特集:Road to LINQ C#で解説する「データ処理の直交化と汎用化」 岩永 信之2011/06/14 |
 |
|
|
|
■ LINQ to Objectに至るまで
ここまでの説明を聞くと、軸の直交化は当たり前に思えるだろう。しかし、その「当たり前」を阻害するのが「面倒」という気持ちである。軸の直交性は、後からの修正や機能追加を行いたいというときになって初めてそのありがたみが分かる場合が多い。「こういうふうに書けば再利用もできてテストも簡単。後々を考えると楽なのは分かっているが、いまは面倒くさい」という場面に遭遇した場合、その「面倒」という気持ちに勝てるだろうか。
データ処理の軸を分解するには、かつては面倒くさい作業が必要だったのである。C#の機能のいくつかはこの面倒を解消するものであり、LINQはその究極系といってもいいだろう。
それでは、このLINQに至るまでの過程を、順を追って見ていこう。
● 例題
今回、例として作ったのは以下のようなものである。まずは、Figure 2の、取得、加工、表示の3軸で分けている。
- データ「取得」方法
- コンソールからの入力
- 配列
- 連結リスト
- データ「加工」方法
- 奇数だけ取り出してその二乗を計算
- 偶数だけ取り出してその絶対値を計算
- 3以下の数だけ取り出して符号反転
- データ「表示」方法(いずれもコンソールへの出力)
- 1行に1個
- スペース区切り
- コンマ区切り
3軸それぞれ3つずつ、![]() を
を![]() に変える例である。
に変える例である。
○ 出発点: 直交性のない書き方
- メモリの無駄: 1要素ずつしか加工/表示しないのに、全要素分のメモリを余分に確保する。
- 1要素ずつ表示されない: 全要素の加工が完了するまで表示がまったく行われない。
- 匿名メソッドの書き方が違う
- 語順が違う
- 第2回 簡潔なコーディングのために (2017/7/26)
ラムダ式で記述できるメンバの増加、throw式、out変数、タプルなど、C# 7には以前よりもコードを簡潔に記述できるような機能が導入されている - 第1回 Visual Studio Codeデバッグの基礎知識 (2017/7/21)
Node.jsプログラムをデバッグしながら、Visual Studio Codeに統合されているデバッグ機能の基本の「キ」をマスターしよう - 第1回 明瞭なコーディングのために (2017/7/19)
C# 7で追加された新機能の中から、「数値リテラル構文の改善」と「ローカル関数」を紹介する。これらは分かりやすいコードを記述するのに使える - Presentation Translator (2017/7/18)
Presentation TranslatorはPowerPoint用のアドイン。プレゼンテーション時の字幕の付加や、多言語での質疑応答、スライドの翻訳を行える
まずは愚直な実装である。軸の分解はせず、全ての組み合わせを実装している。
List 1に、参考までに2つだけを抜き出したものを示す。このような似て非なるメソッドが![]() 個、並んでいるわけである。
個、並んでいるわけである。
|
|
| List 1 直交性のな実装の例 |
● データ取得の分離
まずはデータ取得を分離してみよう。Figure 6に示すようなメソッドの分割を行うことで、![]() を
を![]() に変える。
に変える。
 |
| Figure 6 データ取得の分離の例 |
○ foreach文の導入
データ取得を分離する方法として、古くからイテレータ(iterator:反復子)パターンというデザイン・パターンが知られている。
C#の場合はデザイン・パターンを特に意識することなく、IEnumerable<T>インターフェイス(System.Collections.Generic名前空間)を実装したクラスはforeach文で列挙可能とだけ覚えればよい*1(「enumerate(列挙)」と「iterate(反復)」は、呼び名こそ違うが同じ概念である)。C# 1.0のころからある機能である。
