Diggのリコメンデーションエンジンを使ってみた:「あなたに6%似た人」からのオススメをリストアップ
英語圏で人気のソーシャル・ブックマークサイト、「Digg.com」(ディグ)は先週末の7月1日、ユーザーに対してお勧めコンテンツを提示するレコメンデーション・エンジンをベータ版サービスとして公開した。
Diggのサービスは、ネット上のブログやニュースのURLをユーザーらが“ストーリー”として投稿し、コメントを投稿し合うことで成り立っている。ストーリーを気に入ったユーザーは「digg it」ボタンを押すことで、人気投票に参加する。テクノロジ、ビジネス、サイエンスなど各ジャンルで人気の高いものは刻々と「popular」(人気)に並べられる(ちなみに、サービス名のdiggは「気に入る」を意味する俗語のdigをもじったもの。digは「掘る」という意味だが、若者言葉で好きを意味する。過去形はdug。diggの場合はduggになる)。
Diggは、日々世界中で生み出される膨大な情報から、有用なものをすくい上げるサービスとして人気だ。個々のユーザーは「digg it」ボタンを押すことで、後から情報を探しやすくなる一方、そうした個々のユーザーの小さな投票によって有意義な情報処理ができる。Web 2.0のお手本のようなサービスだ。
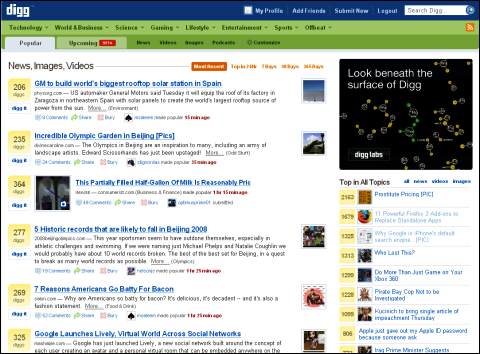 人気ソーシャル・ブックマークサイト「Digg.com」1日に1万数千件の“ストーリー”が投稿される
人気ソーシャル・ブックマークサイト「Digg.com」1日に1万数千件の“ストーリー”が投稿される 投稿されたストーリーで「digg it!」(気に入った)ボタンを押すことで、一種の人気投票に参加できる
投稿されたストーリーで「digg it!」(気に入った)ボタンを押すことで、一種の人気投票に参加できるレコメンデーション・エンジンとは
2004年に立ち上がったDiggは、もともとテクノロジ好きな人々がテクノロジ関連の情報を集めるサービスとして人気だった。しかし、2006年にジャンルを複数に分けてタブを設けたことで投稿されるストーリーの幅が広がった。今では政治ネタ、芸能ネタも人気ジャンルとなっている。
もともと「見るべき情報だけ」を拾い上げるシステムだったはずのDiggだが、現在は1日に1万2000〜1万5000以上の投稿があり、もはやすべてのタイトルに目を通すことはできなくなっている。
こうした事情から導入されたのが、ユーザーが気に入りそうなストーリーを統計処理によって選んで提示するレコメンデーション・エンジンだ。
レコメンデーション・エンジンは、すでにいろいろなところで使われている。オンラインストアのアマゾンを使ったことのある人なら、例えばRubyの本を買ったとたんにトップページにRuby関連の本がずらずら並ぶという経験をしたことあるに違いない。0歳児向けの絵本を買うと、オムツが表示されて驚くようなこともある。
アマゾンのレコメンデーション・エンジンの仕組みは明らかにされていないが、ユーザーの閲覧や購買の履歴からさまざまな統計処理を行っていると言われている。
シンプルで透明性の高い処理
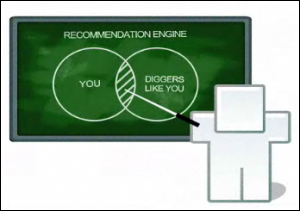 Diggのレコメンデーション・エンジンでは、嗜好の似たユーザー同士の類似性をベースにしているという(図はDigg.comから引用)
