
樋口研究室
2001/5/2
| ローカルBeanとリモートBeanの共通部分 |
これまではローカルBeanとリモートBeanの異なる特徴を紹介してきました。しかしBeanというものがいろいろな外部プログラムから共有して使えるということは、実はこの2つのBeanで共通に持っている部分もあるということです。それはおのおののBeanの中のプログラムを見れば分かります。
これから出てくるプログラムは、Beanの特徴を解説するためのプログラムです。ですからそれほど難しい内容ではありませんし、内容をすべて理解する必要もありません。連載の回数をすすめるに従って、徐々に本来のBeanの使い方や特徴を理解できるようになります。ですからここでは、なるほどこんな感じでBeanはできているんだな、というイメージをつかんでください。
ローカルBeanとリモートBeanで共通に持つ部分、それがプロパティと業務メソッドというものです。
(1)業務メソッドとは?
Beanは業務処理を行うメソッドを持っていないといけません。そうでないとBeanは業務処理を行うことができない部品になってしまうからです。ただこの記事をこれから連載していくときに出てくる内容ですが、Beanをデータの保管庫だけに使う方法があります。このメリットについては、また回をすすめる中でお話ししましょう。
(2)Beanのプロパティとは?
Beanというのは、外部プログラムから使われることが前提となっています。そのためBeanには、外部プログラムから引数をもらったり、結果を外部プログラムに返したりする専用の変数領域を持つ必要があります。
Javaではこういう変数領域のことをインスタンス変数といいますが、これがBeanで使われると、この変数領域のことをプロパティと呼ぶようになります。
Beanのプロパティに外部プログラムが値を設定したり参照するときに注意が必要なのは、外部プログラムは直接Beanのプロパティを操作してはいけないということです。外部プログラムは、Beanのプロパティを参照したり設定したりするときは、プロパティを操作するために作成された決まったメソッドを使わないといけないことがBeanで決められています。
このプロパティ操作専用メソッドのことをgetter(ゲッター:プロパティの値を参照するメソッド)とかsetter(セッター:プロパティの値を設定するメソッド)といいます。これらのメソッドをまとめてアクセッサなどと呼んだりすることもあります。アクセッサは、必ずプロパティ(インスタンス変数)の前にsetやgetの接頭語を付けて作ることになっています。例えば以下のアクセッサの例を見てください。
・KEYというプロパティに値を設定するときに使うアクセッサ・メソッドと使い方
setKEY("12345");
・RESULTSというプロパティから値を参照するときに使うアクセッサ・メソッドと使い方
getRESULTS();
さてここまでBeanの基礎的な内容を確認したところで、以上の共通点を持った具体的なBeanを紹介しましょう。
以下のリスト1が業務メソッド。リスト2がアクセッサの個所です。この2つのリストには、executeと名付けられた業務メソッドとDB、TABLE、KEYという外部プログラムとのやりとりを行うためのプロパティ、そのアクセッサがあります。
| リスト1 業務ロジックの部分 |
1:public void execute(){
|
| 1行目:業務処理の部分を表すexecuteメソッドの始まりです。executeというのは筆者の付けたメソッドの名前で、特にこのように決められているわけではありません。皆さんの好きなようにメソッド名を付けても構いません。 2〜4行目:業務処理の一番最初に、プロパティに設定された検索対象となるDB名、テーブル名、キーを取り込みます。これらの内容は、このexecuteメソッドが呼び出される前に外部プログラムがアクセッサを使って設定していることが前提です。プロパティの値を参照するときは、プロパティ名の前にgetを付けたアクセッサ・メソッドを使って参照します。 7〜8行目:JDBCドライバのインスタンス化を行います。ここではIBM社のUniversal DataBaseのJDBCドライバを使用しています。 9〜11行目:JDBC接続では、規約で決められたDB名を指定して接続を行います。接続が完了すると接続したDBを表す接続オブジェクトが取得できます。ちなみにDB名として「empdb」を使うなら、JDBCの規約に従えば"jdbc:db2:empdb"となるわけです。またセキュリティに必要なユーザーIDとパスワードも必要です。 12〜15行目:12行目でプログラムでSQLステートメントを発行する準備のために、ステートメント・オブジェクトのインスタンス化を行います。次の13行目で検索のためのselectステートメントを発行します。SQLが実行されたら、その結果がResultSetという検索結果を格納するオブジェクトに入ります。 17行目:すべての検索結果をいったん格納するためにVectorオブジェクトを作ります。そうするとヒットした数を知ることができます。 18行目:ResultSetオブジェクトの中の検索結果をnextメソッドを使用して順番に参照します。 19〜26行目:検索するテーブルの1レコードは8個の列で構成されています。それらを文字オブジェクトに格納します。 27〜28行目:1レコード分の検索結果をVectorの中へ格納します。 30〜31行目:実行したSQLとDB接続に使用したインスタンスをクローズします。 33〜37行目:検索した結果を結果保存用のプロパティ(RESULTプロパティ)に保管します。33行目はVectorに格納されたレコード数を調査して総ヒット数を算出します。 34行目はプロパティの配列に総ヒット数の数を割り当てます。36行目はループ処理でVectorに保存されたすべてのレコードを配列プロパティに格納します。このようにしておくと、あとでこのプロパティを参照すればすべての検索結果を知ることができます。プロパティへの設定はsetプロパティ名のメソッドを使用します。 |
