「コードの読まれ方が分かった」、工数見積もり精度向上に寄与:奈良先端科学技術大学院大学 森崎修司氏らが発表
「ソースコードの読まれ方の傾向がまた1つ明らかになった。これで派生開発、保守開発の工数見積もりの精度が向上する」――奈良先端科学技術大学院大学 森崎修司助教らの研究グループは、2009年9月〜11月にかけて行ったソースコードリーディングのオンライン・ハンズオン、2010年1月、2月に行ったイベント「ソースコードリーディングワークショップ」、ほか3回におけるハンズオンの分析結果を発表した。
総計126人に、保守/派生開発プロジェクトを模した形式で複数のソースコードを読んでもらい、それぞれにかかった時間を計測、分析したところ、「ソースコードの読解時間はソースコードの行数だけで予測することは難しい」「大規模な変更の場合、コードレビューの経験があるとソースコードの読解時間を短縮できる」ことなどが明らかになったという。この分析結果について、森崎氏に詳しい話を聞いた。
126人分のソースコードの読解時間を分析
派生開発や保守開発では、既存のソースコードを理解し、整合性を保ったうえで機能の追加・修正を行う必要がある。その際、既存のソースコードより、機能の追加・修正分の方に目が行きがちであり、「追加・修正分の規模」だけで開発期間や工数を見積もってしまう傾向がある。
しかし、たとえ同じ規模の追加・修正でも、内容はそれぞれが異なる。開発をスムーズに進めていくためには、「追加・修正分の規模」だけではなく、既存ソースコードの理解に必要な知識や時間、既存ソースコードとの整合性を担保するうえで必要な手間、時間などを考慮に入れて、派生開発/保守開発の期間、工数を見積もる必要がある。
そこで今回、以前からこの問題に着目し、工数見積もりに関する研究活動に取り組んできた森崎氏らの研究グループは、2010年1月に東京・三田で行った「ソースコードリーディングワークショップ」などで実施したハンズオンの結果を基に、“ソースコードの読まれ方”を分析。「工数見積もりの精度向上に役立つ複数の傾向」や、「(開発者の)経験によるソースコード読解時間の傾向」を明らかにした。この結果について、森崎氏は次のように概観する。
 奈良先端科学技術大学院大学 森崎修司氏
奈良先端科学技術大学院大学 森崎修司氏「今回は、日本IBMと共催した2つのワークショップ――東京・三田におけるワークショップと、2010年2月に東京・目黒で行われた『デベロッパーズサミット2010』でのワークショップ――と、ソフトウェア開発企業3社でのハンズオンの結果を合わせて、総計126人によるソースコード読解の結果を分析対象とした。当初のもくろみ通り、プログラミング経験が3年以内の人、それ以上の人がバランスよく参加してくれたお陰で、分析結果に普遍性、正確性を担保できたと思う。この結果は、派生/保守開発の工数見積もりの精度向上をはじめ、開発者のスキルアップに大きく寄与する。また、レビュー時に『このソースコードを読むのにかける時間は本当にこの程度で良いのか』という“作業の妥当性”――すなわち“品質担保の根拠”としても役立つと思う。ぜひ多くの開発現場で活用してほしい」
 分析は博士前期課程の3人の学生とともに行った。写真左から西薗和希氏、吉岡俊輔氏、田口雅裕氏
分析は博士前期課程の3人の学生とともに行った。写真左から西薗和希氏、吉岡俊輔氏、田口雅裕氏「追加、修正行数だけによる工数見積もりは難しい」を実証
今回、分析対象としたハンズオンは次のように行った。まず、既存ソフトウェアに当たる「バージョン1」のソースコードと、保守・派生開発の開発部分に当たる計13個の差分(パッチファイル)を用意。「バージョン1」のソースコードの読解にかかった時間を各参加者に記録してもらったほか、差分を読解したうえで「その変更を適用しても問題がないか否か」、判断理由を回答してもらうとともに、判断までにかかった時間を記録してもらった。ソースコードにはJavaで書かれたペイントアプリケーションを使用した。
この結果、大きく2つの傾向が明らかになった。1つは「差分におけるコードの分量だけでは、読解時間の見積もりができない場合がある」こと(論文『類似の差分の比較によるソースコードの特徴と読解時間の関係の分析』[西薗和希、森崎修司、松本健一/平成22年度情報処理学会関西支部大会]で発表)。
