
特集:変貌するリッチクライアント(4)
自由すぎるWebの世界でメタデータは統合できるか
野村総合研究所
技術調査室
田中 達雄
2006/9/8
| 自由すぎるWebの世界で、メタデータ統合の鍵を握る技術は? 複数の美術館に保管されている美術品をワンストップで検索させるフィンランド美術館のセマンティックWeb活用から考えよう |
| データやサービスを統合する基盤、リッチクライアント |
前回の「企業のWeb2.0活用はSOAとの融合から」では、SOA(サービス指向アーキテクチャ)やWeb2.0世界のWebAPIやSaaS(Software as a Service)が、クライアントの独立性を高め、リッチクライアントの普及を後押しすると説明した。
現在、これらのサービスは、サーバ上で統合(マッシュアップ含む)する例が多いが、独立したリッチクライアントであれば、個別のサービスを直接呼び出すことも可能だ。つまり、リッチクライアントは、データやサービスを統合する基盤にもなり得る。
今回は、将来、リッチクライアントがデータやサービスを統合する基盤となったときに足りなくなる技術(セマンティックWeb)について解説する。同時にこれは、いまのサーバ側に足りない技術でもある。
| Web2.0世界でのサービス呼び出し |
まずは、Web2.0世界におけるWebAPIの事例を見てみよう。これらを眺めることでセマンティックWebの必要性がおぼろげながら見えてくるはずだ。
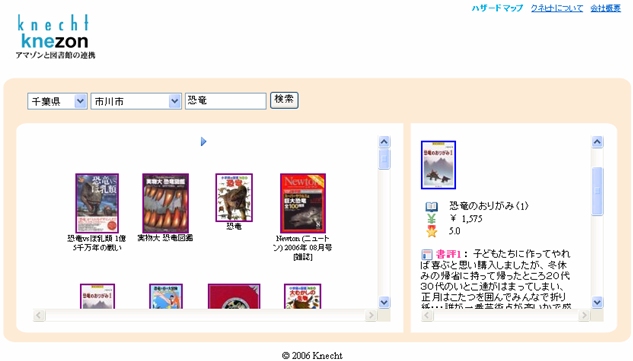 |
| 図1:Knezon 出所)有限会社クネヒト(画像クリックで拡大表示) |
図1は有限会社クネヒトが提供する「knezon(クネゾン)」の画面である。これは全国の図書館(2006年8月9日時点で30都道府県667市町村の図書館)の所蔵データとAmazonの書評をマッシュアップしたサービスである。リッチクライアント技術には、Ajaxが使われている。
このサービスを実現するには、複数の図書館が所蔵している所蔵データを扱わなくてはならないが、現在、図書検索に際しては、スクリプト言語を使い図書館検索用フォームを個別に生成して対応している。
例えば、図2の市川市立図書館の検索用フォーム<FORM>は、あるCGIにPOSTで検索キーワードをリクエストし所蔵リストをレスポンスしている。Knezonでは、この検索用フォーム<FORM>を動的に生成してリクエストしているのだ。もちろんレスポンスとしてKnezon側が受け取るデータはHTMLファイルなので、そこからまたタイトルを抜き出す処理は必要となる。
 |
| 図2:市川市立図書館 出所)市川市立図書館(画像クリックで拡大表示) |
| 既存のデータフォーマットや語彙はバラバラ |
面倒くさがりの筆者からすると、これらの処理の記述(プログラミング)は、やはり面倒なものに思える。全国の図書館で統一されたWebAPIならびにデータフォーマットが存在し、それが使える方がよっぽど効率が良いだろう。しかしそれは難しいことだ。すでに所蔵データベースやWebサイト、図書館システムは個別に構築されており、個別のデータフォーマットが使われている。
図3は、そのことを裏付ける例である。市川市立図書館と白井市立図書館の書籍情報に使われている語彙(ごい)を見ると、それぞれ使われている語彙が異なることがよく分かる。Web上の語彙ではあるが、データベースで使われているデータフォーマットの語彙も異なる可能性が極めて高い。
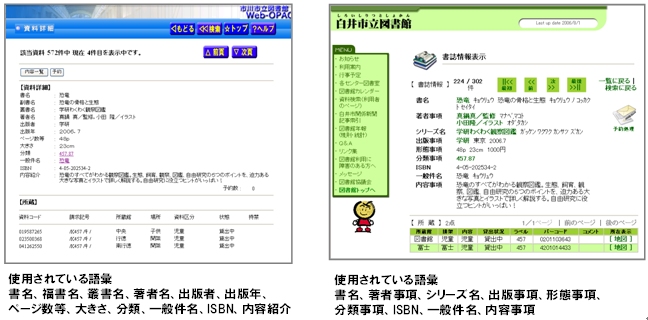 |
| 図3:市川市立図書館と白井市立図書館の書籍情報で使用されている語彙 出所)市川市立図書館、白井市立図書館(画像クリックで拡大表示) |
| 異なるデータフォーマットや語彙を統合させていく仕組みが セマンティックWeb |
仮にXML WebサービスのようなWebAPIを提供してもらったとしても、これだけ語彙がバラバラではデータを一様に扱うことは困難で、やはり面倒な処理をプログラミングする必要が出てきてしまう。
クネヒトのような企業がデータを統合する場合は、多少の手間は優秀なプログラマーがやってのけてしまうだろうが、仮にリッチクライアントがサービス統合の基点となり、利用者が自らサービスを組み合わせるようになった場合には、事情が異なってくる。その場合は、たとえデータフォーマットや語彙が異なっていたとしても容易に統合できる仕組みが必要になる。もちろん企業側でも容易に統合できる方法があればそれを採用したい。
