 並列プログラムの開発 Ranjan Sen2010/02/03 |
 |
|
|
|
■並列プログラムの開発
設計をより正確に理解するには、共有メモリ モデルや分散メモリ モデルよりも高いレベルのモデルを使用します。それは、タスク/チャネル モデルです(参考資料の [Quinn, 2004] を参照)。タスクとは、プログラム、プログラムのローカル メモリ、および I/O ポートのコレクションです。タスクは、オペレーティング システムではプロセスとして表されます(プロセスにはスレッドが含まれます)。ローカル メモリには、プログラムの命令とデータが含まれます。タスクは、出力ポートを介して他のタスクにローカル データ値を送信し、入力ポートを介して他のタスクからデータ値を受信できます。“チャネル”とは、あるタスクの出力と、他のタスクの入力ポートとを接続するメッセージ キューです。入力ポートのデータ値の順序は、チャネルの他方の出力ポートに配置されたデータ値の順序と同じになります。
図 4 は、タスク/チャネル モデルの概念図を示しています。タスクは円形のノードで表されており、チャネルは矢印で表されています。タスク i とタスク j の間にある矢印は、タスク j がタスク i に依存していることを示しています。依存していないタスクは、並列で実行できます。したがって、タスクが並列で実行される場合、タスク j はタスク i がデータを送信するまで待機する必要があります。これを“データ依存”と呼びます。この場合、グラフはデータ フロー グラフになります。しかし、チャネルが完了シグナルを表す場合、これは“制御依存”になります。この場合、グラフは制御フローグラフ(タスクグラフとも呼ばれる)になります。
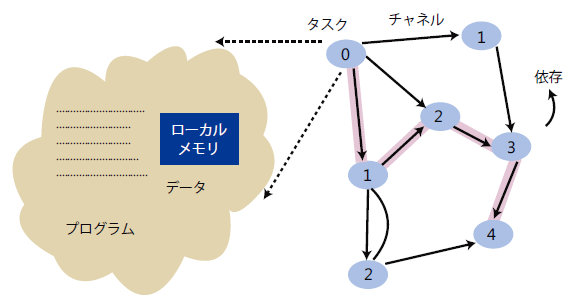 |
| 図 4: タスク/ チャネル モデルの概念図 |
“タスク並列性”は、依存していないタスクを同時に実行することで実現できます。図 4 で、同じ数字を持つノードに対応するタスクが並列で実行されており、タスク並列性を実現できていることに注目してください。一方、は、“データ並列性”データの素集合で、単一または複数のタスクを実行することで実現できます。
並列プログラム設計で使用される 4 段階のプロセス(分割、通信、凝集化、マッピング)について考えてみます(参考資料の [Foster, 1995] および [Dongarra, 2003] を参照)。“分割”とは、計算およびデータを小さなプリミティブ タスクに分割することです。プリミティブ タスクの数を増やすと、設計する並列プログラム内で並列化できない部分を減らすことができます。アムダールの法則とグスタフソンの法則で示唆されている理論的な限界によると、この方法によって並列で処理できる量を増やすことができます。“通信”とは、並列プログラムで必要になるプロセス間通信を設計することを意味します。
“凝集化”とは、パフォーマンスや論理的な抽象化を改善するために、タスクをより大きなタスクにまとめることを意味します。“マッピング”は、タスクをプロセッサに割り当てる処理です。こうしたプロセスの目的は、プロセッサを最大限に活用し、プロセッサ間通信を最小限に抑えるために、計算の負荷と通信の負荷のバランスをとることです。
■並列プログラミング エコシステム
並列プログラミングが目指しているのは、並列コンピューター上で高速に稼動するプログラムの構築です。これらのプログラムは、正確であることに加えて、効果的なライフサイクル管理を実現できるように、最新のソフトウェア エンジニアリング手法に柔軟に対応できる必要があります。以下に、この点を実現する上で重要な要素を挙げます。
- 使用するアルゴリズム
- 実装言語とインターフェイス
- プログラミング環境とツール
- 対象となる並列コンピューティング プラットフォーム
並列アルゴリズムの設計については、多数の書籍が出版されています(参考資料の [Akl, 1989]、[Leighton, 1992]、[Miller, 2005] を参照)。どの書籍でも、並列で実行できる逐次部分を特定し、それらの結果を効果的に結合するという基本的なアプローチが紹介されています。
並列プログラムの開発ツールは、4 つの異なるアプローチに基づいています。まず、コンパイラを拡張する手法です。次に、逐次プログラミング言語を拡張し、既知の環境からコアの並列プログラミング スキームを取り込めるようにする手法です。3 つ目として、並列プログラミング レイヤーを追加する手法があります。このレイヤーは、プロセスの生成と同期、およびデータの分割を制御する逐次コア上にあります。4 つ目の手法は、Fortran 90、High Performance Fortran *17、C* *18 などの新しい並列プログラミング言語を作成する方法です。この記事では、より一般的な 2 つのアプローチ、つまり C++ の拡張版である OpenMP と、MPI(Message-Passing Interface)*19 について検討します。
| *17 High Performance Fortran は Fortran 90 をベースにしており、1993 年に米国ライス大学で開発されました。 |
| *18 C* は、C の並列バージョンで、1992 年にコネクション マシン向けに開発されました。 |
| *19 Microsoft Visual C++ には OpenMP 拡張が含まれています。Microsoft Windows HPC Server 2008 および Microsoft Windows Compute Cluster Server 2003(CCS)SDK には MPI(MPICH2)が含まれています。Visual Studio 統合開発環境は、OpenMP C++ および Microsoft MPI の両方と統合できます。 |
