検索エンジンの常識をApache Solrで身につける:ビッグデータ処理の常識をJavaで身につける(1)(1/4 ページ)
Hadoopをはじめ、Java言語を使って構築されることが多い「ビッグデータ」処理のためのフレームワーク/ライブラリを紹介しながら、大量データを活用するための技術の常識を身に付けていく連載
全文検索エンジンと「Apache Solr」
現在、多くのWebサービスには検索窓が付いています。ユーザーは検索窓に検索クエリを発行することで、そのWebサービスが保持する文書集合から興味のある文書を入手できます。
このような検索機能を実現するために、Webページのバックエンドでは、「全文検索エンジン」が動いて、ユーザーが発行したクエリにヒットする(クエリを含む)文書集合の場所(URLなど)をユーザーに返しています。
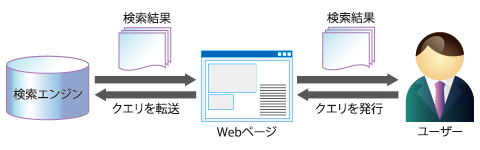 図1 検索サービス
図1 検索サービス本稿では、まず(全文)検索エンジンとその周辺技術についてお話しします。その後「Apache Solr(ソーラー)」(以下、Solr)というオープンソースの検索エンジンの利用方法について簡単に解説します。SolrはJava言語で書かれた検索エンジンで国内外の大規模検索サービスで利用実績を持ちます。
検索エンジンで利用する主な手法
検索エンジンは、ユーザーが発行する検索クエリに対して高速に結果を返す必要があります。現在までに高速な検索を実現するための手法がいくつか提案されてきました。
最も単純な手法は、クエリ発行後、検索対象の文書1つ1つが「クエリ単語」を含んでいるのかチェックするものです。この手法は非常に簡単に実装でき(単純には「grep」コマンドで実装できます)便利ですが、クエリ発行後に対象文書集合を走査するため、「対象となる文書の数が大きくなると、検索に時間がかかり過ぎる」という問題があります。
インデックス
これに対し、「インデックス」を利用すると、大量の文書集合を高速に検索できます。ここでいうインデックスは「どの文書が、どの単語を含むのか」という情報を保存するテーブルです。ユーザーがクエリを発行した際、インデックスを持つ検索エンジンは自身のインデックスを調べてクエリ単語を含む文書集合を返します。
インデックスを利用することで、クエリを含む文書を収集する時間を短縮できます。インデックスを利用した検索システムと全文書のコンテンツを走査する検索システムを比較すると、多くの場合インデックスを利用した検索システムの方が高速に動作します。
また、検索対象となる文書数(量)が大きくなっても、検索性能はそれほど劣化しません(注:正確には検索エンジンを保持する計算機のメモリ量とインデックスの大きさなどに依存します)。
そのため、大規模データを扱う高負荷な環境では、インデックスの利用が「ほぼ必須」といえます。
インデックスのデータ構造には、いくつか種類があります。その中でも「転置インデックス」(※1)が特に有名です。その他にも「接尾辞配列」(※2)をインデックスとして利用した検索エンジンも存在します。以下の節で転置インデックスについて説明します。
- ※1[Knuth, 1997] Donald Knuth, The Art of Computer Programming, Volume 3: Sorting and Searching, Third Edition. Addison-Wesley, 1997.
- ※2[Manber and Myers, 1991] Udi Manber and Gene Myers (1991). "Suffix arrays: a new method for on-line string searches". SIAM Journal on Computing, Volume 22, 1993.
