
連載 DB2でXMLを操作する(6)
XML Collectionでデータマッピングを実現
| XMLの普及とともにリレーショナルデータベースにもXMLを格納できる機能が搭載されてきている。しかしその機能は、製品ごとに固有のものだ。この記事では、IBMの製品であるDB2
UDBでどのようにXMLを扱うか、について解説する。 たがわ製作所 2003/8/30 |
| 今回の主な内容 |
前回は、DB2でXMLを取り扱うための手段であるXML Collectionの利用手順について概説しました(もう1つの手段はXML Columnです。連載(3)、連載(4)参照)。今回はXML Collectionのサンプルを取り上げ、その具体的な利用例を解説してみたいと思います。併せて、XML Collectionを用いたXML文書の合成および分解の実例についても解説してみます。
XML Collectionは、階層関係にあるテーブルの組(コレクション)をXMLの文書と対応付けるための仕組みでした。1対多の参照関係にあるようなテーブルの組であれば、およそ何であれXML Collectionで利用することができます。日ごろから業務でリレーショナルデータモデルを設計されている方であれば、そのような例の1つや2つはすぐに思いつかれることでしょう。例えば、「注文」と「注文明細」のような2つのデータのエンティティの関係がそうです。
ここでは既存のテーブルをXML Collectionで活用してみましょう。以前、DB2をインストールした際にサンプルデータベースを作成しました。このデータベースには、サンプルとして利用できるテーブルおよびデータが含まれています。ここではこのサンプルデータベースに作成されているDEPARTMENTとEMPLOYEEという、2つのテーブルを取り上げたいと思います。
DEPARTMENTとEMPLOYEEは、それぞれ(会社組織における)部門と従業員のいわゆる「マスターデータ」表に相当し、図1のようなカラムを持っています。
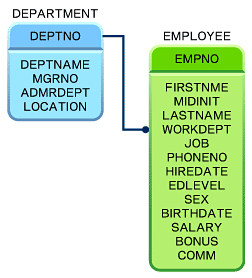 |
| 図1 DEPARTMENT表とEMPLOYEE表の概要 |
見れば分かるように、DEPARTMENT表およびEMPLOYEE表の主キーはそれぞれDEPTNOおよびEMPNOであり、EMPLOYEE表の外部キーWORKDEPTによりDEPARTMENT表の主キーを参照している1対多の関係になっています。
この2つのテーブルをコレクションとして用い、どのようなXML文書に対応付けたらよいでしょうか? 実際の例で説明してみましょう。いま、DEPARTMENT表とEMPLOYEE表に、それぞれ図2に示すようなデータが含まれていると仮定してください。
 |
| 図2 DEPARTMENT表およびEMPLOYEE表に含まれるデータのサンプル |
このようなデータに基づき、リスト1のようなXML文書を作成してみましょう。
<?xml version="1.0"?> |
| リスト1 DEPARTMENT表とEMPLOYEE表から合成するXML文書のサンプル |
前回の記事と突き合わせれば分かるように、DEPARTMENT表の各行について、リスト1のようなXML文書が対応する形になります。前回紹介した、基本的なパターン(前回のリスト1)とも見比べてください。
<?xml version="1.0"?>
</A> |
|||
| 前回紹介したリスト1(再掲) | |||
取り上げるサンプルが決まったところで、早速、作業に取り掛かることにしましょう。
(1)設計作業の概要
XML Collectionを利用するに当たり、以下のような設計作業をする必要がありました。
- コレクションの検討
- XML文書の検討
- コレクションの指定方法の選定
- 文書型の検証の有無
以下でこれらの設計作業について1つ1つ見ていきます。
(2)コレクションの検討
最初にコレクションとして用いるテーブルをどれにするか検討します。今回は図1を見てお分かりのように、DEPARTMENT表およびEMPLOYEE表の組をコレクションとして利用します。
(3)XML文書の検討
コレクションをどのような文書型のXML文書と対応付けるかについては、リスト1のサンプルを見ていただいたとおりです。もう少し詳しく見ておきましょう。
●どのカラムをXML文書に含めるのか
XML文書の中の要素もしくは属性として対応付けるカラムは、それぞれ以下のようになっています。
| XML文書と対応付けるカラム | ||||||
|
サンプルなので、ここではどのようなカラムを選択しても構いません。今回は、データの格納にも用いる予定なので、NOT NULL制約のあるカラムをすべて選択してあります。
●カラムを属性もしくは要素のいずれの形式で取り出すのか
カラムのデータは基本的に要素としてXML文書に含めることにします。主キーであるDEPTNOおよびEMPNOについては、XML文書内でもIDとして利用することができそうです。これらのカラムは属性としてXML文書に含めることにします。