その異なるデータフォーマットや語彙を統合させていく仕組みがセマンティックWebである。セマンティックWebを利用すれば、図書館ごとに存在する異なるデータフォーマットや語彙を許容しながらも、すべての図書館の所蔵データを一様に扱うことを可能にする。類似したセマンティックWeb適用事例に「フィンランド美術館」の事例がある。
| 複数の美術館に保管されている美術品を ワンストップで検索させるフィンランド美術館 |
従来の美術品検索では、美術館ごとにデータフォーマットや使用する語彙、分類方法などが異なるため、個々の美術館が用意する美術品検索システムを使う必要があった。しかしフィンランド美術館では、セマンティックWebを使うことで、複数の美術館に保管されている美術品をワンストップで検索することに成功している。
この事例を単なる検索システムととらえるのではなく、視点を変えてみると、異なる複数の独立したシステムのデータがセマンティックWebを使い統合されていることが分かる。
ここでは、各美術館のデータフォーマットをメタデータ、語彙や分類方法をオントロジーとしてそれぞれRDF(Resource Description Framework)、OWL(Web Ontology Language)で定義し、ソースコードから分離している。仮に検索する美術館を追加する場合もRDFの追加、OWLの変更だけでソースコードの開発/変更は必要としないというわけだ。
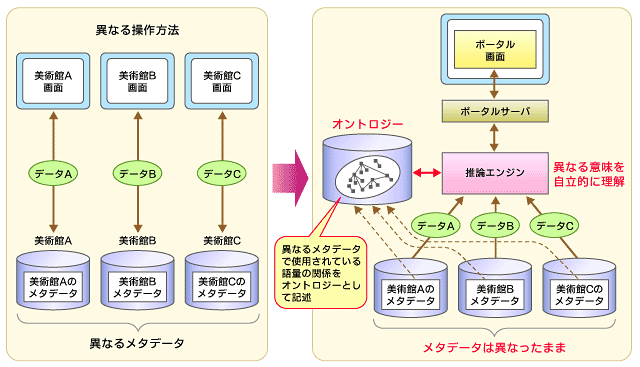 |
| 図4:フィンランド美術館のセマンティックWeb適用事例 出所)野村総合研究所(画像クリックで拡大表示) |
セマンティックWebの標準化動向 現在、セマンティックWebに関する仕様は主にW3C(World Wide Web Consortium)で標準化されている。図5はW3Cで公開されている「セマンティックWebの技術階層」である。 メタデータとはいわゆるデータフォーマットであり、「XML」ならびに「RDF」で定義する。 オントロジーは、ある特定分野の概念や知識であり「RDF Schema」ならびに「OWL(Web Ontology Language)」で定義する。 現在、Rules層以上の標準化作業が進められており、Rules層の標準仕様「SWRL」などは情報リソースの扱いルールだけにとどまらず、ビジネスプロセス上のルールの記述へも応用を広げようとしている。基本的に上位の仕様が加わるにつれて、コンピュータが自律的に処理する範囲が広くなる。つまりコンピュータがより賢くなるのだ。
|

| 1/2 |
|
INDEX |
||
| 自由すぎるWebの世界でメタデータは統合できるか | ||
| Page1<データやサービスを統合する基盤、リッチクライアント> Web2.0世界でのサービス呼び出し/既存のデータフォーマットや語彙はバラバラ/異なるデータフォーマットや語彙を統合させていく仕組みがセマンティックWeb/複数の美術館に保管されている美術品をワンストップで検索させるフィンランド美術館/セマンティックWebの標準化動向 |
||
| Page2<MicroformatsにもセマンティックWebが必要に>
SOA普及後のセマンティックWeb/セマンティックWebはとっつきにくい技術であるが |
||
- GASで棒、円、折れ線など各種グラフを作成、変更、削除するための基本 (2017/7/12)
資料を作る際に、「グラフ」は必要不可欠な存在だ。今回は、「グラフの新規作成」「グラフの変更」「グラフの削除」について解説する - GET/POSTでフォームから送信された値をPHPで受け取る「定義済みの変数」【更新】 (2017/7/10)
HTMLのフォーム機能についておさらいし、get/postメソッドなどの内容を連想配列で格納するPHPの「定義済みの変数」の中身や、フォーム送信値の取り扱いにおける注意点について解説します【PHP 7.1含め2017年の情報に合うように更新】 - PHPのfor文&ループ脱出のbreak/スキップのcontinue【更新】 (2017/6/26)
素数判定のロジックからbreak文やcontinue文の利点と使い方を解説。for文を使ったループ処理の基本とwhile文との違い、無限ループなども併せて紹介します【PHP 7.1含め2017年の情報に合うように更新】 - Spreadsheetデータの選択、削除、挿入、コピー、移動、ソート (2017/6/12)
Spreadsheetデータの選択、挿入、削除、コピー、移動、ソートに使うメソッドの使い方などを解説する
|
|