「例えば、13個の差分のうち、6番と12番の差分では、12番の方がコードの行数が多い。にも関わらず、参加者は12番より、6番の読解に時間が掛かっていた。これは『差分の量だけではなく内容によっても工数が変わる』ことを裏付けている」。
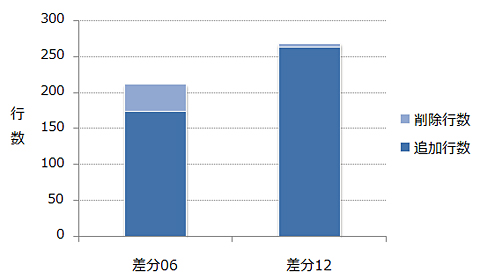 6番と12番の差分では、12番の方がコードの行数が多い
6番と12番の差分では、12番の方がコードの行数が多いというのも今回、6番の差分には定義クラス外を参照する「publicメソッド/変数」にかかわる変更を多く含ませ、12番の変更内容は、ほぼすべて定義クラス内しか参照しない「privateメソッド/変数」にかかわるものとしたのだという。つまり「変更に当たって、定義クラス外のさまざまな箇所を参照しなければならない差分の方が、読み込むのに時間や手間が掛かるということだ」。
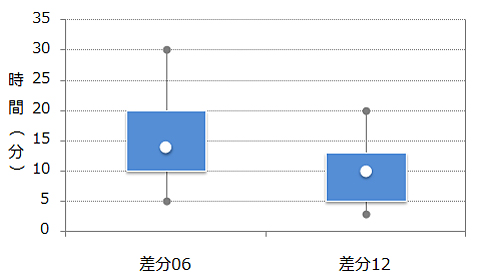 読解時間は、コード行数は少なくても、定義クラス外を参照する「publicメソッド/変数」を多く含んだ6番の方が多かった。変更に当たって、定義クラス外のさまざまな箇所を参照しなければならない差分の方が、読み込むのに時間や手間が掛かる、すなわち「追加、修正の行数だけで工数見積もりは難しい」ことを表している
読解時間は、コード行数は少なくても、定義クラス外を参照する「publicメソッド/変数」を多く含んだ6番の方が多かった。変更に当たって、定義クラス外のさまざまな箇所を参照しなければならない差分の方が、読み込むのに時間や手間が掛かる、すなわち「追加、修正の行数だけで工数見積もりは難しい」ことを表している特にpublicメソッド/変数は、場合によっては全クラスに目を通さなければ「適用して問題ないか否か」判断が難しいケースもある。よって森崎氏は、「規模だけではなく『定義クラス外を参照するメソッド/変数はいくつあるのか』『変更にかかわる各メソッド/変数は、それぞれ何カ所を参照しているのか』も考慮に入れて工数を見積もる方が正確だ。母体となるソースコードがあり、それに追加、変更をするタイプのプロジェクトの見積もりでは、こうした方法は特に効くはずだ」と指摘する。
さらに、「定義クラス外を参照するメソッド/変数はいくつあるのか」「変更にかかわる各メソッド/変数は、それぞれ何カ所を参照しているのか」を把握しておけば、「差分を適用して問題ないか否か」を判断するに当たり、「判断にかける時間は本当にこのくらいで十分なのか」を考える基準――すなわち「レビュー時間の妥当性を測る根拠(品質担保の根拠)にもなる」と付け加える。
小変更には“知識”が、大変更には“知識と経験”がモノを言う
2つ目は「対象ソースコードを扱うための知識を事前に学習しておくと、読解が早くなる」ということだ(論文『ソースコード理解に求められる知識が読解時間に与える影響の実験的評価』[田口雅裕、森崎修司、松本健一/平成22年度情報処理学会関西支部大会]と、論文『開発経験によるソースコード読解時間の影響分析』[吉岡俊輔、森崎修司、松本健一]/同支部大会]で発表)。
これは専門知識が求められるGUIプログラムを使い、「その経験があると読みやすいが、ないと読解に時間がかかる差分」を使って分析を行った。具体的には、参加者の属性に基づいて、「GUIプログラミング経験なし/レビュー経験なし」「GUIプログラミング経験が豊富/レビュー経験なし」「GUIプログラミング経験なし/レビュー経験が豊富」「GUIプログラミング経験が豊富/レビュー経験も豊富」という4グループで読解時間を比較。その結果、「GUIプログラミング経験が多い人は、GUIの知識が必要な差分の読解時間が短い」ことが分かった。
 「対象プログラムの規模が大きくなると、知識だけでは対応できない。『いかにレビューに慣れているか』も重要なファクターとなる」と森崎氏
「対象プログラムの規模が大きくなると、知識だけでは対応できない。『いかにレビューに慣れているか』も重要なファクターとなる」と森崎氏ただ森崎氏は、「GUIプログラミング経験のみが豊富でも、行数が多い差分については時間がかかることも分かった」と付け加える。
「すなわち、対象プログラムの規模が大きくなると、“知識だけでは対応できない”ということだ。これは対象プログラムの規模が大きな場合、『いかにレビューに慣れているか』も重要なファクターとなることを表している」
