|
|
性能トラブルを未然に防止する
「Systemwalker」のキャパシティ管理
──安心・安全なIT全般統制とは? |
2007年9月30日、金融商品取引法が全面施行となった。2008年4月1日開始事業年度より財務報告にかかる内部統制の経営者評価および監査の制度が適用されており、上場企業では内部統制への取り組みの一環としてIT統制への対応が進められている。
しかし、その対策が十分できていると断言できる企業は少数派だ。ITILに基づいた安心・安全な運用管理を提供する富士通の「Systemwalker」は、安定稼働の評価を含めて企業のシステム運用管理を強力に支援する。今回はその中でもシステムの安定性確保でカギとなる「キャパシティ管理」について紹介する。 |
| |
|
システムは、動いてさえいればいいというわけではない |
 |
いわゆる「日本版SOX法」が求める内部統制システムは、「IT統制」を要件の1つとしている。IT統制は一般に業務プロセスに対する統制である「業務処理統制」と、それを支えるシステムインフラに対する統制である「全般統制」に分類される。この全般統制──IT全般統制は、業務プロセスに対する統制を担保するものであり、最も基本となる部分だといえる。
 |
| 富士通株式会社 ソフトウェア事業本部 ミドルウェア事業統括部 第二ミドルウェア技術部 プロジェクト課長 堀江隆一氏 |
富士通株式会社 ソフトウェア事業本部 プロジェクト課長の堀江隆一氏は、IT全般統制を「企業がITシステムを効果的に活用して、運用が健全かつ有効に行われていること」と位置付けたうえで、これからはシステム運用をきちんと評価し、その健全性や有効性を説明できることが大切だと主張する。
「従来、運用管理というのは安定稼働していることが重要でした。具体的にはトラブルが発生したら、それをいち早く察知して即応するというアプローチです。それに対して私たちの『Systemwalker』は、ITILに基づいた安心・安全な運用管理でIT運用の有効性を示すものです。つまり、目に見えるトラブルが発生しているか否かというよりも、システムが決められたとおり、ちゃんと動いているということを示すという点を重視しているわけです」(堀江氏)
「Systemwalker」は、IT全般統制の評価項目のうち「システムの安全性の確保」「システムの運用・管理」「システムの開発、変更・保守」を支援する。例えばシステムの安全性の確保では、「運用ルールの策定・見直し」「セキュリティ対策」「対策状況のチェック」「問題行動への対応」のPDCAサイクルを回して、システムが安全かどうかをチェック・分析する。このように、常にPDCAサイクルを回していきながら、システムの安定性・安全性を高めていくソリューションを提供するのが富士通の「Systemwalker」なのだ。
| |
|
「キャパシティ管理」でトラブルを未然防止 |
|
システムの安定稼働を実現するためにはさまざまな統制要素があるが、性能の観点からの評価──すなわち「キャパシティ管理」は非常に重要な要素の1つだ。
システムの運用現場では、新しいシステムや機能を追加・導入したときにパフォーマンス低下が発生したり、時間を経るごとにしだいにシステム性能が劣化したりということがしばしば起こる。そのような性能情報を監視・分析し、評価するのが「Systemwalker Service Quality Coordinator(SQC)」だ。
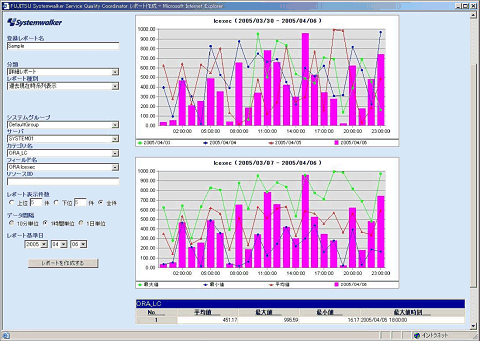 |
| Systemwalker Service Quality Coordinator |
キャパシティ管理で大切なのは、トラブルの兆候を事前に予見することである。これを見逃すと対応が遅れ、リスクが顕在化して、エンドユーザーの怒りを買うことになってしまう。それに対する統制活動は、システム性能に影響を及ぼすさまざまなITリソースを常時監視し、異常があれば適切な予防対策を立案・実施することだ。その第1段階は“異常”を判断する基準の策定である。
SQCでは各性能指標に「しきい値」を設定し、それを超えていないかをモニタリングする。日中のトランザクションと夜間のバッチなど、稼働状況に合わせたしきい値が設定可能だ。検知したサービスレベルの低下は「Systemwalker Centric Manager」で一元管理できるため、監視画面から問題のあったサーバのモニタ画面をドリルダウンで直接呼び出すことができる。
性能トラブルは、明らかな故障や障害以上にやっかいなものだ。今日のシステムはご存じのように、Webサーバ/アプリケーションサーバ/データベースと多階層化し、ハードウェア、ネットワーク、システムソフトウェア、アプリケーションもそれぞれ非常に複雑化している。このため「どこで問題が起こっているのか」をなかなか発見しにくい状況にある。特にキャパシティ問題は、トラブルを再現しようとしても、システムを問題発生時と同じ状態にするのは至難の業という面がある。
それだけに性能情報を日ごろから記録し、それを分析できるような仕組みが極めて重要だ。具体的なトラブルが発生していなくても、日ごろから“評価”を続けることでトラブルの予兆を感じ取り、対応できる。そうしたマネジメント・プロセスが大切なのだ。
| |
|
しきい値監視では見つけられないシステムの不調も
「基準値比較」で発見 |
|
SQCの大きな特長に「基準値比較による分析」機能がある。しきい値は「○%を超えたら異常」というような固定的な値として設定されるが、基準値は日々の稼働状況の中で変化する値だ。
一般にしきい値は“明らかな異常値”として設定される。余裕を持たせて、“少し危険かもしれない”ぐらいの値に設定すると管理コンソールがアラートばかりになってしまい、本当に対処しなければならない緊急のアラートが分からなくなってしまうからだ。例えば、「毎月25日の締め日にはAサーバへのアクセスが集中する」場合、そのピークを前提にしきい値を決めてしまうと、ほかの日の異常に気がつかないということになる。
これに対して基準値は、日々正常に動作しているときのCPU負荷やメモリ使用量などの値だ。つまり、“いつもの値”と現状のシステムの稼働状況と比較して、突如おかしな値が出たときにそれを察知するというわけだ。
 |
| SQCの基準値比較による分析。基準値に対して、時間ごとの値に有意な差が見られる場合に警告を発する |
このような小さな異変をいち早く、とらえることができれば、エンドユーザーから苦情が出る前に情報システム部門が先手を打ち、対処できるはずだ。それこそが究極のITサービスだといえよう。それに加え、「システムが問題なく動いていること」をきちんとレポートすることがこれからのIT統制では重要なのだ。
次回は、性能トラブルの早期切り分けや分析・予測に基づく投資の最適化、およびSystemwalkerを使った具体的な事例を紹介していこう。
提供:富士通株式会社
企画:アイティメディア 営業局
制作:@IT 編集部
掲載内容有効期限:2007年12月31日 |