■OpenMP
OpenMP は、共有メモリ モデルに基づいています。共有メモリ プログラムで標準的な並列処理は、fork/join です。プログラムが実行を開始すると、単一のスレッド(マスター スレッド)のみがアクティブになります。マスター スレッドは、アルゴリズムの逐次部分を実行します。並列処理が必要になると、マスター スレッドは別のスレッドに分岐します(別のスレッドを生成、または再開します)。次に、マスター スレッドとそれらの新しいスレッドは、並列部分で同時実行されます。並列コードが終わると、作成されたスレッドは終了または一時中断し、制御フローが単一のマスター スレッドに戻ります。
逐次プログラムは、fork/join を含まない、特殊なタイプの共有メモリ並列プログラムです。共有メモリ モデルは、インクリメンタルな並列化をサポートしており、一度に 1 つのコード ブロックずつ、逐次プログラムから並列プログラムに変換できます。これは、既存のプログラムから、手っ取り早く並列プログラムを開発する場合に便利です。ただし、基本となるアルゴリズムは、必ずしも並列アルゴリズムに最適なものではありません。
OpenMP では、for ループの繰り返し処理を並列で実行する部分を簡単に指定できます。以下のコード スニペットで、2 番目にコメント アウトされた行を参照してください。
#pragma omp parallel private( t, x,y,local_count) |
OpenMP の#pragma omp parallel for 宣言は、C++ コンパイラに対して、波かっこで囲まれた部分を並列実行で処理するように指示しています。また、共有メモリの競合を抑えるために各スレッド専用のパラメーターを定義できていること、さらには pragma を使用したクリティカル セグメントが使用されていることにも注目してください。
前述の例では、プライベート変数が並列の pragma 宣言句によって宣言されています。これにより、すべてのスレッドがこれらの変数(かっこ内)にアクセスする際に、競合を避けることができます。クリティカル セグメントが使用されており、スレッドの結果を、共有変数 count への値に再度追加できるようになっている点にも注目してください。
■MPI(Message-Passing Interface)
MPI は、FORTRAN、C、C++ から利用可能な標準のプログラミング ライブラリです。MPI により、複数の物理コンピューター間で構築できる分散メモリ プログラミング環境を作成できます。MPI には、さまざまなバージョンがあります。たとえば、MPI-2 *20 をベースとする Microsoft MPI や、HP MPI、Intel MPI、Open MPI、LAM/MPI、MPICH、FT-MPI などがあります。
| *20 MPI-2 は、MPI の標準です。 |
プログラミングのアプローチは、分散メモリ並列コンピューター モデルの SPMD がベースになっています。このプログラミングでは、同じプログラムが、参加するすべてのコンピューター(プロセッサ、コア、ノード)上で実行されます。MPI ランタイムでは、並列計算のサポートに必要なサービスを API (Application Programming Interface)から利用できます。通信グループでは、プロセスはランクによって識別されます。プロセス間の通信は 1 対 1 の通信にすることも、複数のプロセス間のコレクティブ通信にすることもできます。
図 5 は、個別のランクを持つ複数のプロセスをホストしている 3 台の物理コンピューターを示しています。
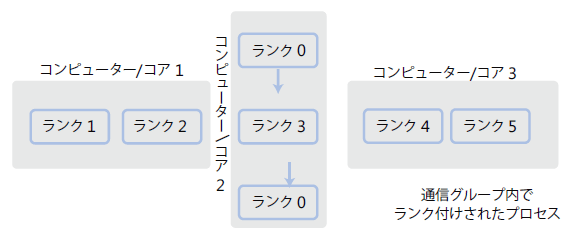 |
| 図 5: 個別のランクを持つ複数のプロセスをホストしている 3 台の物理コンピューター |
コレクション全体で通信グループを形成し、グループに含まれるすべてのプロセスは、メッセージ ベースの通信を介して、互いにアクセスすることができます。
以下のコード スニペットに、単一の MPI プログラムを示します。
#include "mpi.h" |
MPI 関数と定数は、mpi.h ファイルとデータ型で定義されます。演算と定数は、標準 C および FORTRAN のものに似ています。MPI のすべての関数の一覧については、参考資料の [Gropp, 1999] を参照してください。
| INDEX | ||
| [アーキテクチャ・ジャーナル] | ||
| 並列プログラムの開発 | ||
| 1.並列プログラムのパフォーマンス | ||
| 2.並列コンピューティングのプラットフォーム | ||
| 3.並列プログラムの開発 | ||
| 4.次世代のツール | ||
| 「アーキテクチャ・ジャーナル」 |
- 第2回 簡潔なコーディングのために (2017/7/26)
ラムダ式で記述できるメンバの増加、throw式、out変数、タプルなど、C# 7には以前よりもコードを簡潔に記述できるような機能が導入されている - 第1回 Visual Studio Codeデバッグの基礎知識 (2017/7/21)
Node.jsプログラムをデバッグしながら、Visual Studio Codeに統合されているデバッグ機能の基本の「キ」をマスターしよう - 第1回 明瞭なコーディングのために (2017/7/19)
C# 7で追加された新機能の中から、「数値リテラル構文の改善」と「ローカル関数」を紹介する。これらは分かりやすいコードを記述するのに使える - Presentation Translator (2017/7/18)
Presentation TranslatorはPowerPoint用のアドイン。プレゼンテーション時の字幕の付加や、多言語での質疑応答、スライドの翻訳を行える
|
|