また、「参加者の経験」と「差分の難しさ」「変更の種類」によって読解時間が異なる、という結果も得られた。例えば、プログラミング経験が多い場合には「複雑なロジックのソースコードを読解する時間が短い」「リファクタリングが適切かどうかを判断するための時間が短い」などの傾向が明らかになった。
森崎氏はこれらの結果から、「スキルアップ、作業効率アップのためには、ソースコードを闇雲に読み込むのではなく、事前に対象プログラムに関する知識を仕入れておくと効率的。特に規模の小さなものほど、知識だけで読解時間を短縮できる可能性が高い」と指摘。また、「対象プログラムと各開発者のプロフィールに応じて、規模の小さなものは『対象プログラムの経験が豊富/レビュー経験なし』の人に、ロジックが複雑なものや規模の大きなものは『対象プログラム経験が豊富/レビュー経験も豊富』な人に任せると良いだろう」と役割分担にも有効であることをアドバイスする。
“機能は特別でも、作りはシンプル”を目指そう
以上の分析結果の詳細は、森崎氏の研究グループのWebサイト「ソースコードリーディングワークショップ ハンズオン,オンラインハンズオン結果中間報告 1」(http://se.naist.jp/events/srw2010/report1.html)に掲載されている。森崎氏は「このデータをより多くの人に活用してもらい、ぜひ作業効率向上と個人のスキルアップに役立ててほしい」と語る。
一方で、こうしたデータはアプリケーション開発ベンダや、自社開発を行っているユーザー企業にとっても有益な情報となることは間違いない。特にクラウド化が加速すれば、開発やバージョンアップには高品質を担保しながらさらなるスピードが求められる。
この点について森崎氏は、「今回、『参照されている個所が多い部分は、読解に時間がかかる』という結果が得られた。こうした“結合度”や“カップリング”の高さによる問題は以前より指摘されてきたが、今回のデータからも読解に時間がかかることが明らかになった。機能間の依存を減らし、独立性の高いコードを書くことを心掛けることで開発効率が高くなる」と提案する。
このほかにも、「なるべく汎用的な仕組みや共通のコードを流用し、特殊なロジックを極力ひとまとめにする」などアプローチはさまざまあるが、「個別性の高い機能や業務に対して、システムやソフトウェアまで完全に個別に作る必要はない」と指摘。
「どこまでは汎用的なもの、共通部分でカバーでき、どこからを個別に対応するのか――“機能/業務とシステムの対応”を整理して、依存関係の少ない、極力シンプルな方向を目指すことが大切だ」と述べ、開発やその後の派生/保守開発のスピードと品質、コストの問題を両立するためには“設計フェーズからの配慮”が重要であることを示唆した。
関連記事
- すぐに使えるソースコードの読み方を指南(@ITNews)
- 日本初!? コードレビューのスキル・ベンチマークを作成(@ITNews)
- “レビュー”とは、責め合うものではなく、品質を高め合うもの(@ITNews)
- レビューを「数」だけで管理しているからコストが膨らむ(@IT情報マネジメント)
関連リンク
Copyright © ITmedia, Inc. All Rights Reserved.
注目のテーマ




人気記事ランキング
- 生成AIは検索エンジンではない 当たり前のようで、意識すると変わること
- VPNやSSHを狙ったブルートフォース攻撃が増加中 対象となる製品は?
- “脱Windows”が無理なら挑まざるを得ない「Windows 11移行」実践ガイド
- 大田区役所、2023年に発生したシステム障害の全貌を報告 NECとの和解の経緯
- ランサムウェアに通用しない“名ばかりバックアップ”になっていませんか?
- 標的型メール訓練あるある「全然定着しない」をHENNGEはどう解消するのか?
- HOYAに1000万ドル要求か サイバー犯罪グループの関与を仏メディアが報道
- 爆売れだった「ノートPC」が早くも旧世代の現実
- 「Gemini」でBigQuery、Lookerはどう変わる? 新機能の詳細と利用方法
- 攻撃者が日本で最も悪用しているアプリは何か? 最新調査から見えた傾向
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。