| リスト2 アクセッサの部分 |
1:public void setDB(String
val) {DB = val;}
|
| 1〜2行目:DBプロパティに関するsetterとgetter(設定と照会)メソッドを記述します。1行目はDBの値を設定するメソッドですが、その記述はインスタンス変数として定義されているDB変数をリターンしているだけです。2行目はDBの値を参照するメソッドです。設定メソッドは何らかの値をインスタンス変数に格納するだけなので、格納する値を引数として持つメソッドとして作成します。メソッドでは引数として入ってきた内容をインスタンス変数のDB変数に格納します。 3〜4行目:ここはTABLEプロパティに関するsetterとgetterメソッドを記述します。 5〜6行目:ここはKEYプロパティに関するsetterとgetterメソッドを記述します。 7〜10行目:ここはRESULTプロパティに関するsetterとgetterメソッドを記述します。RESULTプロパティは配列型です。なぜなら検索結果が1つではなく複数の場合があるので、配列にしておく方が都合がいいからです。この場合、配列のすべての内容を操作するsetter/getterメソッドと、配列を1つ1つを個別操作するsetter/getterメソッドを用意するのが便利です。7行目は配列全体を設定するメソッド、8行目は配列を個別に設定するメソッド、 9行目は配列全体を取得するメソッド、10行目は配列に個別に値を参照するメソッドです。 |
| ローカルもリモートも業務ロジックは同じ |
さていろいろと説明してきたところで注意しないといけないのは、これだけのJavaコードだけでは、まだ完全なリモートBeanやローカルBeanではないということです。なぜなら上記のリスト1やリスト2はローカルBeanとリモートBeanで共通に使える部分だけを抜き出したにすぎないからです。ではローカルBeanとリモートBeanの違いはどこで出てくるかというと、上記の共通の部分に、それぞれローカル環境で動くように特化した部分とリモート環境で動くように特化した部分を付け加えて、初めてローカルBeanとリモートBeanになります。
ここでBeanを作成する皆さんにとって重要な考え方があります。それは業務処理がローカル環境で稼働しても、あるいはリモート環境で稼働しても、実は稼働する業務処理には変化はないという考え方です。
この考え方をうまく応用することで、上記のリストで作成した業務メソッドやアクセッサが、リモートBeanでもローカルBeanでも、すなわちJavaBenasでもEJBでも、まったく中身のコードを変更することなく動かすことができます。この考え方が、もともと最初にお話しした部品の考え方ですね。
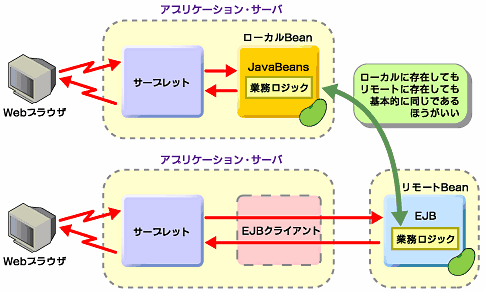 |
| 図11 ローカルもリモートも業務ロジックは同じ |
さて、今回のお話はちょっとページ数も多くなったようです。次回のスマートなサーバ・サイドJavaでは、このリストのコードをそっくりそのまま変更せずに、ローカル環境に対応したり、リモート環境に対応させるBeanにするノウハウをお話しすることにしたいと思います。
|
|
4/4 |
| 連載記事一覧 |
- 実運用の障害対応時間比較に見る、ログ管理基盤の効果 (2017/5/9)
ログ基盤の構築方法や利用方法、実際の案件で使ったときの事例などを紹介する連載。今回は、実案件を事例とし、ログ管理基盤の有用性を、障害対応時間比較も交えて紹介 - Chatwork、LINE、Netflixが進めるリアクティブシステムとは何か (2017/4/27)
「リアクティブ」に関連する幾つかの用語について解説し、リアクティブシステムを実現するためのライブラリを紹介します - Fluentd+Elasticsearch+Kibanaで作るログ基盤の概要と構築方法 (2017/4/6)
ログ基盤を実現するFluentd+Elasticsearch+Kibanaについて、構築方法や利用方法、実際の案件で使ったときの事例などを紹介する連載。初回は、ログ基盤の構築、利用方法について - プログラミングとビルド、Androidアプリ開発、Javaの基礎知識 (2017/4/3)
初心者が、Java言語を使ったAndroidのスマホアプリ開発を通じてプログラミングとは何かを学ぶ連載。初回は、プログラミングとビルド、Androidアプリ開発、Javaに関する基礎知識を解説する。
|
|





