dolipoの種明かし
drikin2008/8/19
![]() Polipo技術解説
Polipo技術解説
dolipoは、PolipoというオープンソースのプロキシプログラムにGUIを追加したプログラムです。
Polipoは、フランス人のJuliusz Chroboczek氏が主体となって開発されています。
Polipoがどのような原理でネットワークを加速しているのか、少し技術的な解説をしてみたいと思います。
といっても、僕もPolipo自体の開発にはかかわっていません。あくまでも、公式ページやdolipo解説サイトなどの解説からひもといた内容です。
プロキシによるネットワークの高速化は、Polipoがはじめてというわけではありません。そもそも、多くのプロキシプログラムには、データをキャッシュしてデータの転送を効率化して高速化する機能が備わっています。
Polipoが興味深いのは単なるデータキャッシュだけでなく、さらに積極的にネットワークを高速化させるため、いくつかの意欲的な機能を実装していることです。Polipoの公式ページによると、4つの高速化のための仕組みが導入されていることが記述されています。
- 接続先のサーバが対応している場合、できる限りHTTP/1.1のパイプライン機能を利用する。
- データのダウンロード時に、データを部分的にキャッシュして、中断されたらそこから再開する。
- クライアントがHTTP/1.0でリクエストした場合、PolipoがHTTP/1.1に変換しサーバにリクエストし、必要であれば再度HTTP/1.0に戻してクライアントに伝える。
- サーバの遅延をさらに軽減させるために、Poor Man's Multiplexingと呼ぶテクニックを利用することもできる(オプション)。
それぞれの詳細について、Polipoのホームページの解説などを参考にしながら、もう少し説明していきましょう。
![]() 反応の遅いデータはすっとばせ!
反応の遅いデータはすっとばせ!
(1)接続先のサーバが対応している場合、できる限りHTTP/1.1のパイプライン機能を利用する。
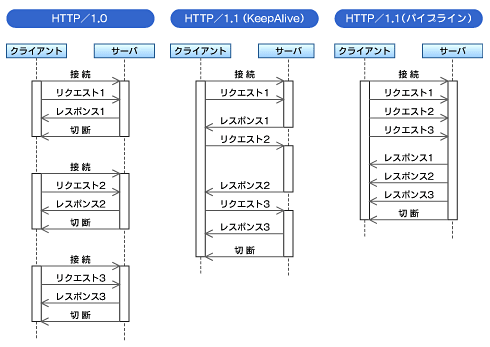 |
図6 HTTPによるデータ取得シーケンス概念図 |
パイプライン機能について説明する前に、初心に戻ってHTTPプロトコルについて少しおさらいします。HTTPプロトコルは、そもそも、リクエストとレスポンスが対となるステートレス(状態を維持しない)なプロトコルです。
今時の一般的なWebページは、画像やCSS、JavaScriptファイルなど多数のファイルから構成されています。
HTTP/1.0では、リクエストごとにサーバへのTCP接続を確立してデータを取得するので、1つの Webページにたくさんのファイルがリンクされていると、1つ1つのファイルを取得するごとにサーバへの接続・切断を繰り返しながらデータを転送していました。
また、RFC 2616では、1つのサーバへの同時接続は2つまでが推奨されています。RFCはあくまでも推奨なので、この同時接続数を増やしてブラウザを高速化する裏技をいまだによく見掛けることがあります。
現在主流のHTTP/1.1では、Keep Aliveという機能が追加され、HTTP/1.1に対応したサーバでは、サーバとの接続を維持したまま複数のファイルを取得することができるようになりました。
Keep Aliveはサーバへの接続・切断コストを減少させるもので、それだけでも効果は大きいのですが、あくまでも、1つのコネクションに対してリクエストは、1つずつ処理されていきます。
1つ1つファイルを取得している途中で、レスポンスの遅いデータが存在すると、そのレスポンスが終わるまで次のリクエストは待たされることになります。
パイプライン機能は、さらにサーバとの転送効率を良くするために、1つのリクエストのレスポンスを待たずに次のリクエストを連続的に発行するという機能です。これにより、データの転送効率も向上し、ネットワーク上のトラフィックを軽減する効果も得られます。
図6に HTTP/1.0、HTTP/1.1(Keep Alive)、HTTP/1.1(パイプライン)それぞれにて、3つのデータを受信するときのシーケンスの概念図を描いてみました。実際にはこんなに単純な話ではありませんが、Keep Alive、パイプラインの有用性が理解できると思います。
パイプライン機能はHTTP/1.1で定義されているものの、実際のHTTPサーバではパイプライン機能の実装にバグが含まれていることが多く、Firefoxなどのブラウザでもパイプライン機能は実装されていますが設定は隠されていて、デフォルトでは無効にされているのが現状です。
Polipoの公式サイトの解説では、Polipoは接続先のサーバのパイプラインサポートが有効かどうか慎重に調べたうえで、できる限りパイプライン機能を利用するようにプログラムされていると書かれています。
![]() いちからのやり直しでなく、キャッシュを活用しよう
いちからのやり直しでなく、キャッシュを活用しよう
(2)データのダウンロード時に、データを部分的にキャッシュして、中断されたらそこから再開する。
HTTP/1.1 にはRangeという機能もあります。これは、1つのリクエストに含まれるデータの一部分を指定して取得する機能です。
大きなデータを取得中に、突然コネクションが切断されたとき、通常だとデータを一から取得し直しになるのですが、Polipoは部分的なデータをキャッシュしておいて中断された部分から再開することで高速化を図っています。