転置インデックス
転置インデックスは各単語と単語を含む文書IDからなるテーブルです(注:実際には単語が文書の中で出現した位置情報を含む場合が多いのですが、本稿では割愛します)。
例えば、2つの英語の文書(Doc 1,Doc2)があり、そのコンテンツがそれぞれ「I love Emacs」「I prefer Vim to Emacs」であったとします。このとき、以下の表のような転置インデックスを生成します。説明に利用する転置インデックスは「連想配列」というデータ構造で実装でき(注:連想配列でない実装もあります)、単語をキーにして文書ID のリストを返します。
| 単語 | 文書IDリスト |
|---|---|
| I | 1,2 |
| love | 1 |
| Emacs | 1,2 |
| prefer | 2 |
| Vim | 2 |
| to | 2 |
| 表 転置インデックスの例 | |
表のような転置インデックス完成後は、クエリに対する結果を返す処理は簡単です。例えば、ユーザーが「Vim」というクエリを発行すると、検索エンジンは「Vim」を含む文書IDリストを返します。表では文書IDの「2」を返します。
検索エンジンを取り巻く7つの技術
検索エンジンのコア技術は前節で紹介したインデックスです。しかし実際に、検索インデックスだけで構成する検索エンジンから、検索サービスを構築するには多大なコストが掛かります。以下の節で検索エンジンを利用したシステム、検索サービスを構築する際に便利なコンポーネントを紹介します。
これらの機能のいくつかは、多くの検索エンジンが組み込んでいます。一方で、簡素な検索エンジンは、以下で紹介するコンポーネントをサポートしていないため、ユーザーが独自に開発するか、その機能を持つコンポーネントを組み込む必要があるものもあります。
【1】トークナイザ
検索エンジンに文書をインデックスするには、入力文書内の文を単語に分割する必要があります。この作業を行うのが「トークナイザ」というコンポーネントです。トークナイザには、入力文書を単語(形態素)に区切る「単語単位」ものと「(文字)N-gram」の2種類があります。
- 単語単位のトークナイザ
まず「単語単位のトークナイザ」(注:「形態素解析器」というツールを指す)についてお話しします。先ほどの例で扱った文書は英語だったので、各単語間にスペースが入っていました。そのため、各単語を取り出すのは簡単です。ところが、日本語や中国語は各単語の切れ目にスペースが入っていないため、転置インデックスを生成する前に文から単語を切り出す必要があります。
例えば、「私は国会議事堂に行きました」という文書を単語単位のトークナイザで処理すると、「"私","は","国会議事堂","に","行き","ました"」という単語列を出力します。これらの単語をインデックスしておくことで、ユーザーが「国会議事堂」というクエリを発行した際、「国会議事堂」という単語を含む文書を返せます。
ただし、単語単位のトークナイザを利用したインデックスには、有名な問題があります。それは「検索クエリにヒットしない」場合があるという点です。
例えば、先の一文からなる文書、「私は国会議事堂に行きました」をインデックスしたうえで「国会」というクエリをユーザーが発行した場合、文書はヒットしません。なぜなら「国会議事堂」という部分を「国会」「議事堂」という2単語としてインデックスせずに、トークナイザが「国会議事堂」を1つの単語として出力したためです。
このようにトークナイザが単語を大きく切り出してしまったがために、検索結果に出てきてほしい単語がヒットしないという状況があります。この問題を避けるために、商用のトークナイザの中には単語を細かく分割する機能や単語の中の部分単語を出力する機能を提供しているものがあります。また、以下で紹介します「N-gramトークナイザ」を利用することで、この問題を解決できます。
- (文字)N-gram トークナイザ
N-gramトークナイザを利用してインデックスを作ることで単語ベースのトークナイザで起こった「検索クエリにヒットしない」という問題を解決できます。N-gram では文を「n-文字」単位に分割して(オーバーラップを含む)インデックスします。
例えば2文字単位(バイグラム)で「国会議事堂」を分割すると「"国会","会議","議事","事堂"」となります。このようにN-gramを利用すると、「国会議事堂」という単語を含む文書は「国会」という部分文字列をインデックスするため、ユーザーがクエリ「国会」で検索した際、無事検索結果を返せます。
しかし、N-gramには「検索にヒットしてほしくない文書が含まれる」という問題があります。例えば「国会議事堂」を含む文をN-gramでインデックスしたとします。残念なことにユーザーが発行する「会議」というクエリの検索結果に、この文書も含まれてしまいます。これは「国会議事堂」が「"国会","会議","議事","事堂"」のように「会議」を含む2文字組(2-gram)に分割してしまったからです。
さらに、N-gramインデックスはトークナイザインデックスよりもインデックスのサイズが大きくなる傾向があります。結果、同一の文書集合で単語ベースのトークナイザとN-gramでインデックスを生成した場合には、単語ベースの方が検索性能(スピード)が良好な傾向があります。
- 単語単位+(文字)N-gram トークナイザ
検索エンジンによっては両者の合わせ技的な方法も使えます。具体的には、単語ベースと文字N-gramの両方のインデックスを生成する機能です。この機能によって、「N-gramインデックスでクエリ単語を含む(ヒットする)文書集合を集め、トークナイザインデックスでヒットした検索結果にランキングを行う」という処理が実現できます。
次ページでは、検索エンジンを取り巻く技術残り6つについて解説した後、検索エンジンの主な利用方法について紹介します。
Copyright © ITmedia, Inc. All Rights Reserved.




![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。