Diggのレコメンデーション・エンジンでは、嗜好の似たユーザー同士の類似性をベースにしているという(図はDigg.comから引用)Diggのレコメンデーション・エンジンは、透明性の高い、比較的シンプルなアルゴリズムで動いている。「魔法のような秘密の仕組みで、さあこれがオススメですよ、という提示の仕方はしない」。そう話すのは、同社リードサイエンティストでレコメンデーション・エンジン導入を行ったアントン・キャスト(Anton Kast)氏だ。多くのWebサイトでレコメンデーション・エンジンの仕組みは非公開であるのに対して、Diggではホワイトペーパーで動作原理を説明しているほか、キャスト氏のインタビュー動画も公開している。
Diggでユーザーが何か特定のストーリーを“digg”すると、それと同じストーリーをdiggしたユーザー群と関連付けられる。同じストーリーをdiggしたユーザーたちは、似たような好みを持つと考えられる。レコメンデーション・エンジンは、「Diggers Like You」(あなたに似たdiggユーザー)としてユーザー同士の類似度を計算する。類似度は、単純に2ユーザーの共通digg数を全digg数で割った0から1の数値となるという。
類似度が高いユーザーがdiggしたストーリーは、たとえ絶対数でdigg数が低くても、オススメである可能性が高い。たくさんdiggすればするほど精度は上がる。同じ1人のユーザーでも、ジャンルが違えば嗜好が異なることもある。Linuxが好きなユーザー同士であっても、セレブのゴシップや政治の話では好みが違うかも知れない。このため、レコメンデーション・エンジンが提示するストーリーはジャンルごとに計算されるのだという。
統計処理の対象となるのはユーザーの過去30日間のdigg情報だけと限定的だが、数百万人規模のユーザーコミュニティで、各ユーザーのアクションをリアルタイムに反映するのは「技術的に大きなチャレンジだった」(キャスト氏)という。一般的なリレーショナル・データベースは使わず、カスタムの“グラフ・データベース”を設計した。バッチ処理はしていないという。
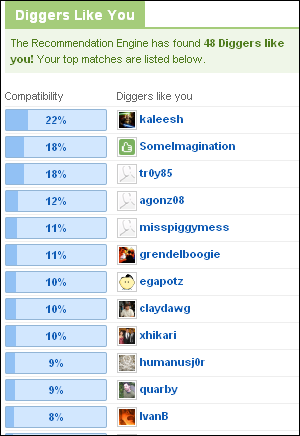 記者と似通ったストーリーをdiggしたという「Diggers Like You」(あなたに似たdiggユーザー)のリスト
記者と似通ったストーリーをdiggしたという「Diggers Like You」(あなたに似たdiggユーザー)のリスト少しの活動履歴で高い効果
早速、使ってみた。利用は簡単で、ログインしていくらかdiggした後(1つか2つでも機能する)、新しく導入された「Upcoming」というタブをクリックするだけだ。
実は記者はDiggをそれほど熱心に使っておらず、ずっと以前にいくつかコメントを投稿した以外は、ただ何となく眺めるか、いくつかのキーワードでフィルタをかけたRSSフィードを消化するだけという利用方法だった。
こうした限定的な利用法だったため、にわかにdiggしはじめてもあまり効果はないものかと想像していたのだが、実際に使ってみると、レコメンデーション・エンジンが非常に効果的なツールであることが分かった。
まず、ふれこみ通りに1日1万数千件のストーリーは数百件レベルに抑えられた。具体的には、過去数日間で30件ちょっとdiggしただけで1万5959件のストーリーから123件のオススメを提示してくれる。やや意図的に関連記事をdiggした面もあるのだが、いま気になっているiPhone関連のストーリーが、まだdigg数が伸びる前の段階で続々と拾い上げられるようになった。
リコメンドされたストーリーには、自分と類似度が何パーセントのユーザーがdiggしたかという数値がすべて表示されている。また、各ユーザー名をクリックすると、実際にいくつのdiggが共通しているのかも表示される。