![]() サーバとクライアントの通訳で転送の効率化を図る
サーバとクライアントの通訳で転送の効率化を図る
(3)クライアントがHTTP/1.0でリクエストした場合、PolipoがHTTP/1.1に変換しサーバにリクエストし、必要であれば再度HTTP/1.0に戻してクライアントに伝える。
これは、ほとんど(1)で解説した内容です。HTTP/1.1は、1.0に比べてデータ転送を効率化するための機能が多数取り入れられています。
しかし、クライアントのリクエストがHTTP/1.0として発行されると、HTTP/1.1の機能が使えなくなってしまうため、Polipoが中継に入ってHTTP/1.0<->HTTP/1.1の変換を行い転送の効率化を図っています。
![]() 1つのコネクション上で複数リクエストを同時に発行してみる
1つのコネクション上で複数リクエストを同時に発行してみる
(4)サーバの遅延をさらに軽減させるために、Poor Man's Multiplexingと呼ぶテクニックを利用することもできる(オプション)
最後に紹介するのがPoor Man's Multiplexing(以下PMM)として紹介されている高速化技術です。この機能は、デフォルトではオフになっています。
これは、Polipoの解説を見ると、どうもパイプライン機能よりさらに積極的にデータを取得するための技術のようです。
パイプライン技術を利用しても、データはあくまでも1つのコネクション上で取得することになります。どこかにボトルネックがあれば、データの遅延は存在してしまいます。
本来であれば、複数のデータは複数のコネクションに分割して取得する方が効率がよいのですが、これも前述のようにRFC 2616で1サーバ2コネクションまで制限され、サーバ負荷の観点から大量のコネクションは推奨できません。そこで、PMM技術を使って、1つのコネクション上で複数リクエストを同時に発行しようという試みのようです。
また、Rangeリクエストを併用して、データを分割して取得することも行っているようです。画像データなどは、先頭のヘッダを見ればデータのサイズなどは取得できるので、すべての情報を取得しなくてもブラウザがレンダリングを開始できる効果が得られるようです。
ただ、PMMはパイプライン機能が動作して初めて効果を発揮する機能ですし、本家のWebサイトでも本質的には信頼できないと記載されているので、あまり推奨できる機能ではないようです。
dolipoの場合、PMMの機能を有効にするには、dolipoのメニューバー(図4)のOptionからEnable PMMをチェックしてください。簡単に有効・無効を切り替えられるので、問題が起きたらオフにするという使い方でパフォーマンスの違いを検証してみるのもいいと思います。
| dolipoの種明かし | |
| Page1 少しでもネットワークを高速化したいヨーロッパ圏から学ぶ インターネットを過激に加速するアプリdolipo技術解説 |
|
| Page2 Polipo技術解説 反応の遅いデータはすっとばせ! いちからのやり直しでなく、キャッシュを活用しよう サーバとクライアントの通訳で転送の効率化を図る 1つのコネクション上で複数リクエストを同時に発行してみる |
|
| Page3 dolipo Tips Proxy設定の自動切り替えと除外サーバの設定 adブロックフィルタのカスタマイズ さらなるカスタマイズ ネットワークレイヤの課題に残された可能性 |
|
| 「Master of IP Network総合インデックス」 |
- 完全HTTPS化のメリットと極意を大規模Webサービス――ピクシブ、クックパッド、ヤフーの事例から探る (2017/7/13)
2017年6月21日、ピクシブのオフィスで、同社主催の「大規模HTTPS導入Night」が開催された。大規模Webサービスで完全HTTPS化を行うに当たっての技術的、および非技術的な悩みや成果をテーマに、ヤフー、クックパッド、ピクシブの3社が、それぞれの事例について語り合った - ソラコムは、あなたの気が付かないうちに、少しずつ「次」へ進んでいる (2017/7/6)
ソラコムは、「トランスポート技術への非依存」度を高めている。当初はIoT用格安SIMというイメージもあったが、徐々に脱皮しようとしている。パブリッククラウドと同様、付加サービスでユーザーをつかんでいるからだ - Cisco SystemsのIntent-based Networkingは、どうネットワークエンジニアの仕事を変えるか (2017/7/4)
Cisco Systemsは2017年6月、同社イベントCisco Live 2017で、「THE NETWORK. INTUITIVE.」あるいは「Intent-based Networking」といった言葉を使い、ネットワークの構築・運用、そしてネットワークエンジニアの仕事を変えていくと説明した。これはどういうことなのだろうか - ifconfig 〜(IP)ネットワーク環境の確認/設定を行う (2017/7/3)
ifconfigは、LinuxやmacOSなど、主にUNIX系OSで用いるネットワーク環境の状態確認、設定のためのコマンドだ。IPアドレスやサブネットマスク、ブロードキャストアドレスなどの基本的な設定ができる他、イーサネットフレームの最大転送サイズ(MTU)の変更や、VLAN疑似デバイスの作成も可能だ。
|
|
注目のテーマ