●属性もしくは要素の名前
属性もしくは要素の名前は基本的にカラムと同じにしておきます。ただし、ADMRDEPTはADMINDEPTに、EMPLOYEE表の名前に関する3つのカラムについては、それぞれFIRST、MIDDLE、LASTと表記したうえでNAMEタグで囲っておくことにしましょう。
(4)コレクションの指定方法の選定
コレクションの指定方法としては、SQL Mappingおよび、RDB_Node Mappingの2種類のいずれかを選びます。それぞれの使い分けについては前回簡単に触れましたが、再度まとめておきます。
- 合成のみしか行わないのであればSQL Mapping
- 分解も行う、あるいは簡単な条件しか指定しないのならRDB_Node Mapping
今回はサンプルということで、SQL MappingとRDB_Node Mappingの両方の例をお見せします。
(5)文書型の検証の有無
せっかくですから、文書型の検証も行うことにします。DTDが必要になるので、リスト1のXML文書を参考に作成してみました(リスト2)。
<!ELEMENT department (deptname,
admindept, (employee)*)> |
| リスト2 合成するXML文書のDTD |
(1)実装作業の概要
設計作業が終わったら、以下のような流れで実装作業を進めます。
- DADファイルの定義
- XMLエクステンダーの有効化
- DTDの登録
- XML Collectionの有効化
以下でこれらの実装作業について1つ1つ見ていきます。
(2)DADファイルの定義(SQL Mapping)
DADファイルの定義については、SQL MappingおよびRDB_Node Mappingの2種類について作成しますが、最初はSQL MappingのDADファイルから定義していきます。詳しい解説は後にして、まずは実際のDADファイルから見ていきましょう(リスト3)。
<?xml version="1.0" ?>
|
| リスト3 SQL Mappingを用いるためのDADファイル(sql_mapping.dad) |
●<dtdid>および<validation>
XML Columnの場合と同じですので説明は不要かと思いますが、これらはDTDの検証を行うかどうか、行うとしたらどのDTDを用いるのか、について指定するものです。今回はdepartment.dtdという名前のDTDを用いて検証を行います。
●<SQL_stmt>
コレクションに含まれるテーブルを指定するためのSQLを指定します。 前回説明した以下の規則に従って、SQLが記述されていることを確認してみてください。- ORDER BY句は必須。各テーブルのプライマリキーを階層構造と対応する順に並べる
- その順に合わせて各テーブルのカラムをグルーピングしてSELECT句に並べる
- WHERE句では各テーブルを結合するための条件を必ず指定する
●<prolog>
XML文書の先頭に記述されるXML宣言の内容を指定します。ここではオーソドックスに、<?xml version="1.0"?>というXML宣言を出力するだけのものになっています。
●<root_node>以下
実際に合成するXML文書の構造を指定します。前回も解説したように、<element_node>、<attribute_node>および<text_node>のタグを用いて出力する文書の構造を記述しています。この記述を見ただけでは、出力される文書の実際の形がなかなか分からないと思いますので、ぜひリスト1のサンプルと見比べてください。これらの要素および属性の値として、実際に出力するカラムの値は<column>により指定されています。各要素および属性の値として、どのカラムの値を出力しているかリスト1と見比べながら確認してみてください。
(3)DADファイルの定義(RDB_Node Mapping)
次はRDB_Node Mappingを用いるためのDADファイルを定義します。こちらもまずは実際のDADファイルを見てください(リスト4)。
<?xml version="1.0" ?> |
| リスト4 RDB_Node Mappingを用いるためのDADファイル(rdb_node_mapping.dad) |
検証の有無、prologコードの指定方法についてはSQL Mappingと特に違いはありません。また、<root_node>タグの中で、<element_node>や<attribute_node>タグを用いて文書の構造を指定するところも基本は同じです。違う点は、コレクションの指定およびカラムの指定のために<RDB_node>タグを用いるところです。
●コレクションの指定
ルートの要素を指定する<element_node>タグの直後で、コレクションに含まれるテーブルを指定する必要があります。テーブルの指定にはリスト5のように<RDB_Node>タグを用います。