| *1 実際には、IEnumerable<T>インターフェイスと同じ名前のプロパティとメソッドさえ持っていれば、インターフェイスの実装は不要である。 |
IEnumerable<T>という標準的なインターフェイスを介することで、Figure 7に示すように、加工と表示におけるデータ取得の部分を分離する。
 |
| Figure 7 IEnumerableインターフェイスを介したデータ取得の分離 |
| IEnumerable<T>インターフェイスの実装方法については、ここではあえて伏せる(次節で説明)。 |
foreach文の導入前後を比べてみよう。List 2が導入前、List 3が導入後である。
|
|
| List 2 foreach文の導入前 | |
| データ構造に応じてデータの取得方法が異なっていた。 |
|
|
| List 3 foreach文の導入後 | |
| IEnumerable<T>インターフェイスを介することで、処理が共通化される。 |
○ イテレータ・ブロックの導入
問題は、Figure 7ではあえて伏せている部分、すなわち、IEnumerable<T>インターフェイスの実装方法である。かつては非常に面倒くさかった。
例えば、連結リストを表すListNodeクラスからIEnumerable<T>インターフェイスに関する部分を抜き出すと、List 4のようになる。
|
|
| List 4: ListNodeクラスのIEnumerable<T>インターフェイス実装 |
比較のために、元の(分離していない)コードを再度示すと、List 5のとおりである。いかに面倒になったかが分かるだろう。
|
|
| List 5 ListNodeクラスの列挙のために使うfor文 |
この面倒を解消するために導入されたのがC# 2.0のイテレータ・ブロック(iterator block)だ(単に「イテレータ」と呼ばれる場合もあるが、デザイン・パターンとしてのイテレータと区別するために「イテレータ・ブロック」と呼ぶ)。
イテレータ・ブロックは、List 5に示すようなコードからList 4のようなコードを自動生成する機能である。
|
|
| List 6 イテレータ・ブロックを使ったIEnumerable<T>インターフェイス実装例 |
List 5のfor文をそのまま切り出したような形になっている。foreach文で列挙したい値を、「yield return」という新しい構文を使って返す。
● データ加工を分離
次に、Figure 8に示すように、データ加工を分離してみよう。これでようやく、 ![]() となる。
となる。
 |
| Figure 8 データ加工の分離の例 |
○ 一時リストを作る
先に結論だけいうと、データの加工と表示の分離にもイテレータ・パターンが有効である。もちろん、いまのC#にはイテレータ・ブロックがあるため、これを使わない手はない。しかし、ここではいったん、イテレータ・ブロックがなかったころにありがちだった(あまり良くない)例を見てみよう。
その昔、Figure 7のようなコードを書くことが多かった。一時的なリストを作って、加工結果を格納して返すという方法だ。
|
|
| List 7 一時的なリストを作ってデータを加工する例 |
一時的なリストを使う方法には、以下のような問題がある。
特に、データ取得をコンソール入力から行う場合に問題になる。
コンソール入力では、1行入力するたびにその加工結果を表示してほしいが、この方法では全ての入力を終えるまで一切表示が行われない。しかも、コンソール入力の場合には終わりがいつになるか分からないのである。もしかすると、プログラムの生存期間中ずっと入力し続けるかもしれない(=実質的に、データに終わりがない)。この場合、表示は一切されないことになる。
○ データ加工もイテレータ・ブロック
