GoogleのMapReduceアルゴリズムをJavaで理解する:いま再注目の分散処理技術(前編)(1/2 ページ)
最近注目を浴びている分散処理技術「MapReduce」の利点をサンプルからアルゴリズムレベルで理解し、昔からあるJava関連の分散処理技術を見直す特集企画(編集部)
いま注目の大規模分散処理アルゴリズム
最近、大規模分散処理が注目を浴びています。特に、「MapReduce」というアルゴリズムについて目にすることが多くなりました。Googleの膨大なサーバ処理で使われているということで、ここ数年の分散処理技術の中では特に注目を浴びているようです(参考「見えるグーグル、見えないグーグル」)。MapReduceアルゴリズムを使う利点とは、いったい何なのでしょうか。なぜ、いま注目を浴びているのでしょうか。
その詳細は「MapReduce : Simplified Data Processing on Large Clusters」というタイトルの論文で「Google Research Publications : MapReduce」から参照できるので、調べてみました。MapReduceを理解するためのサンプルプログラムをJavaで実装して、その利点を探ってみましょう。
お題【文章で使用されている英字をカウントする】
「文章で使用されている英字をカウントする」プログラムを通して、MapReduceを理解してみましょう。例えば、ある英語の文章から、各英字がどれくらい使われているのかを計算したい場合を考えてみましょう。説明を単純にするために、英字以外の文字が入力された場合のエラー処理などは考えていません。読者なら、どんなプログラムを作るでしょうか?
単純にプログラムを書くと、以下のようになります。
*** 一部省略されたコンテンツがあります。PC版でご覧ください。 ***
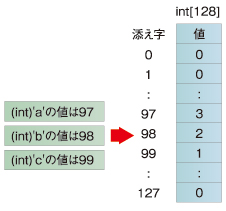
ポイントとしては、あらかじめ各文字をカウントする結果を格納する配列を用意しておいて、文字列を先頭から読んで、文字単位でカウントアップをしています。charCountは一種のハッシュテーブル(連想配列、キーとなる文字列と値をセットで保存できるデータ)です。「英字のbyte値やchar値」をキーとして、対応する値を参照したり格納したりしています。
ハッシュ関数は「英字のbyte値やchar値」を「int型の整数値」に変換するだけなので、わざわざ関数にはせずに、「int index = (int)b;」とか、「int index = (int)c;」のようにしています。
*** 一部省略されたコンテンツがあります。PC版でご覧ください。 ***
では、これを分散処理で実行するためには、どうすればいいでしょうか?
MapReduceアルゴリズムで実装すると……
「文章で使用されている英字をカウントする」プログラムをMapReduceアルゴリズムで実装してみましょう。
分散処理をどのように実行するかも気になりますが、MapReduceアルゴリズムを利用する場合は、まずは「自分が実行させたい処理をどのように実現すればいいのか」という点から理解していくのが早道です。ここでは分散処理そのものではなく、分散処理されるプログラムがどういうものかを理解することに主眼を置くことにします。
■Mapで分散処理&Reduceでまとめ処理
MapReduceの論文では、図2のようなシステムを構築して実行する方法について報告がされています。
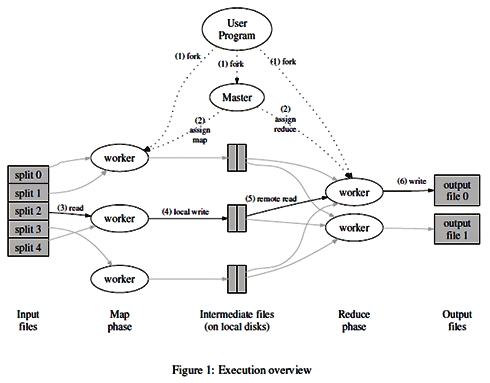
図2を見て分かるように、入力データを分割して「Map処理」を行うプログラムで分散処理をさせ、その結果を「Reduce処理」を行うプログラムへ渡して、そちらも分散処理をしています。分散処理を行うプログラムを開始したり停止したりする制御やデータ入出力の同期といったことは「Masterプログラム」が行っています。先ほども述べましたが、本稿ではMasterプログラムの詳細については考えず、MapフェイズとReduceフェイズで動作するプログラムがどういったものなのかを中心に説明をします。
■MapReduce処理サンプルの実行本体「MapReduceCharCounterApp」クラス
まず、次のようなMapReduceCharCounterAppクラスを作成することにします。先ほどのSimpleWordCounterクラスの代わりにMapReduceCharCounterクラスを使っているだけです。
*** 一部省略されたコンテンツがあります。PC版でご覧ください。 ***
このプログラムを見て分かるように、MapReduceCharCounterクラスでは、count()メソッドとgetCharCount()メソッドを持ちます。
■値を保持する「MapEntry」クラス
MapReduceCharCounterクラスから説明をしてもいいのですが、アルゴリズムの説明上、まずはMapEntryクラスというものを用意するところから説明をします。このクラスでは、keyとなる文字と、keyと対応する値であるvalueを保持する単純なものです。単純化のため、アクセッサメソッドは使っていません。
MapEntryオブジェクトについてはソートをする必要があるので、Comparableインターフェイスを実装するようにしています。これを実装すると、equals()メソッドやhashCode()メソッドについても考慮が必要になります(Comparableの実装については、拙著「Javaコレクションフレームワーク」(ソフトバンククリエイティブ)などをご覧ください)。
*** 一部省略されたコンテンツがあります。PC版でご覧ください。 ***
次ページでは、引き続きMapReduceアルゴリズムのサンプルをJavaで実装し、MapReduceアルゴリズムを使う利点について述べます。
Copyright © ITmedia, Inc. All Rights Reserved.