<root_node> |
| リスト5 RDB_Node Mappingにおけるコレクションの指定 |
各テーブルを<table>タグで指定し、これらのテーブルを結合するための条件を<condition>タグで指定します。
●カラムの指定
要素や属性の値を指定するために<column>タグを用いる点はSQL Mappingの場合と同じです。ただし、どのテーブルに含まれるどのカラムなのかを指定する必要があります。テーブルを指定するにはリスト6のように<RDB_Node>タグを用います。
・ |
| リスト6 RDB_Node Mappingにおけるカラムの指定 |
合成する場合はリスト6のような指定だけで十分です。分解を行う場合は、さらに各カラムの型を指定しておく必要があります。カラムの型はリスト7のように<column>タグのtype属性を用いて指定します。
・ |
| リスト7 型指定を加えたカラムの指定 |
VARCHARやDECIMALなどのカラムは、正しくけた数を指定する必要があるので注意してください。
(4)XMLエクステンダーの有効化
XMLエクステンダーの有効化の作業は、XML Columnを用いる場合と同じです。DB2がC:\Program Files\IBM\sqllibにインストールされているという前提での実行例を図3に示しておきます。
|
|
| 図3 データベースの有効化の実行例 |

有効化済みのデータベースに対して再度の有効化作業は不要です。
(5)DTDの登録
DTDの登録作業もXML Columnの場合と同じです。
|
|
| (本来は1行です) |
ここで、今回利用する各種のサンプルファイルは、C:\sampleというディレクトリにあると仮定しています。
(6)XML Collectionの有効化
最後にXML Collectionの有効化を行います。今回は2つのDADファイルを用意しているので、それぞれを別々のコレクション、department1およびdepartment2として登録しておきます。
|
|
| (本来は1行です) |
|
|
| (本来は1行です) |
さぁ、これでXML Collectionを利用する準備が完了しました。
| ■コラム DADを簡単に記述しよう |
|
この連載をここまでお読みになった方ならお分かりかと思いますが、XMLエクステンダーを利用する際の中心となる作業はDADの記述です。ところがこのDADの記述を実際に手作業で行ってみるとなかなか大変なものです。特にXML Collectionを利用する場合のマッピングの指定がかなり面倒なのはいうまでもなく、間違いを探すためのデバッグもひと苦労です。 ここで強力な味方となるのが、IBMが提供する統合開発環境のWebSphere Studio Application Developer(WSAD)です。WSADはWebSphereでのWebアプリケーションを構築するための統合開発環境で、XMLエクステンダーの開発を支援するためのプラグインも搭載しています。このプラグインを利用すると、Wizard形式で簡単にDADファイルを作成することができます。 わざわざWSADを使うのはちょっと…という向きには、DAD Checking Toolがオススメです。これはIBMのサイト(英語)からダウンロードできる無料のツールで、DADファイルの記述について論理的な誤りがないかを確認できます。今回のサンプル作成で筆者も実際に利用しましたが、RDB_Node Mapping記述のデバッグに効力を発揮してくれました。皆さんもXMLエクステンダーを実際に利用される場合は、併せて使ってみてください。 |
(1)結果表の準備
それではまず、コレクションからXML文書の合成を行ってみましょう。このXML文書の合成操作は、XMLエクステンダーに用意されているストアドプロシージャを呼び出すことにより実行します。このストアドプロシージャはコレクションにおいて最も上位のテーブルをスキャンし、行ごとにXML文書を合成します。
ここで、合成された文書を格納するための「結果表」が必要になります。この結果表は、文書を格納するためのカラムをもったテーブルであり、合成に先立って用意しておく必要があります。ここでは、documentというXMLVARCHARのカラムを1つだけもった結果表result_tab1およびresult_tab2を作成しておきます。それぞれ、コレクションdepartment1およびdepartment2用のものです。
create table result_tab1 (document
DB2XML.XMLVARCHAR) |
create table result_tab2 (document
DB2XML.XMLVARCHAR) |
結果表には、合成した文書を格納するための、VARCHAR、CLOB、XMLVARCHARもしくはXMLCLOBのいずれかの型のカラムが存在する必要があります。
(2)XML文書の合成