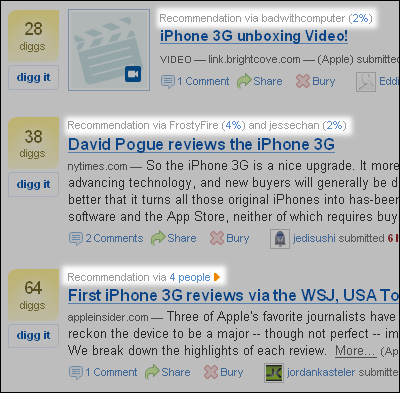 それぞれのストーリーが、誰と誰がdiggしたことでユーザーのレコメンデーションのリストに入ってきているかも分かりやすく表示している
それぞれのストーリーが、誰と誰がdiggしたことでユーザーのレコメンデーションのリストに入ってきているかも分かりやすく表示している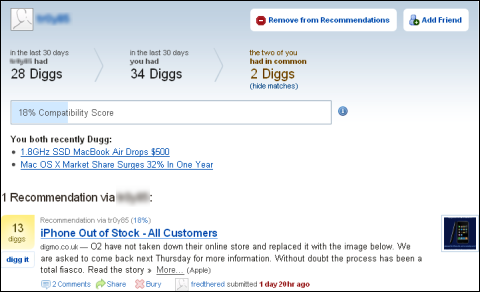 2ユーザーの類似度を示す画面。過去30日で、それぞれ約30のストーリーをdiggし、そのうち2つがMac関連で重なっていた。そのために、このユーザーがdiggしたiPhoneの在庫情報に関するストーリーが、レコメンデーションのリストに入ってきているのが分かる
2ユーザーの類似度を示す画面。過去30日で、それぞれ約30のストーリーをdiggし、そのうち2つがMac関連で重なっていた。そのために、このユーザーがdiggしたiPhoneの在庫情報に関するストーリーが、レコメンデーションのリストに入ってきているのが分かるDiggのレコメンデーション・エンジンはコンテンツの内容はまったく見ていないという。文字列やキーワードベースの処理をしているわけではないので、まったく未知の新語が出てきても対応できるだろう。いまiPhoneに関心のあるユーザーの大部分は、Android端末が発売されれば敏感に反応して、それが記者のレコメンデーションリストにも入ってくるだろう。レコメンデーション・エンジンを使うメリットは、キーワード登録が不要で、単に使い込めばいいだけという点にありそうだ。
関連記事
- 日本発のソーシャルアノテーション「コモンズ・マーカー」公開 (@ITNews)
- ソーシャルブックマークの未来は受動型? 自動型? (@ITNews)
- 人と繋がりにくい(!?)ソーシャルブックマーク登場 (@ITNews)
- 技術者向けソーシャル・ノウハウサイト「okyuu.com」が開設 (@ITNews)
- 社内でもソーシャルブックマーク、「Choix」の企業版登場 (@ITNews)
- 純国産のソーシャルアドレス帳「Ripplex」のすごいところ (@ITNews)
- Yahoo!ブックマークがリニューアル (@ITNews)
関連リンク
Copyright © ITmedia, Inc. All Rights Reserved.
注目のテーマ




人気記事ランキング
- 江崎グリコ、基幹システムの切り替え失敗によって出荷や業務が一時停止
- Microsoft DefenderとKaspersky EDRに“完全解決困難”な脆弱性 マルウェア検出機能を悪用
- 生成AIは2025年には“オワコン”か? 投資の先細りを後押しする「ある問題」
- 「欧州 AI法」がついに成立 罰金「50億円超」を回避するためのポイントは?
- 「Copilot for Securityを使ってみた」 セキュリティ担当者が感じた4つのメリットと課題
- 日本企業は従業員を“信頼しすぎ”? 情報漏えいのリスクと現状をProofpointが調査
- AWSリソースを保護するための5つのベストプラクティス CrowdStrikeが指南
- トレンドマイクロが推奨する、長期休暇前にすべきセキュリティ対策
- VMwareが「ESXi無償版」の提供を終了 移行先の有力候補は?
- Javaは他のプログラミング言語と比較してどのくらい危険なのか? Datadog調査
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。