一時的なリストを使う方法の問題点は、イテレータ・ブロックを使うことで、いとも簡単に解決できる。List 8のように書くだけだ。
|
|
| List 8 イテレータ・ブロックを使ってデータを加工する例 |
List 7と比べると、リストに「Add」(要素の追加)していた部分を「yield return」に変えるだけである。これで、ちゃんと1要素ずつ加工される(メモリの無駄もなく、終わりのないデータにも対応可能である)。
● 加工をさらに直行分解、汎用化
これまでは、Figure 2の軸(データの取得、加工、表示)を基に直交化してきた。次に、もう1歩進めて、Figure 3のように、加工をさらに直行分解してみよう。
例えば、List 8はさらに、List 9のように分割できるだろう。
|
|
| List 9 データ加工をさらに選択と変換に分解する例 |
ここで、List 9で背景色を変えて強調した部分に注目してほしい。Figure 9に示すように、この強調した部分を差し替えられれば、汎用的な選択処理/変換処理が行えるのである。
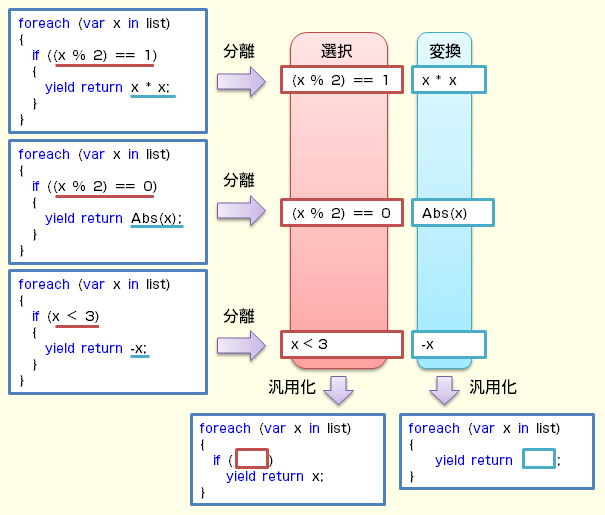 |
| Figure 9 選択と変換の汎用化 |
こういう場合、デリゲートを引数として渡せばよい。結果的に、List 10に示すようなコードになるだろう。
|
|
| List 10 汎用的な選択処理/変換処理 |
これがいわばLINQの原型となる。「LINQ in C# 2.0」と呼べるだろう。すなわち、LINQの本質は、データ処理の(特に加工の)直交化と汎用化なのである。
○ ラムダ式と拡張メソッド
LINQ(正確にはLINQ to Object)に類するものはC# 2.0でも作れたのである。しかし、「面倒くさい」を解消するためにはまだ課題があった。
データ加工を行うコードをC# 2.0と3.0で比べてみよう。
List 11がC# 2.0での書き方、List 12がC# 3.0のものである。いずれも、「奇数だけ取り出してその二乗を計算」である。
|
|
| List 11 LINQ in C# 2.0の例 |
|
|
| List 12 List 11をC# 3.0で書き直したもの |
違いは2点ある。
C# 2.0では、匿名メソッドの書き方が面倒だったのである。前述のとおり、「面倒くさい」は「当たり前にやるべきこと」を阻害する。そこでC# 3.0で導入されたのが、ラムダ式という簡素な書き方である。List 12のように、「=>」(=「goes to(=「〜が〜になる」という意味)演算子」と呼ぶ)を使うことで簡潔に匿名メソッドが作れる。
もう1つの語順の変化だが、これはFigure 10に示すような、入れ子型からパイプライン型への変化を生む。データ処理はパイプライン的に行うべきものなのだが、C# 2.0では文法上の制約から、どうしても入れ子型な書き方になってしまっていた。この問題を解消するために導入されたのが、C# 3.0の拡張メソッドである。
 |
| Figure 10 入れ子型からパイプライン型への変化 |
○ LINQ
これで、Whereメソッド(選択)とSelectメソッド(変換)だけだが、LINQと同じものを実装したことになる。もちろん、解説という意図がなければ、わざわざ自作する必要のないものだ。
最後に、参考までに、標準のLINQに置き換えてみよう。自作したメソッドを消して、System.Linq名前空間をusing宣言するだけである。
続いて次のページでは、LINQ to SQLやLINQ to Entitiesなど、さまざまなLINQについて説明する。
| INDEX | ||
| 特集:Road to LINQ | ||
| C#で解説する「データ処理の直交化と汎用化」 | ||
| 1.直交性 | ||
| 2.LINQ to Objectに至るまで | ||
| 3.LINQ to ……/クエリ式 | ||
|
|
- - PR -
注目のテーマ