XML文書を合成するためのストアドプロシージャは、DB2XML.dxxRetrieveXMLです。呼び出しのインターフェイスはリスト8のようになっています。
dxxRetrieveXML(
|
| リスト8 DB2XML.dxxRetrieveXMLのインターフェイス |
ここでのポイントは、コレクション名、結果表の名前の2つです。それ以外のパラメータは、今は適当に指定しておけばよいでしょう。少し悩むところが出力変数の部分ですが、コマンド行プロセッサ(CLP)から呼び出す場合は“?”を指定しておけば問題ありません。図4に、コレクションdepartment1およびdepartment2についてXML文書を合成する例を示しておきます。
|
|
| 図4 dxxRetrieveXMLの実行例 |

合成した文書は、結果表のdocumentカラムに格納されています。これをSELECTすれば内容は確認できるはずですが、ここではカラムの内容をファイルにエクスポートする関数DB2XML.Contentを利用してファイルに書き出してみます。
|
|
| (本来は1行です) |
deptnoの値を用いてファイル名を作成し、C:\sampleディレクトリ以下にファイルを作成しています。
(3)XML文書の分解
次はXML文書を分解して、コレクションにデータを格納してみましょう。これは、RDB_Node Mappingを利用したコレクションでのみ可能です。XML文書を分解するためのストアドプロシージャは、DB2XML.dxxInsertXMLです。呼び出しのインターフェイスはリスト9のようになっています。
dxxInsertXML( |
| リスト9 DB2XML.dxxInsertXMLのインターフェイス |
リスト10のようなXML文書newdept.xmlを実際に分解してみましょう。
<?xml version="1.0"?> |
| リスト10 分解するXML文書のサンプル(newdept.xml) |
実行例は図5のようになります。
|
|
| 図5 dxxInsertXMLの実行例 |

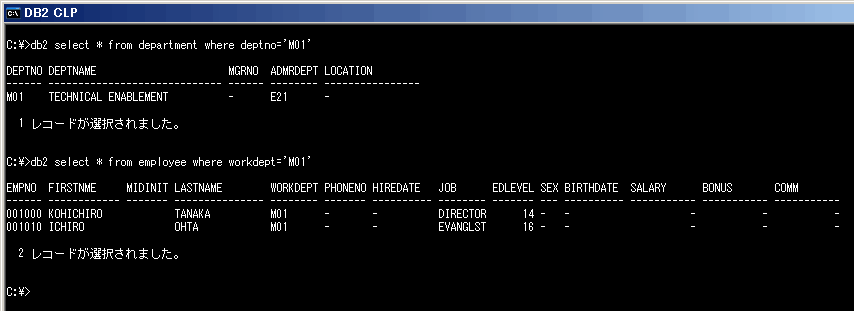
分解できたかどうかは、DEPARTMENT表とEMPLOYEE表の内容をSELECTしてみれば確認できます(図6)。
|
|
| 図6 分解により格納された行を確認する(画像をクリックすると全体を表示します) |
■最後に
今回は前回紹介したXML Collectionの利用手順を踏まえ、サンプルデータベースに含まれるテーブルをCollectionとして操作する例を紹介しました。1対多の参照関係にある複数のテーブルのデータをXML文書として合成する、または逆に、XML文書の内容を複数のテーブルのデータに分解する、この2つの操作の概要についてお分かりいただけたでしょう。
システム間でのデータ交換フォーマットとしてXML文書を用いるような場合、XMLとRDBMSのデータマッピングの実装が不可欠になってきます。このような処理をコーディングレスで実現できてしまうXML Collectionの有効性については、あらためて説明するまでもないでしょう。ぜひ実際に使って、その効果を確認してみてください。
◆
次回は、DB2におけるXMLサポート機能の目玉ともいえる、Web Service機能について紹介したいと思います。お楽しみに!
| <<前回へ | 「Webサービス機能を徹底検証する」 |
| Index | |
| 連載:DB2でXMLを操作する | |
| (1) XMLの格納方法を2種類備えるDB2 | |
| (2) DB2 UDBのインストールと動作確認 | |
| (3) XML Columnを使うための設計・実装 | |
| (4) XML ColumnにDocBook文書を格納する | |
| (5) XML Collectionを使うための設計・実装 | |
| (6) XML Collectionでデータマッピングを実現 | |
| (最終回) Webサービス機能を徹底検証する | |
- QAフレームワーク:仕様ガイドラインが勧告に昇格 (2005/10/21)
データベースの急速なXML対応に後押しされてか、9月に入って「XQuery」や「XPath」に関係したドラフトが一気に11本も更新された - XML勧告を記述するXMLspecとは何か (2005/10/12)
「XML 1.0勧告」はXMLspec DTDで記述され、XSLTによって生成されている。これはXMLが本当に役立っている具体的な証である - 文字符号化方式にまつわるジレンマ (2005/9/13)
文字符号化方式(UTF-8、シフトJISなど)を自動検出するには、ニワトリと卵の関係にあるジレンマを解消する仕組みが必要となる - XMLキー管理仕様(XKMS 2.0)が勧告に昇格 (2005/8/16)
セキュリティ関連のXML仕様に進展あり。また、日本発の新しいXMLソフトウェアアーキテクチャ「xfy technology」の詳細も紹介する
|
|





